
ComfyUI Extension: ComfyUI_LayerStyle_Advance
ComfyUI_LayerStyle_Advance is ready to run
It's one of 95 extensions already installed on ComfyICU — nothing to clone, nothing to reconcile. Bring a workflow and you're billed for GPU seconds, not idle time.
The nodes detached from ComfyUI Layer Style are mainly those with complex requirements for dependency packages.
Looking for a different extension?
Custom Nodes (77)
- LayerMask: BBox Join(Advance)
- LayerMask: Ben Ultra(Advance)
- LayerMask: BiRefNetUltra(Advance)
- LayerMask: BiRefNet Ultra V2(Advance)
- LayerMask: Draw BBox Mask(Advance)
- LayerMask: Draw BBox Mask V2(Advance)
- LayerMask: EVF-SAM Ultra(Advance)
- LayerMask: Florence2 Ultra(Advance)
- LayerMask: Human Parts Ultra(Advance)
- LayerMask: Load Ben Model(Advance)
- LayerMask: Load BiRefNet Model(Advance)
- LayerMask: Load BiRefNet Model V2(Advance)
- LayerMask: Load Florence2 Model(Advance)
- LayerMask: Load SAM2 Model(Advance)
- LayerMask: Load SegmentAnything Models(Advance)
- LayerMask: MaskByDifferent(Advance)
- LayerMask: Mediapipe Facial Segment(Advance)
- LayerMask: Object Detector Florence2(Advance)
- LayerMask: Object Detector Gemini(Advance)
- LayerMask: Object Detector Gemini V2(Advance)
- LayerMask: Object Detector Mask(Advance)
- LayerMask: Object Detector YOLO8(Advance)
- LayerMask: Object Detector YOLO World(Obsolete)
- LayerMask: PersonMaskUltra(Advance)
- LayerMask: PersonMaskUltra V2(Advance)
- LayerMask: SAM2 Ultra(Advance)
- LayerMask: SAM2 Ultra V2(Advance)
- LayerMask: SAM2 Video Ultra(Advance)
- LayerMask: SegmentAnythingUltra(Advance)
- LayerMask: SegmentAnythingUltra V2(Advance)
- LayerMask: SegmentAnythingUltra V3(Advance)
- LayerMask: Transparent Background Ultra(Advance)
- LayerMask: YoloV8 Detect(Advance)
- LayerUtility: Add BlindWaterMark(Advance)
- LayerUtility: Collage(Advance)
- LayerUtility: Create QRCode(Advance)
- LayerUtility: Decode QRCode(Advance)
- LayerUtility: DeepSeek API
- LayerUtility: DeepSeek API V2
- LayerUtility: Florence2 Image2Prompt(Advance)
- LayerUtility: Gemini(Advance)
- LayerUtility: Gemini Image Edit(Advance)
- LayerUtility: Gemini V2(Advance)
- LayerUtility: GetColorTone(Advance)
- LayerUtility: GetColorTone V2(Advance)
- LayerUtility: ImageAutoCrop(Advance)
- LayerUtility: ImageAutoCrop V2(Advance)
- LayerUtility: ImageAutoCrop V3(Advance)
- LayerUtility: ImageRewardFilter(Advanced)
- LayerUtility: Jimeng Imgae to Image API (Advance)
- LayerUtility: JoyCaption2(Advance)
- LayerUtility: JoyCaption2 Extra Options(Advance)
- LayerUtility: JoyCaption2 Split(Advance)
- LayerUtility: JoyCaption Beta One (Advance)
- LayerUtility: JoyCaption Beta One Extra Options(Advance)
- LayerUtility: LaMa(Advance)
- LayerUtility: Llama Vision(Advance)
- LayerUtility: Load JoyCaption2 Model(Advance)
- LayerUtility: Load JoyCaption Beta One Model (Advance)
- LayerUtility: Load PSD(Advance)
- LayerUtility: Load SmolLM2 Model(Advance)
- LayerUtility: Load SmolVLM Model(Advance)
- LayerUtility: Phi Prompt(Advance)
- LayerUtility: PromptEmbellish(Advance)
- LayerUtility: PromptTagger(Advance)
- LayerUtility: QWenImage2Prompt(Advance)
- LayerUtility: SaveImage Plus(Advance)
- LayerUtility: SaveImagePlus V2(Advance)
- LayerUtility: SD3 Negative Conditioning(Advance)
- LayerUtility: Show BlindWaterMark(Advance)
- LayerUtility: SmolLM2(Advance)
- LayerUtility: SmolVLM(Advance)
- LayerUtility: UserPrompt Generator Replace Word(Advance)
- LayerUtility: UserPrompt Generator Txt2Img(Advance)
- LayerUtility: UserPrompt Generator Txt2Img with Reference(Advance)
- LayerUtility: ZhipuGLM4(Advance)
- LayerUtility: ZhipuGLM4V(Advance)
README
ComfyUI Layer Style Advance
The nodes detached from ComfyUI Layer Style are mainly those with complex requirements for dependency packages.
Example workflow
Some JSON workflow files in the workflow directory, That's examples of how these nodes can be used in ComfyUI.
How to install
(Taking ComfyUI official portable package and Aki ComfyUI package as examples, please modify the dependency environment directory for other ComfyUI environments)
Install plugin
-
Recommended use ComfyUI Manager for installation.
-
Or open the cmd window in the plugin directory of ComfyUI, like
ComfyUI\custom_nodes,typegit clone https://github.com/chflame163/ComfyUI_LayerStyle_Advance.git -
Or download the zip file and extracted, copy the resulting folder to
ComfyUI\custom_nodes
Install dependency packages
-
for ComfyUI official portable package, double-click the
install_requirements.batin the plugin directory, for Aki ComfyUI package double-click on theinstall_requirements_aki.batin the plugin directory, and wait for the installation to complete. -
Or install dependency packages, open the cmd window in the ComfyUI_LayerStyle plugin directory like
ComfyUI\custom_nodes\ComfyUI_LayerStyle_Advanceand enter the following command,
for ComfyUI official portable package, type:
..\..\..\python_embeded\python.exe -s -m pip install .\whl\docopt-0.6.2-py2.py3-none-any.whl
..\..\..\python_embeded\python.exe -s -m pip install .\whl\hydra_core-1.3.2-py3-none-any.whl
..\..\..\python_embeded\python.exe -s -m pip install -r requirements.txt
.\repair_dependency.bat
for Aki ComfyUI package, type:
..\..\python\python.exe -s -m pip install .\whl\docopt-0.6.2-py2.py3-none-any.whl
..\..\python\python.exe -s -m pip install .\whl\hydra_core-1.3.2-py3-none-any.whl
..\..\python\python.exe -s -m pip install -r requirements.txt
.\repair_dependency.bat
- Restart ComfyUI.
Download Model Files
Chinese domestic users from BaiduNetdisk or QuarkNetdisk , other users from huggingface.co/chflame163/ComfyUI_LayerStyle
download all files and copy them to ComfyUI\models folder. This link provides all the model files required for this plugin.
Or download the model file according to the instructions of each node.
Some nodes named "Ultra" will use the vitmatte model, download the vitmatte model and copy to ComfyUI/models/vitmatte folder, it is also included in the download link above.
Common Issues
If the node cannot load properly or there are errors during use, please check the error message in the ComfyUI terminal window. The following are common errors and their solutions.
Warning: xxxx.ini not found, use default xxxx..
This warning message indicates that the ini file cannot be found and does not affect usage. If you do not want to see these warnings, please modify all *.ini.example files in the plugin directory to *.ini.
ModuleNotFoundError: No module named 'psd_tools'
This error is that the psd_tools were not installed correctly.
Solution:
- Close ComfyUI and open the terminal window in the plugin directory and execute the following command:
../../../python_embeded/python.exe -s -m pip install psd_toolsIf error occurs during the installation of psd_tool, such asModuleNotFoundError: No module named 'docopt', please download docopt's whl and manual install it. execute the following command in terminal window:../../../python_embeded/python.exe -s -m pip install path/docopt-0.6.2-py2.py3-none-any.whlthepathis path name of whl file.
Cannot import name 'guidedFilter' from 'cv2.ximgproc'
This error is caused by incorrect version of the opencv-contrib-python package,or this package is overwriteen by other opencv packages.
NameError: name 'guidedFilter' is not defined
The reason for the problem is the same as above.
Cannot import name 'VitMatteImageProcessor' from 'transformers'
This error is caused by the low version of transformers package.
insightface Loading very slow
This error is caused by the low version of protobuf package.
For the issues with the above three dependency packages, please double click repair_dependency.bat (for Official ComfyUI Protable) or repair_dependency_aki.bat (for ComfyUI-aki-v1.x) in the plugin folder to automatically fix them.
onnxruntime::python::CreateExecutionProviderInstance CUDA_PATH is set but CUDA wasn't able to be loaded. Please install the correct version of CUDA and cuDNN as mentioned in the GPU requirements page
Solution:
Reinstall the onnxruntime dependency package.
Error loading model xxx: We couldn't connect to huggingface.co ...
Check the network environment. If you cannot access huggingface.co normally in China, try modifying the huggingface_hub package to force the use hf_mirror.
-
Find
constants.pyin the directory ofhuggingface_hubpackage (usuallyLib/site packages/huggingface_hubin the virtual environment path), Add a line afterimport osos.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
ValueError: Trimap did not contain foreground values (xxxx...)
This error is caused by the mask area being too large or too small when using the PyMatting method to handle the mask edges.
Solution:
- Please adjust the parameters to change the effective area of the mask. Or use other methods to handle the edges.
Requests.exceptions.ProxyError: HTTPSConnectionPool(xxxx...)
When this error has occurred, please check the network environment.
UnboundLocalError: local variable 'clip_processor' referenced before assignment
UnboundLocalError: local variable 'text_model' referenced before assignment
If this error occurs when executing JoyCaption2 node and it has been confirmed that the model file has been placed in the correct directory,
please check the transformers dependency package version is at least 4.43.2 or higher.
If transformers version is higher than or equal to 4.45.0, and also have error message:
Error loading models: De️️scriptors cannot be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
......
Please try downgrading the protobuf dependency package to 3.20.3, or set environment variables: PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python.
Update
**If the dependency package error after updating, please double clicking repair_dependency.bat (for Official ComfyUI Protable) or repair_dependency_aki.bat (for ComfyUI-aki-v1.x) in the plugin folder to reinstall the dependency packages.
- Fix the issue where Florence2 run with higher versions of Transformers, this solution comes from kijai, Thanks to @flybirdxx for feedback.
After updating plugin, findmodeling_florence2.pyandconfiguration_florence2.pyfrom theflorence2_modelsfolder, copy and overwrite them to the model folder inComfyUI/models/florence2. - Commit JimengImageToImageAPI node, edit images using the Instant Dreaming Image 3.0 API. Create an account on Volcano Engine and apply for API AccessKeyID and SecretAccessKey. Fill them into the
api_key.inidirectory in the plugin directory. - Commit SAM2UltraV2 and LoadSAM2Model nodes, Change the SAM model to an external input to save resources when using multiple nodes.
- Commit JoyCaptionBetaOne, LoadJoyCaptionBeta1Model, JoyCaptionBeta1ExtraOptions nodes, Generate prompt words using the JoyCaption Beta One model.
- Commit SaveImagePLusV2 node, add custom file names and setting up the dpi of image.
- Commit GeminiImageEdit node, support using gemini-2.0-flash-exp-image-generation API for image editing.
- Commit GeminiV2 and ObjectDetectorGeminiV2 nodes, used google-genai dependency package that supports the gemini-2.0-flash-exp and gemini-2.5-pro-exp-03-25 models.
- Add QuarkNetdisk model download link.
- Support numpy 2.x dependency package.
- Commit DeepseekAPI_V2 noee, supporting AliYun and VolcEngine API.
- Commit Collage node to collage images into one.
- Commit DeepSeekAPI node, Use DeepSeek API for text inference.
- Commit SegmentAnythingUltraV3 and LoadSegmentAnythingModels nodes, Avoid duplicating model loading when using multiple SAM nodes.
- Commit ZhipuGLM4 and ZhipuGLM4V nodes, Use the Zhipu API for textual and visual inference. Among the current Zhipu models, GLM-4-Flash and glm-4v-flash models are free.
Apply for an API key for free at https://bigmodel.cn/usercenter/proj-mgmt/apikeys, fill your API key in
zhipu_api_key=. - Commit Gemini node, Use Gemini API for text or visual inference.
- Commit ObjectDetectorGemini node, Use Gemini API for object detection.
- Commit DrawBBOXMaskV2 node, can draw rounded rectangle masks.
- Commit SmolLM2, SmolVLM, LoadSmolLM2Model and LoadSmolVLMModel nodes, use SMOL model for text inference and image recognition.
download the model file from BaiduNetdisk or huggingface and copy to
ComfyUI/models/smolfolder. - Florence2 add support gokaygokay/Florence-2-Flux-Large and gokaygokay/Florence-2-Flux models, download Florence-2-Flux-Large and Florence-2-Flux folder from BaiduNetdisk or huggingface and copy to ```ComfyUI\models\florence2`` folder.
- Discard the dependencies required for the ObjectDetector YOLOWorld node from the requirements. txt file. To use this node, please manually install the dependency package.
- Strip some nodes from ComfyUI Layer Style to this repository.
Description
<a id="table1">Collage</a>
Randomly collage the input images into one large image.
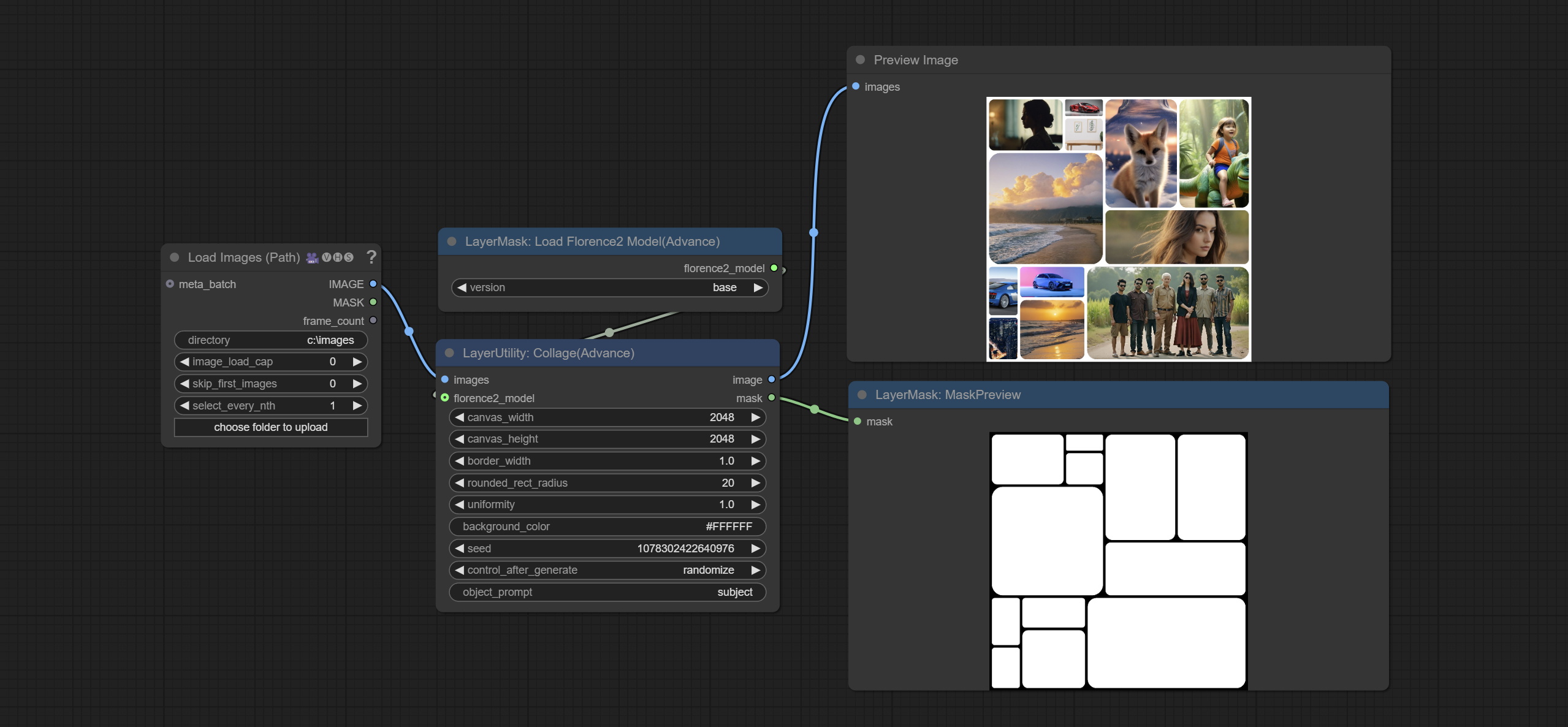
Node Options:
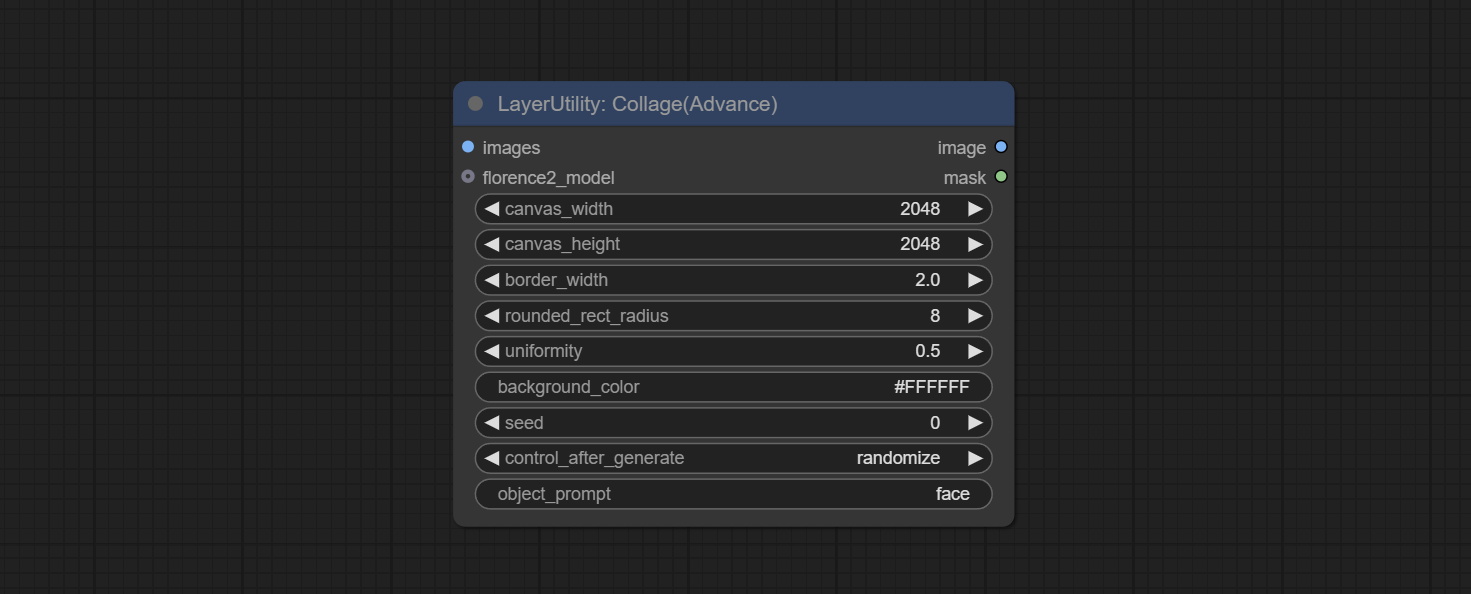
- Add multiple languages and increase support for 5 languages: Chinese, French, Japanese, Korean and Russian. This feature producted by ComfyUI-Globalization-Node-Translation, thank you to the original author.
- images: The input images.
- florence2_model: Optional input for object recognition and cropping.
- canvas_width: Output the width of the image.
- canvas_height: Output the height of the image.
- border_width: The border width.
- rounded_rect_radius: The border fillet radius.
- uniformity: The randomness of image stitching size. The value range is 0-1, and the larger the value, the greater the randomness of the size.
- background_color: The background color.
- seed: The seed of random number.
- control_after_generate: Seed change options. If this option is fixed, the generated random number will always be the same.
- object_prompt: When connecting to florence2_model, fill in the prompt words for object recognition here.
<a id="table1">QWenImage2Prompt</a>
Inference the prompts based on the image. this node is repackage of the ComfyUI_VLM_nodes's UForm-Gen2 Qwen Node, thanks to the original author.
Download model files from huggingface or Baidu Netdisk to ComfyUI/models/LLavacheckpoints/files_for_uform_gen2_qwen folder.
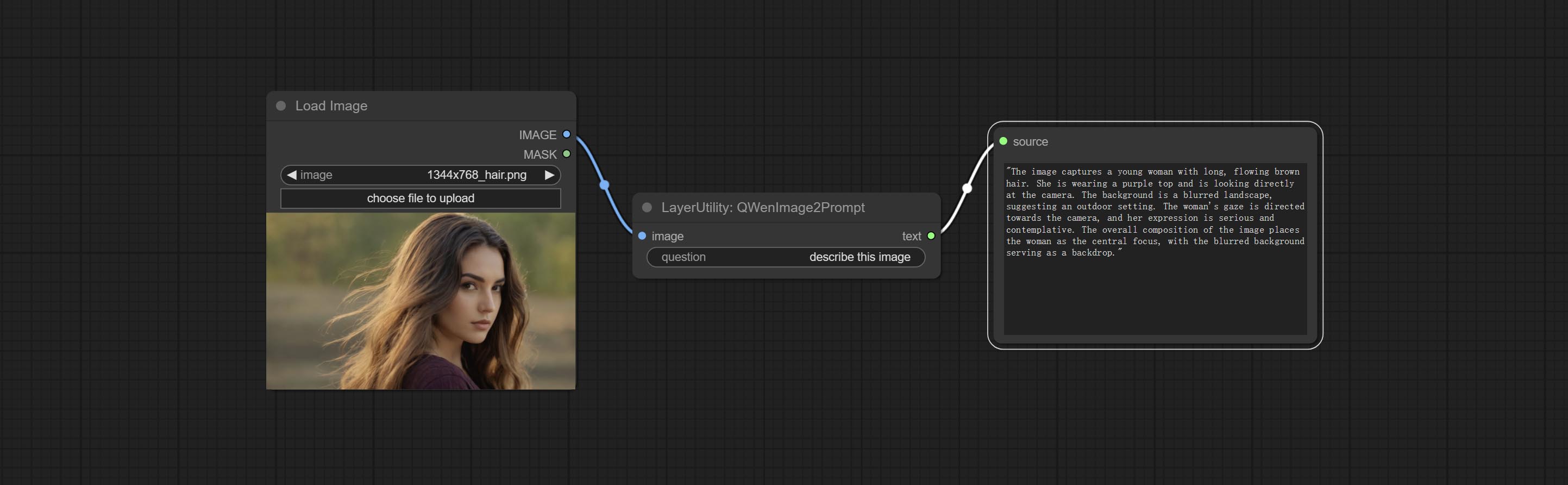
Node Options:
- question: Prompt of UForm-Gen-QWen model.
<a id="table1">LlamaVision</a>
Use the Llama 3.2 vision model for local inference. Can be used to generate prompt words. part of the code for this node comes from ComfyUI-PixtralLlamaMolmoVision, thank you to the original author.
To use this node, the transformers need upgraded to 4.45.0 or higher.
Download models from BaiduNetdisk or huggingface/SeanScripts , and copy to ComfyUI/models/LLM.
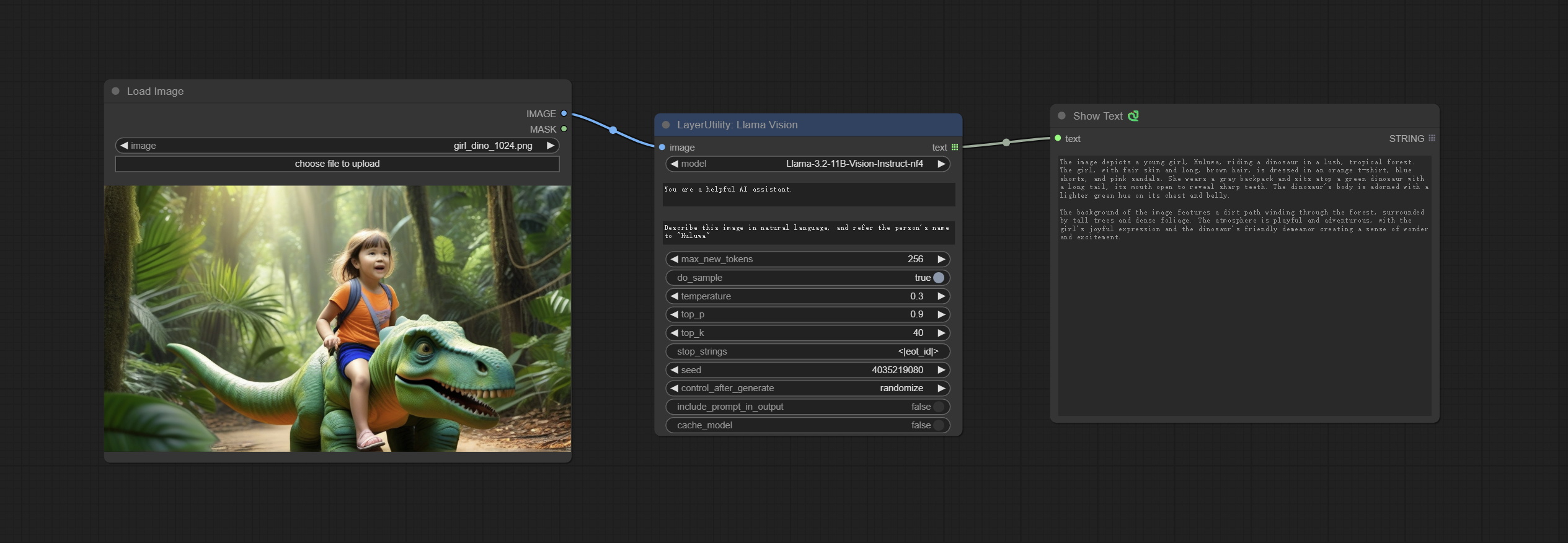
Node Options:
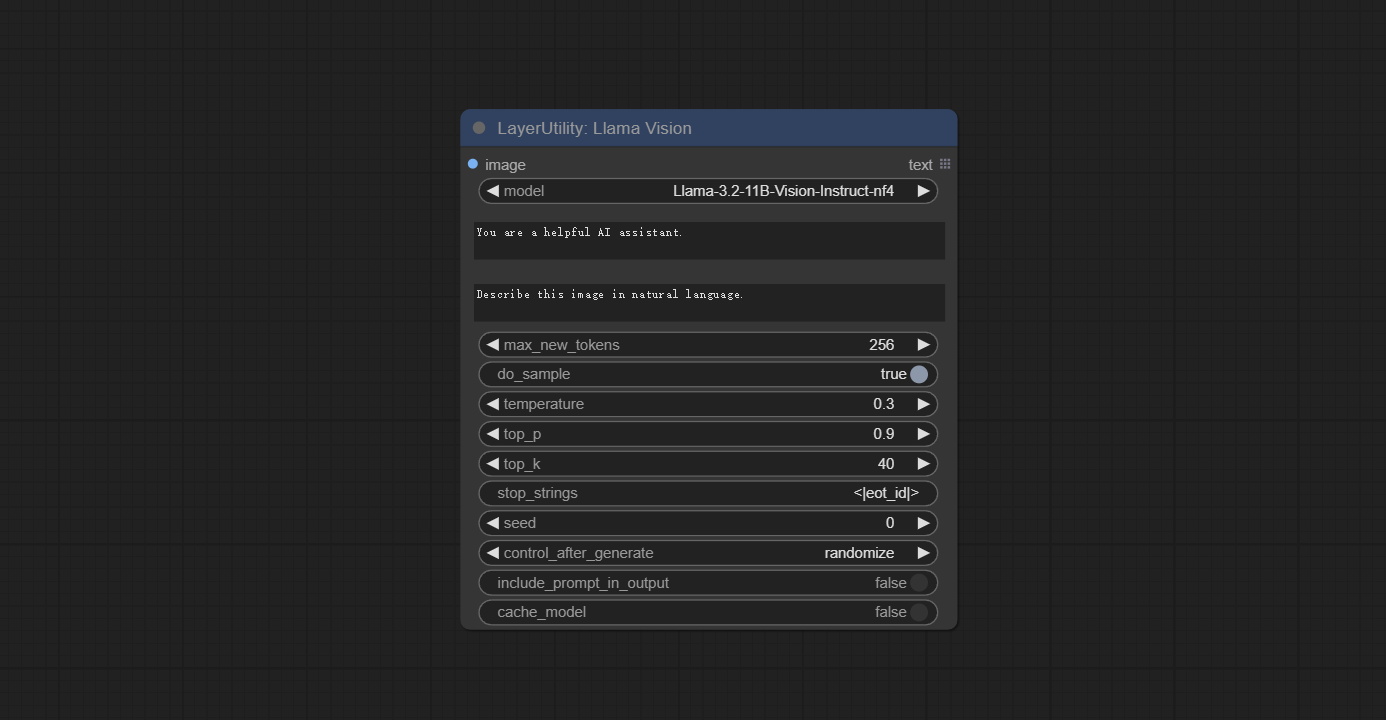
- image: Image input.
- model: Currently, only the "Llama-3.2-11B-Vision-Instruct-nf4" is available.
- system_prompt: System prompt words for LLM model.
- user_prompt: User prompt words for LLM model.
- max_new_tokens: max_new_tokens for LLM model.
- do_sample: do_sample for LLM model.
- top-p: top_p for LLM model.
- top_k: top_k for LLM model.
- stop_strings: The stop strings.
- seed: The seed of random number.
- control_after_generate: Seed change options. If this option is fixed, the generated random number will always be the same.
- include_prompt_in_output: Does the output contain prompt words.
- cache_model: Whether to cache the model.
<a id="table1">JoyCaption2</a>
Use the JoyCaption-alpha-two model for local inference. Can be used to generate prompt words. this node is https://huggingface.co/John6666/joy-caption-alpha-two-cli-mod Implementation in ComfyUI, thank you to the original author.
Download models form BaiduNetdisk and BaiduNetdisk ,
or huggingface/Orenguteng and huggingface/unsloth , then copy to ComfyUI/models/LLM,
Download models from BaiduNetdisk or huggingface/google , and copy to ComfyUI/models/clip,
Donwload the cgrkzexw-599808 folder from BaiduNetdisk or huggingface/John6666 , and copy to ComfyUI/models/Joy_caption。
Node Options:
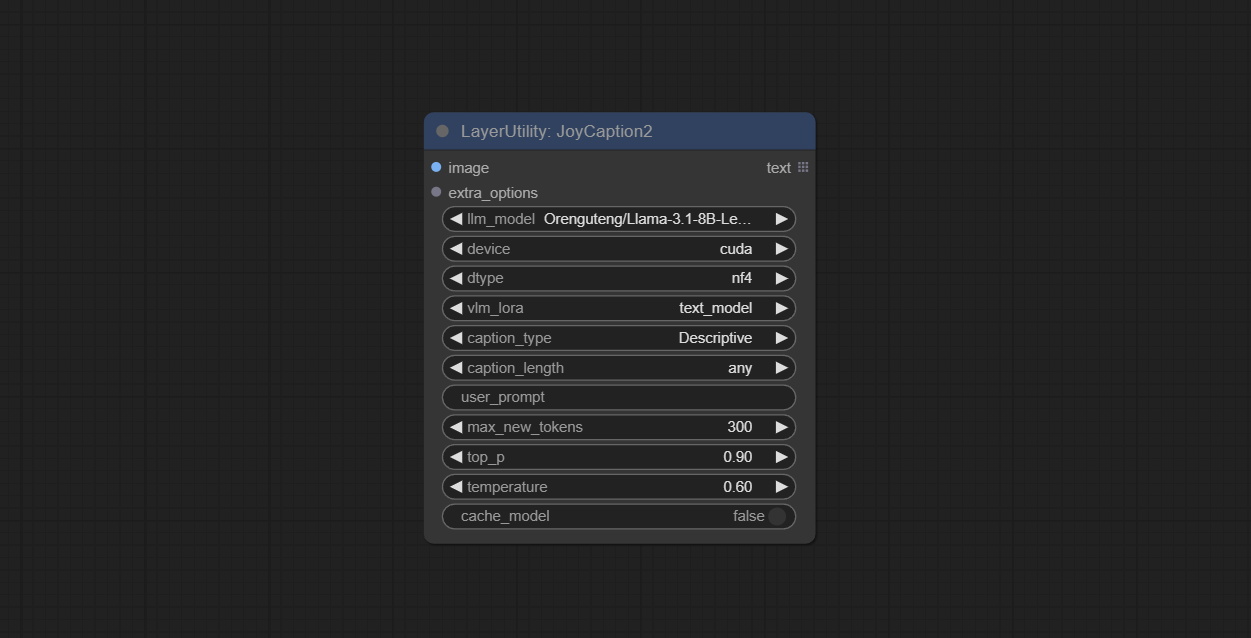
- image: Image input.
- extra_options: Input the extra_options.
- llm_model: There are two LLM models to choose, Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 and unsloth/Meta-Llama-3.1-8B-Instruct.
- device: Model loading device. Currently, only CUDA is supported.
- dtype: Model precision, nf4 and bf16.
- vlm_lora: Whether to load text_madel.
- caption_type: Caption type options, including: "Descriptive", "Descriptive (Informal)", "Training Prompt", "MidJourney", "Booru tag list", "Booru-like tag list", "Art Critic", "Product Listing", "Social Media Post".
- caption_length: The length of caption.
- user_prompt: User prompt words for LLM model. If there is content here, it will overwrite all the settings for caption_type and extra_options.
- max_new_tokens: The max_new_token parameter of LLM.
- do_sample: The do_sample parameter of LLM.
- top-p: The top_p parameter of LLM.
- temperature: The temperature parameter of LLM.
- cache_model: Whether to cache the model.
<a id="table1">JoyCaption2Split</a>
The node of JoyCaption2 separate model loading and inference, and when multiple JoyCaption2 nodes are used, the model can be shared to improve efficiency.
Node Options:
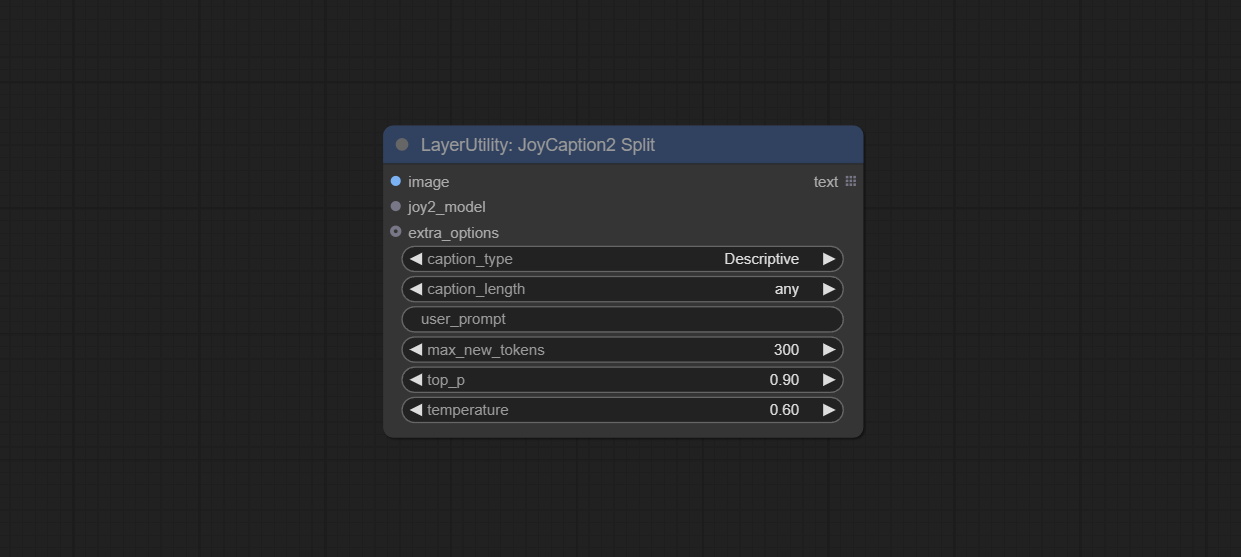
- image: Image input.
- joy2_model: The JoyCaption model input.
- extra_options: Input the extra_options.
- caption_type: Caption type options, including: "Descriptive", "Descriptive (Informal)", "Training Prompt", "MidJourney", "Booru tag list", "Booru-like tag list", "Art Critic", "Product Listing", "Social Media Post".
- caption_length: The length of caption.
- user_prompt: User prompt words for model. If there is content here, it will overwrite all the settings for caption_type and extra_options.
- max_new_tokens: The max_new_token parameter of model.
- do_sample: The do_sample parameter of model.
- top-p: The top_p parameter of model.
- temperature: The temperature parameter of model.
<a id="table1">LoadJoyCaption2Model</a>
JoyCaption2's model loading node, used in conjunction with JoyCaption2Split.
Node Options:
- llm_model: There are two LLM models to choose, Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 and unsloth/Meta-Llama-3.1-8B-Instruct.
- device: Model loading device. Currently, only CUDA is supported.
- dtype: Model precision, nf4 and bf16.
- vlm_lora: Whether to load text_madel.
<a id="table1">JoyCaption2ExtraOptions</a>
The extra_options parameter node of JoyCaption2.
Node Options:
- refer_character_name: If there is a person/character in the image you must refer to them as {name}.
- exclude_people_info: Do NOT include information about people/characters that cannot be changed (like ethnicity, gender, etc), but do still include changeable attributes (like hair style).
- include_lighting: Include information about lighting.
- include_camera_angle: Include information about camera angle.
- include_watermark: Include information about whether there is a watermark or not.
- include_JPEG_artifacts: Include information about whether there are JPEG artifacts or not.
- include_exif: If it is a photo you MUST include information about what camera was likely used and details such as aperture, shutter speed, ISO, etc.
- exclude_sexual: Do NOT include anything sexual; keep it PG.
- exclude_image_resolution: Do NOT mention the image's resolution.
- include_aesthetic_quality: You MUST include information about the subjective aesthetic quality of the image from low to very high.
- include_composition_style: Include information on the image's composition style, such as leading lines, rule of thirds, or symmetry.
- exclude_text: Do NOT mention any text that is in the image.
- specify_depth_field: Specify the depth of field and whether the background is in focus or blurred.
- specify_lighting_sources: If applicable, mention the likely use of artificial or natural lighting sources.
- do_not_use_ambiguous_language: Do NOT use any ambiguous language.
- include_nsfw: Include whether the image is sfw, suggestive, or nsfw.
- only_describe_most_important_elements: ONLY describe the most important elements of the image.
- character_name: Person/Character Name, if choice
refer_character_name.
<a id="table1">JoyCaptionBetaOne</a>
Generate prompt words using the JoyCaption Beta One model. This node is https://huggingface.co/fancyfeast/llama-joycaption-beta-one-hf-llava Implementation in ComfyUI.
The first time using the node, the model will be automatically downloaded to the ComfyUI/models/LLavacheckpoints/llama-joycaption-beta-one-hf-llava folder.
You can also download llama-joycaption-beta-one-hf-llava folder from BaiduNetdisk or Quark or huggingface/fancyfeast/llama-joycaption-beta-one-hf-llava and copy to ComfyUI/models/LLavacheckpoints
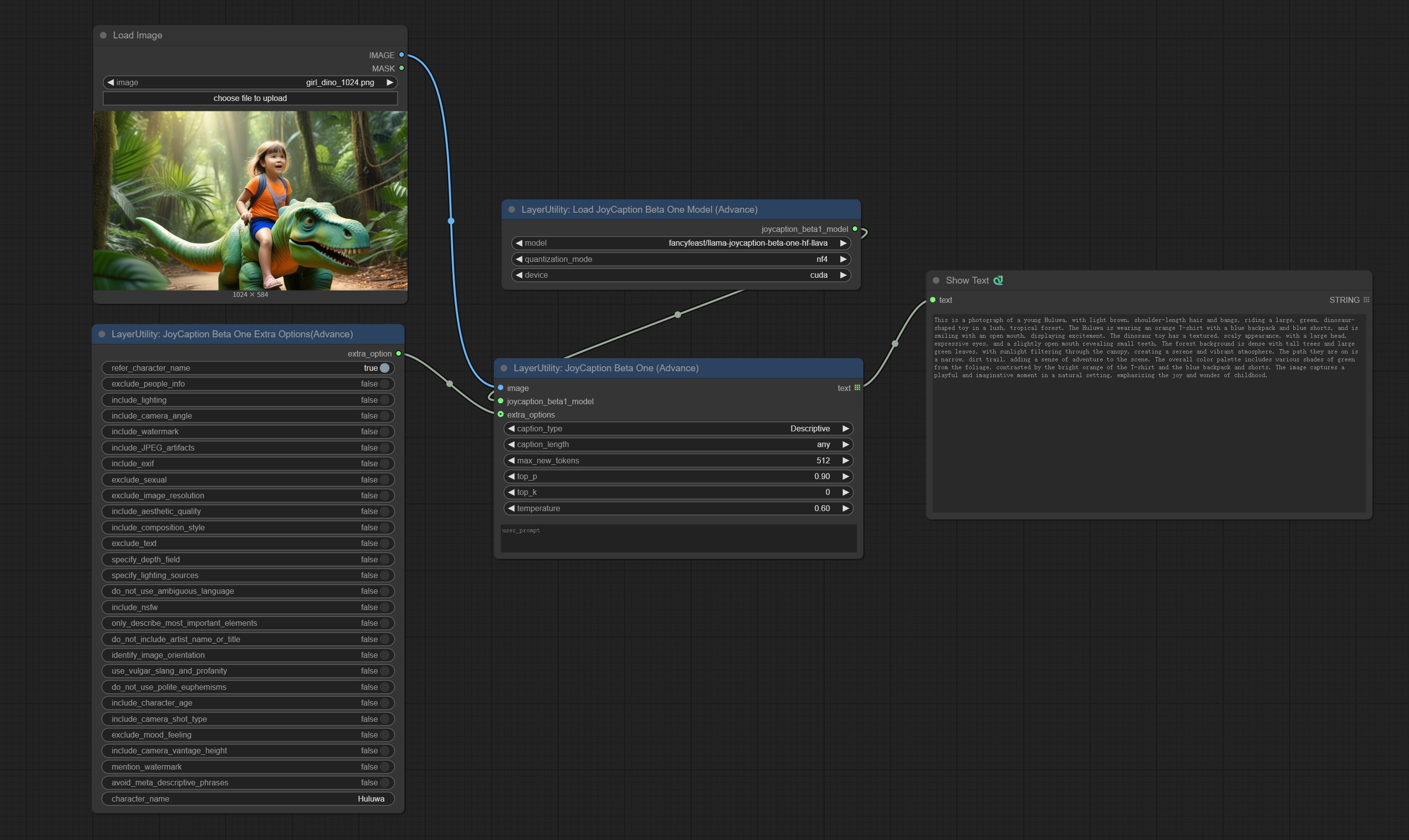
Node Options:
- image: Image input.
- joycaption_beta1_model: JoyCaption Beta One model input. The model is loaded from the
Load JoyCaption Beta One Modelnode. - extra_options: Input the extra_options.
- caption_type: Caption type options, including: "Descriptive", "Descriptive (Casual)", "Straightforward", "Stable Diffusion Prompt", "MidJourney", "Danbooru tag list", "e621 tag list", "Rule34 tag list", "Booru-like tag list", "Art Critic", "Product Listing" and "Social Media Post".
- caption_length: The length of caption.
- max_new_tokens: The max_new_token parameter of model.
- top-p: The top-p parameter of model.
- top-k: The top-k parameter of model.
- temperature: The temperature parameter of model.
- user_prompt: User prompt words for model. If there is content here, it will overwrite all the settings for caption_type and extra_options.
<a id="table1">LoadJoyCaptionBeta1Model</a>
The model loading node of JoyCaption Beta One, used in conjunction with JoyCaption Beta One.
Node Options:
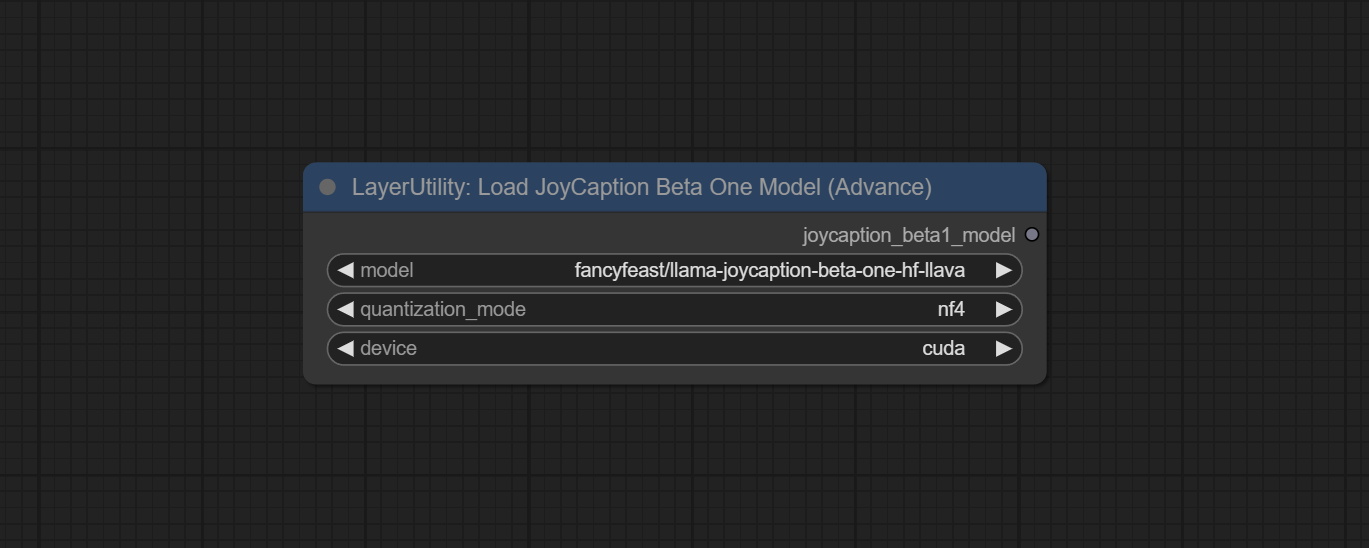
- model: Only the
fancyfeast/llama-joycaption-beta-one-hf-llavamodel is available for selection currently. - quantization_mode: The model quantization mode has three options: nf4, int8, and bf16.
- device: The model loading device.
<a id="table1">JoyCaptionBeta1ExtraOptions</a>
The extra_options parameter node of JoyCaption Beta One.
Node Options:
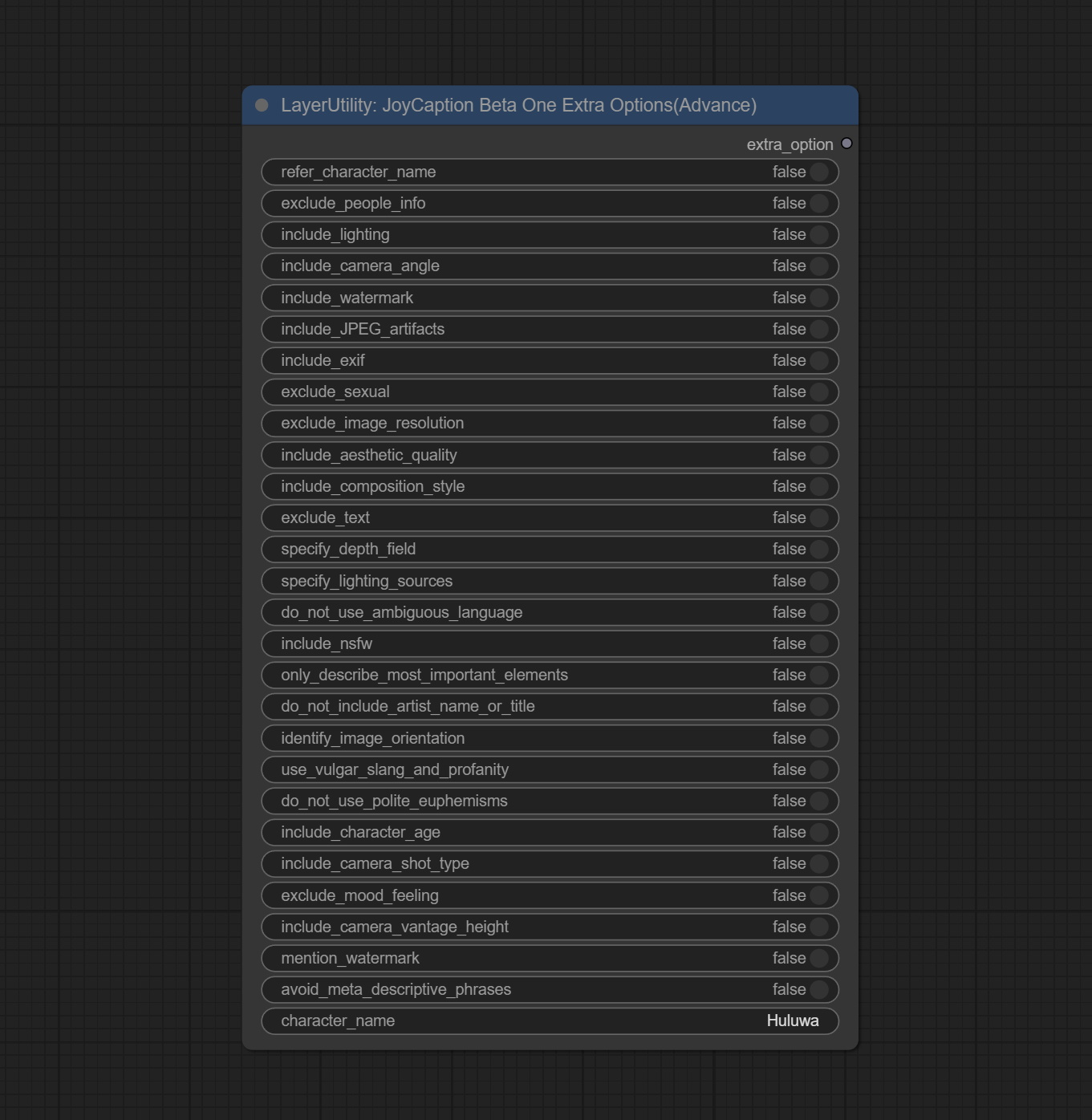
- refer_character_name: If there is a person/character in the image you must refer to them as {name}.
- exclude_people_info: Do NOT include information about people/characters that cannot be changed (like ethnicity, gender, etc), but do still include changeable attributes (like hair style).
- include_lighting: Include information about lighting.
- include_camera_angle: Include information about camera angle.
- include_watermark: Include information about whether there is a watermark or not.
- include_JPEG_artifacts: Include information about whether there are JPEG artifacts or not.
- include_exif: If it is a photo you MUST include information about what camera was likely used and details such as aperture, shutter speed, ISO, etc.
- exclude_sexual: Do NOT include anything sexual; keep it PG.
- exclude_image_resolution: Do NOT mention the image's resolution.
- include_aesthetic_quality: You MUST include information about the subjective aesthetic quality of the image from low to very high.
- include_composition_style: Include information on the image's composition style, such as leading lines, rule of thirds, or symmetry.
- exclude_text: Do NOT mention any text that is in the image.
- specify_depth_field: Specify the depth of field and whether the background is in focus or blurred.
- specify_lighting_sources: If applicable, mention the likely use of artificial or natural lighting sources.
- do_not_use_ambiguous_language: Do NOT use any ambiguous language.
- include_nsfw: Include whether the image is sfw, suggestive, or nsfw.
- only_describe_most_important_elements: ONLY describe the most important elements of the image.
- do_not_include_artist_name_or_title: If it is a work of art, do not include the artist's name or the title of the work.
- identify_image_orientation: Identify the image orientation (portrait, landscape, or square) and aspect ratio if obvious.
- use_vulgar_slang_and_profanity: Use vulgar slang and profanity.
- do_not_use_polite_euphemisms: Do NOT use polite euphemisms—lean into blunt, casual phrasing.
- include_character_age: Include information about the ages of any people/characters when applicable.
- include_camera_shot_type: Mention whether the image depicts an extreme close-up, close-up, medium close-up, medium shot, cowboy shot, medium wide shot, wide shot, or extreme wide shot.
- exclude_mood_feeling: Do not mention the mood/feeling/etc of the image.
- include_camera_vantage_height: Explicitly specify the vantage height (eye-level, low-angle worm’s-eye, bird’s-eye, drone, rooftop, etc.).
- mention_watermark: If there is a watermark, you must mention it.
- avoid_meta_descriptive_phrases: Your response will be used by a text-to-image model, so avoid useless meta phrases like “This image shows…”, "You are looking at...", etc.
- character_name: Person/Character Name, if choice
refer_character_name.
<a id="table1">PhiPrompt</a>
Use Microsoft Phi 3.5 text and visual models for local inference. Can be used to generate prompt words, process prompt words, or infer prompt words from images. Running this model requires at least 16GB of video memory.
Download model files from BaiduNetdisk or huggingface.co/microsoft/Phi-3.5-vision-instruct and huggingface.co/microsoft/Phi-3.5-mini-instruct and copy to ComfyUI\models\LLM folder.
Node Options:
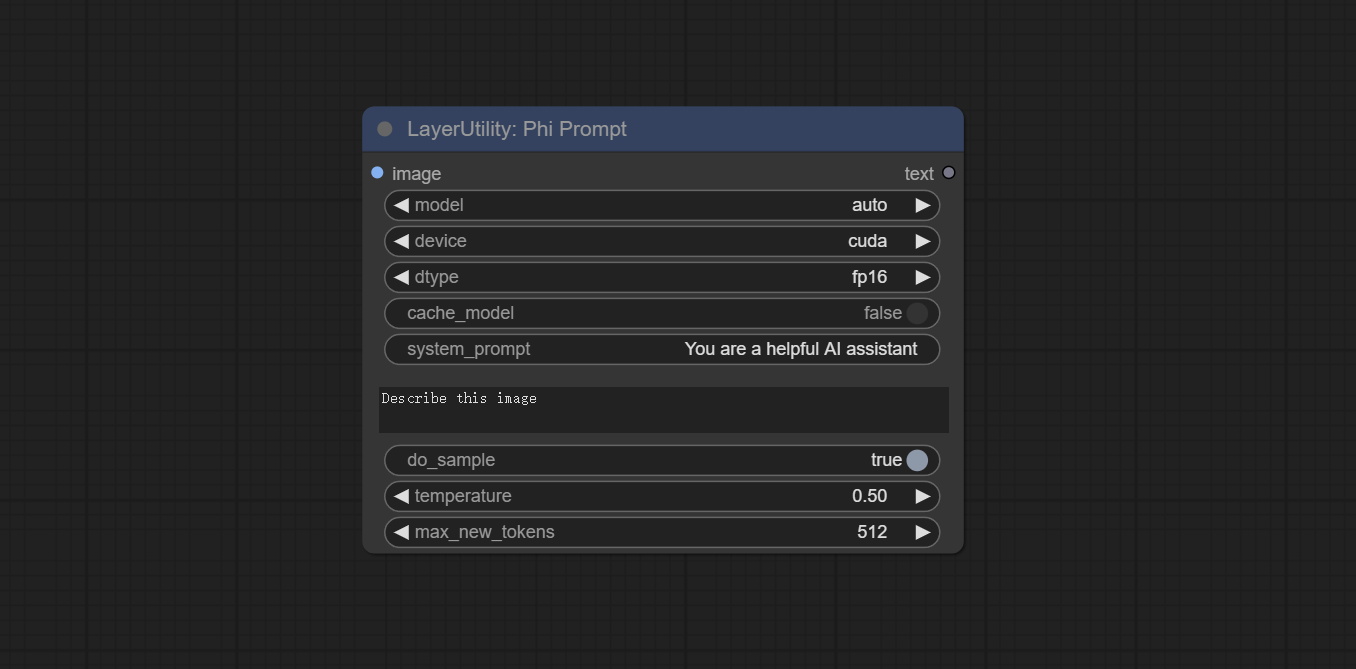
- image: Optional input. The input image will serve as the input for Phi-3.5-vision-instruct.
- model: Selectable to load Phi-3.5-vision-instruct or Phi-3.5-mini-instruct model. The default value of auto will automatically load the corresponding model based on whether there is image input.
- device: Model loading device. Supports CPU and CUDA.
- dtype: The model loading accuracy has three options: fp16, bf16, and fp32.
- cache_model: Whether to cache the model.
- system_prompt: The system prompt of Phi-3.5-mini-instruct.
- user_prompt: User prompt words for LLM model.
- do_sample: The do_Sample parameter of LLM defaults to True.
- temperature: The temperature parameter of LLM defaults to 0.5.
- max_new_tokens: The max_new_token parameter of LLM defaults to 512.
<a id="table1">Gemini</a>
Use Google Gemini API for text and visual models for local inference. Can be used to generate prompt words, process prompt words, or infer prompt words from images.
Apply for your API key on Google AI Studio, And fill it in api_key.ini, this file is located in the root directory of the plug-in, and the default name is api_key.ini.example. to use this file for the first time, you need to change the file suffix to .ini. Open it using text editing software, fill in your API key after google_api_key= and save it.
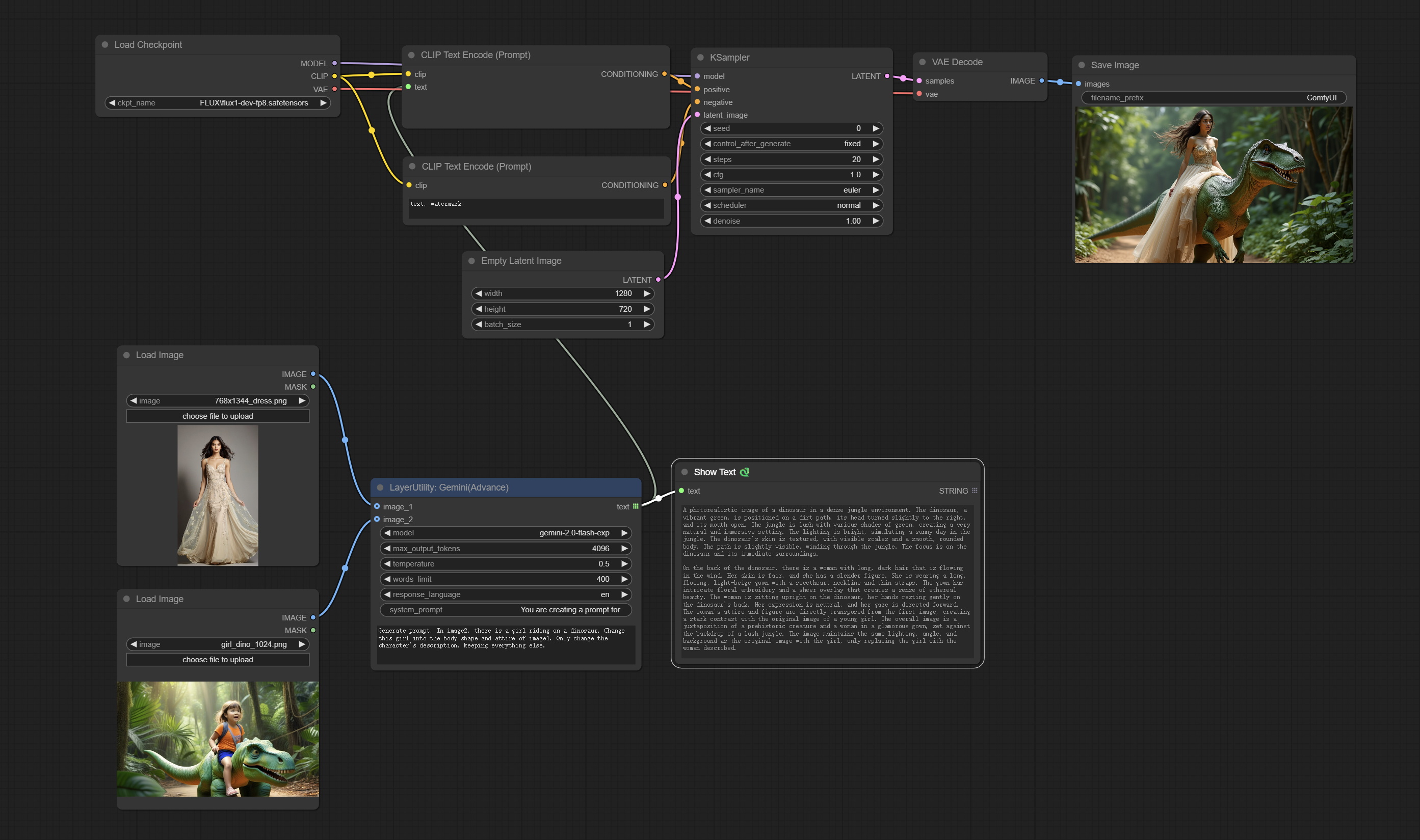
Node options:
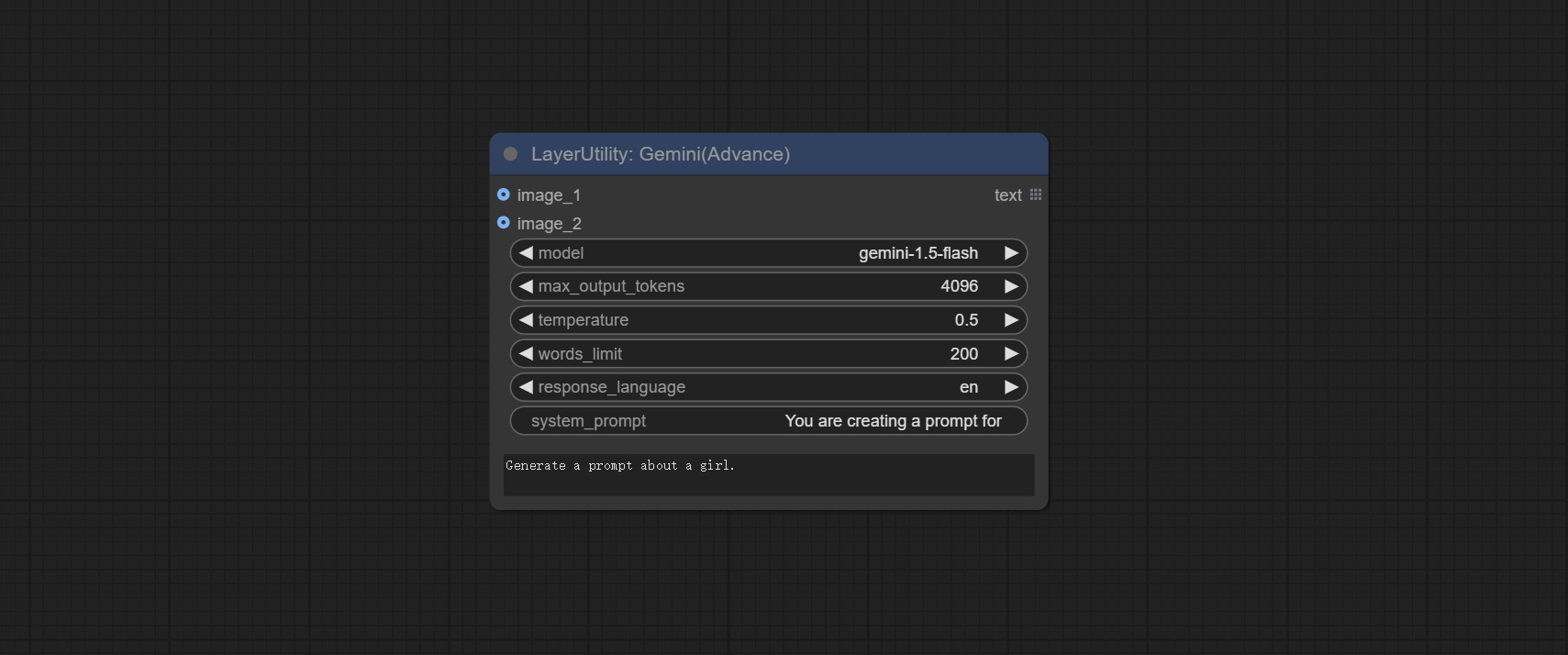
- image_1: Optional input. If there is an image input here, please explain the purpose of 'image_1' in user_dempt.
- image_2: Optional input. If there is an image input here, please explain the purpose of 'image_2' in user_dempt.
- model: Choose the Gemini model.
- max_output_tokens: The max_output_token parameter of Gemini defaults to 4096.
- temperature: The temperature parameter of Gemini defaults to 0.5.
- words_limit: The default word limit for replies is 200.
- response_language: The language of the reply.
- system_prompt: The system prompt.
- user_prompt: The user prompt.
<a id="table1">GeminiV2</a>
On the basis of Gemini nodes, switch to using the new google-genai dependency package, which supports the latest gemini-2.0-flash, gemini-2.0-flash-lite, and gemini-2.5-pro-exp-03-25 models.
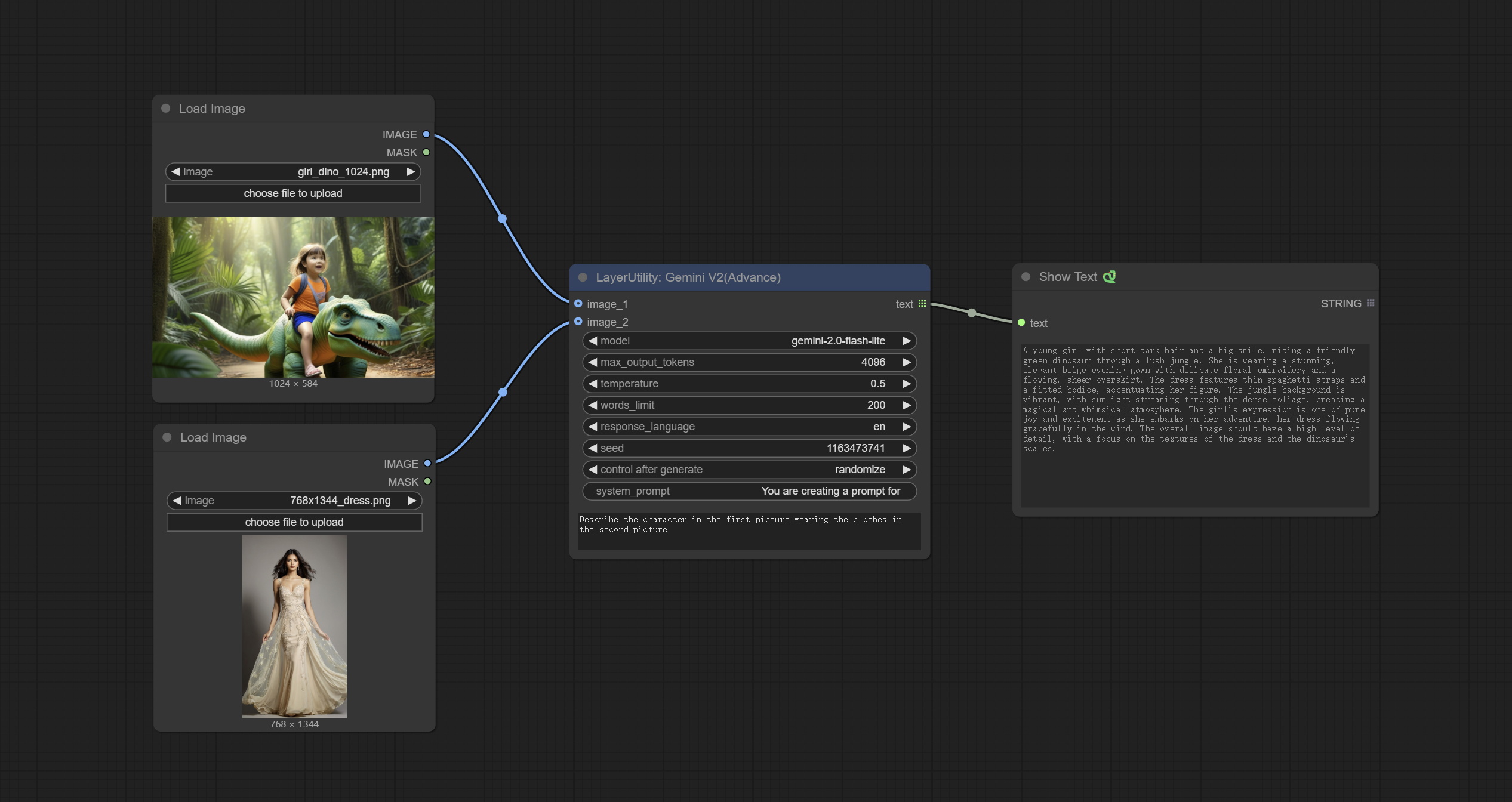
Add on the original node:
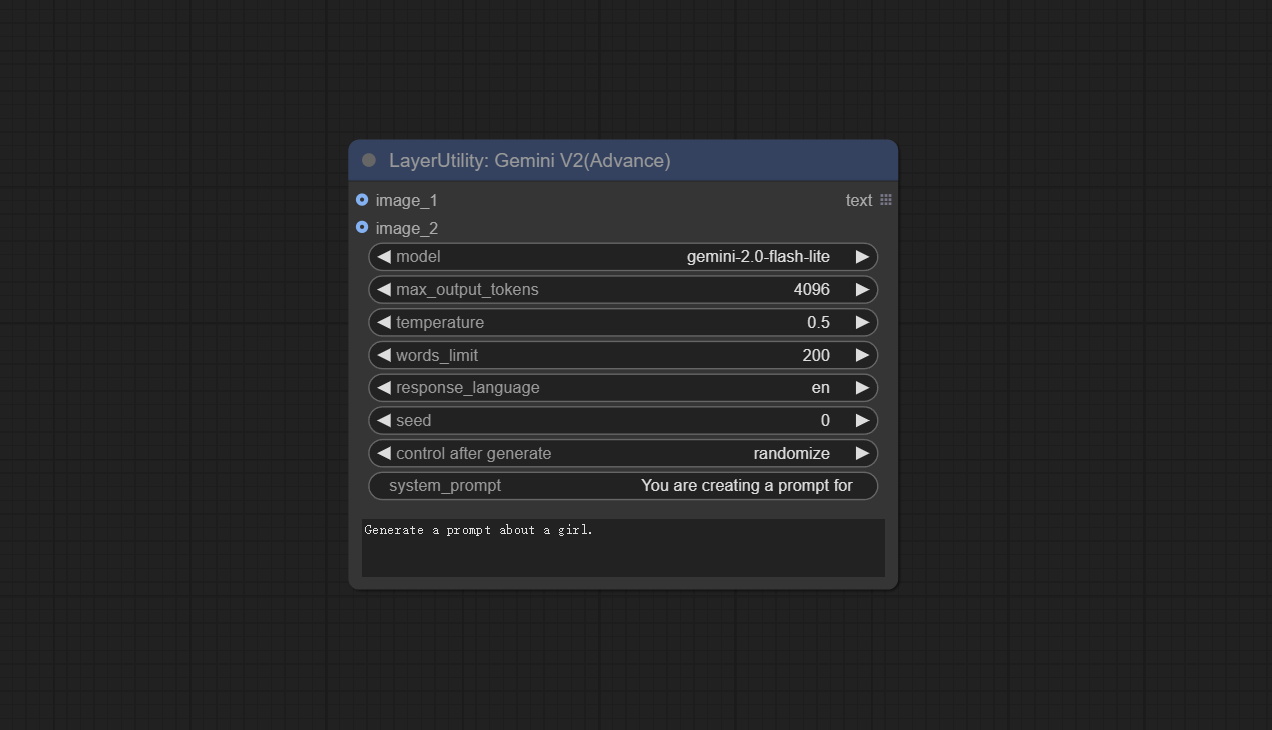
- seed: Seed value used when requesting Google API.
<a id="table1">GeminiImageEdit</a>
Implement multimodal image editing using the gemini-2.0-flash-exp-image-generation model.
Apply for your API key on Google AI Studio, And fill it in api_key.ini, this file is located in the root directory of the plug-in, and the default name is api_key.ini.example. to use this file for the first time, you need to change the file suffix to .ini. Open it using text editing software, fill in your API key after google_api_key= and save it.
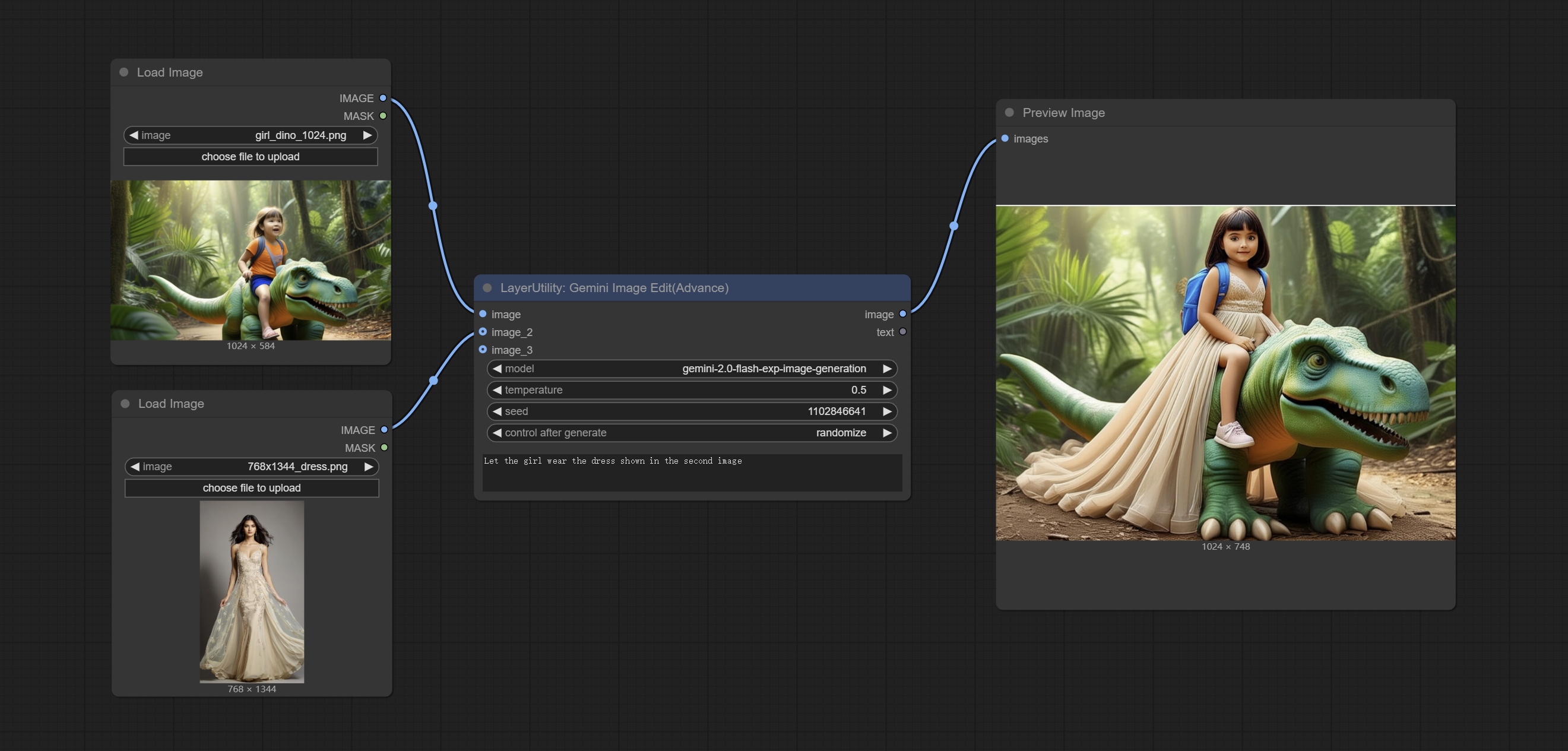
Node Options:
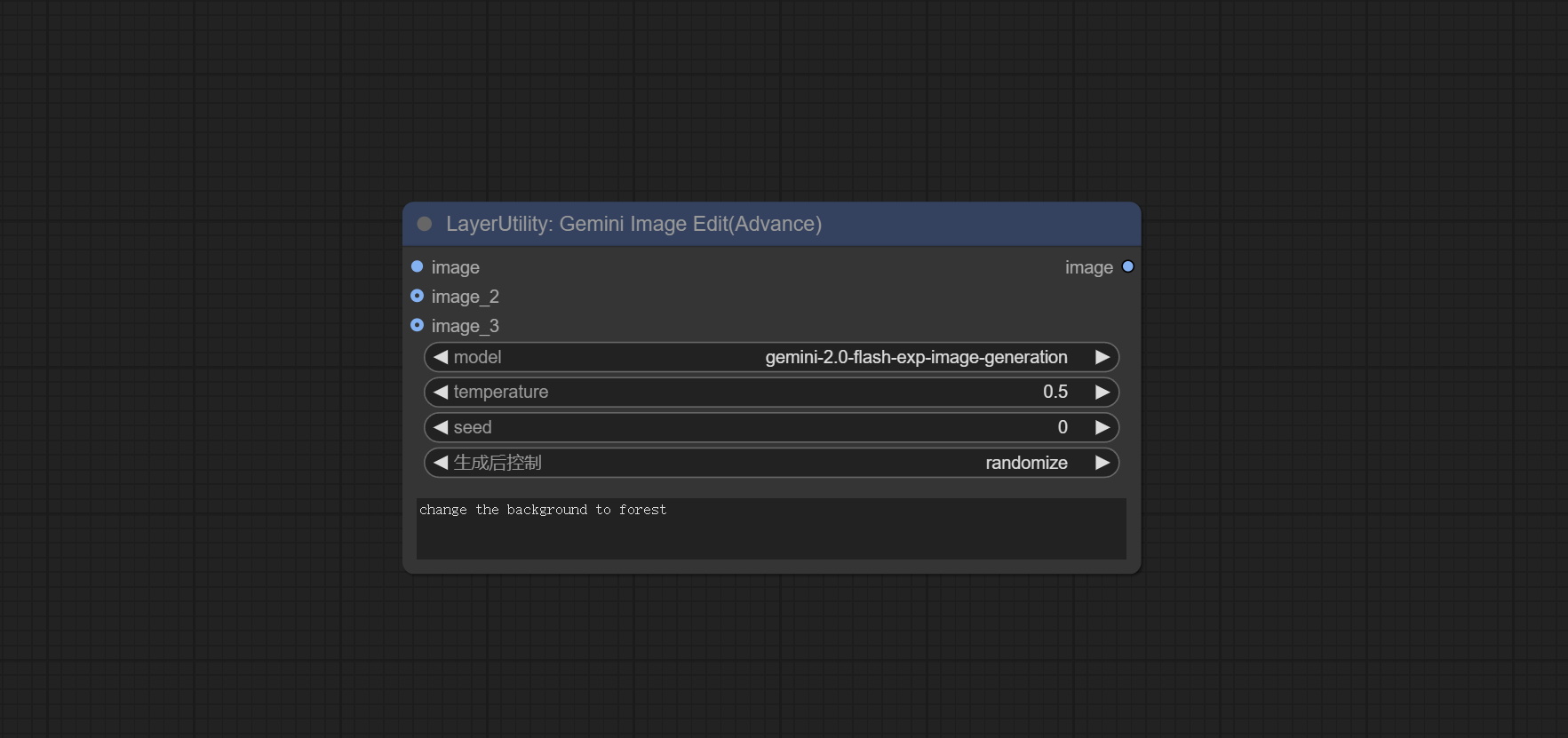
- image: The input image.
- image_2: Optional second image input.
- image_3: Optional third image input.
- model: Choose the Gemini model. Currently, only the gemini-2.0-flash-exp-image-generation model is supported.
- temperature: The temperature parameter of Gemini defaults to 0.5.
- seed: Seed value used when requesting Google API.
- control_after_generate: Set whether to change the seed every time.
- user_prompt: The user prompt.
<a id="table1">DeepSeekAPI</a>
Use the DeepSeek API for text inference, supporting multi node context concatenation.
Apply for an API key for free at https://platform.deepseek.com/api_keys, And fill it in api_key.ini, this file is located in the root directory of the plug-in, and the default name is api_key.ini.example. to use this file for the first time, you need to change the file suffix to .ini. Open it using text editing software, fill in your API key after deepseek_api_key= and save it.
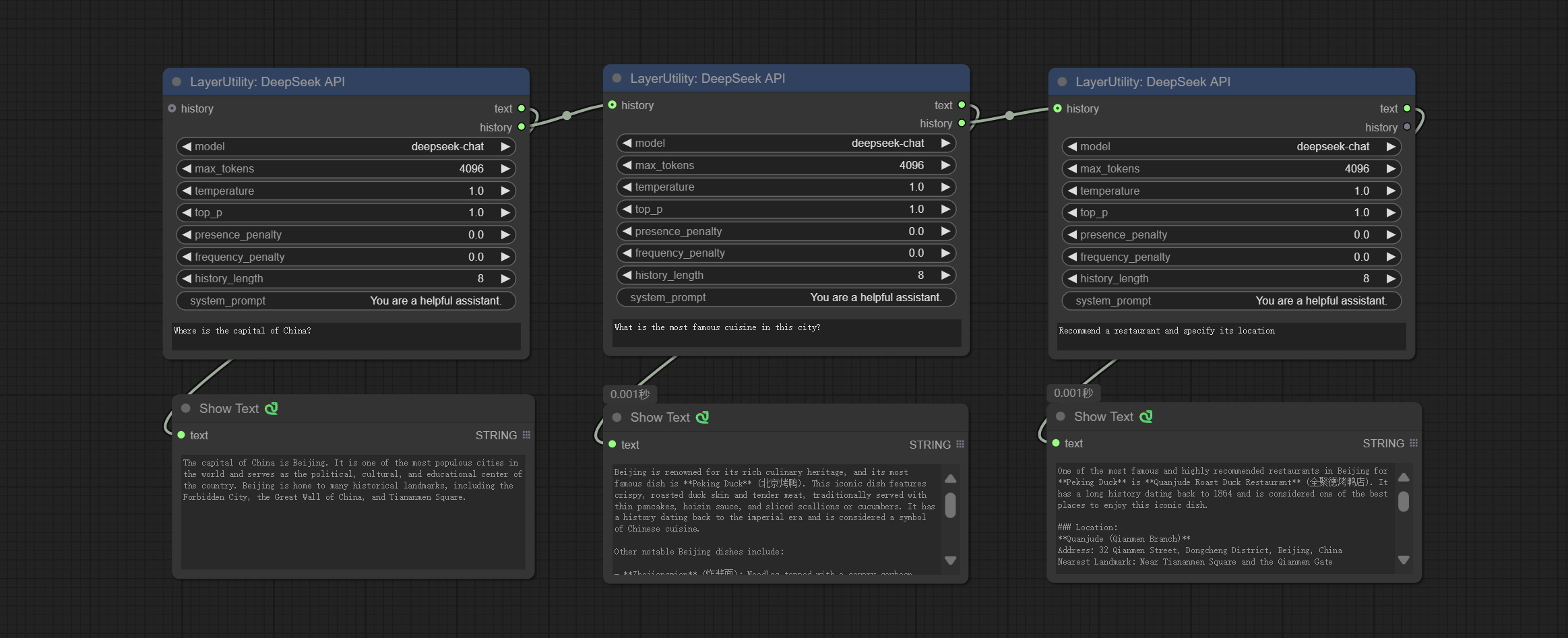
Node Options:
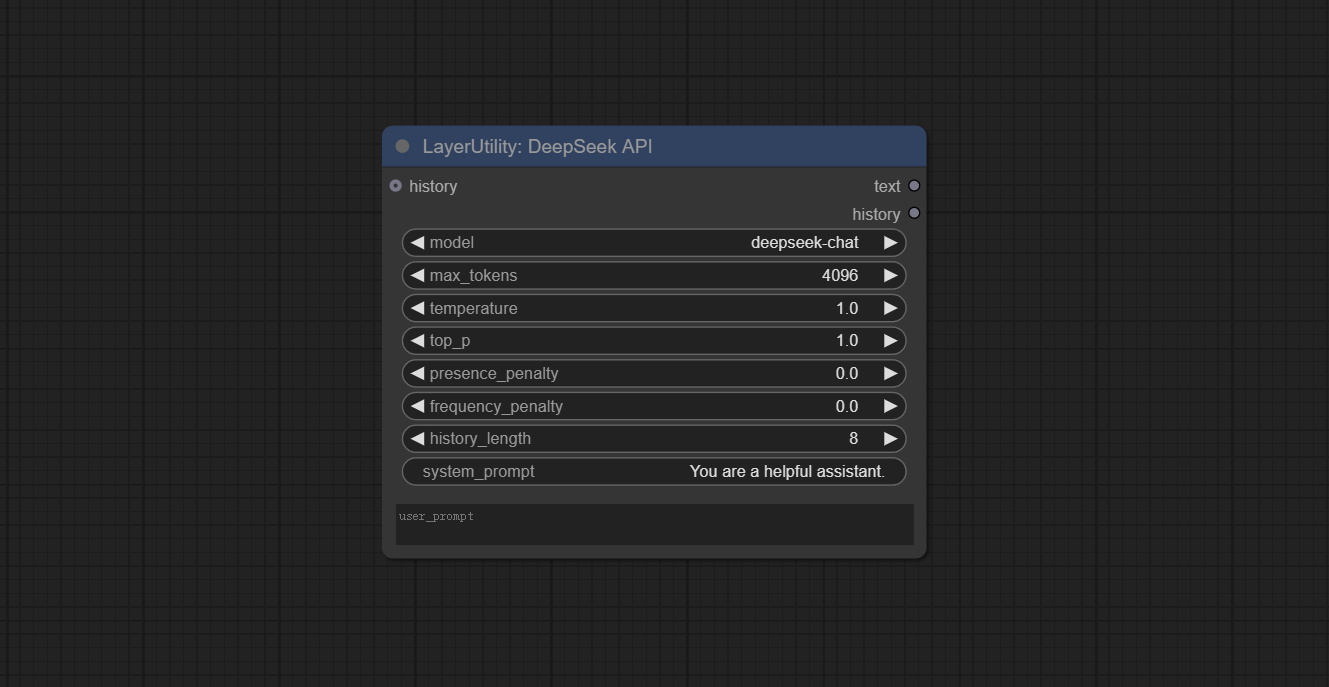
- history: History of DeepSeekAPI node, optional input. If there is input here, historical records will be used as context.
- model: Choose the DeepSeek model, currently there is only one option: "deepseek-chat", which is the DeepSeek-V3 model.
- max_tokens: The max_token parameter of DeepSeek defaults to 4096.
- temperature: The temperature parameter of DeepSeek defaults to 1.
- top_p: The top_p parameter of DeepSeek defaults to 1.
- presence_penalty: The presence_penalty parameter of DeepSeek defaults to 0.
- frequency_penalty: The frequency_penalty parameter of DeepSeek defaults to 0.
- history_length: History record length. Records exceeding this length will be discarded.
- system_prompt: The system prompt.
- user_prompt: The user prompt.
Outputs:
- text: Output text of DeepSeek.
- history: History of DeepSeek conversations.
<a id="table1">DeepSeekAPI_V2</a>
On the basis of the DeepSeekAPI node, DeepSeek API supporting AliYun and VolcEngine will be added, and these two Chinese cloud service providers will provide more stable API services.
-
On VolcEngine Applying for the VolcEngine API key, there is a free quota of 500 thousand tokens. If you fill in my invitation code
27RVS1QNwhen applying, you will receive an additional 3.75 million R1 model free tokens. -
On AliYun Apply for AliYun API key.
-
Fill in the obtained API key into the fields
volcengine_api_keyandaliyun_api_keyofapi_key.ini. This file is located in the root directory of the plugin, with a default name ofapi_key.ini.example. Edit it and change the file extension to '.ini'.
Add Options:
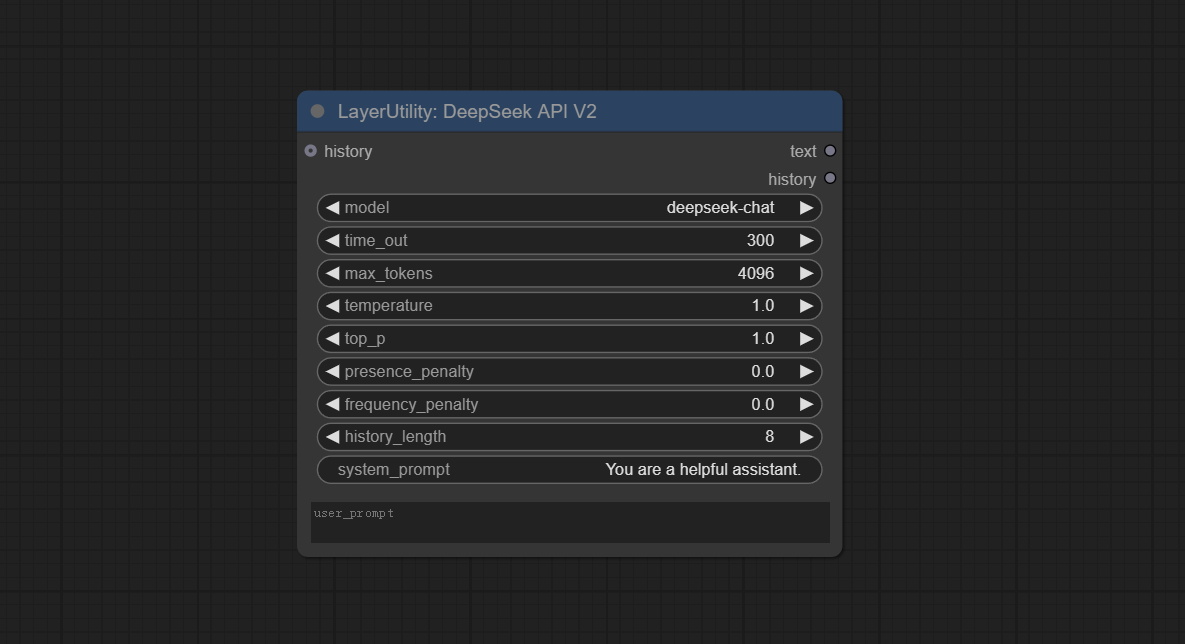
- time_out: The timeout period is set to 300 seconds by default.
<a id="table1">ZhipuGLM4</a>
Use the Zhipu API for text inference, supporting multi node context concatenation.
Apply for an API key for free at https://bigmodel.cn/usercenter/proj-mgmt/apikeys, And fill it in api_key.ini, this file is located in the root directory of the plug-in, and the default name is api_key.ini.example. to use this file for the first time, you need to change the file suffix to .ini. Open it using text editing software, fill in your API key after zhipu_api_key= and save it.
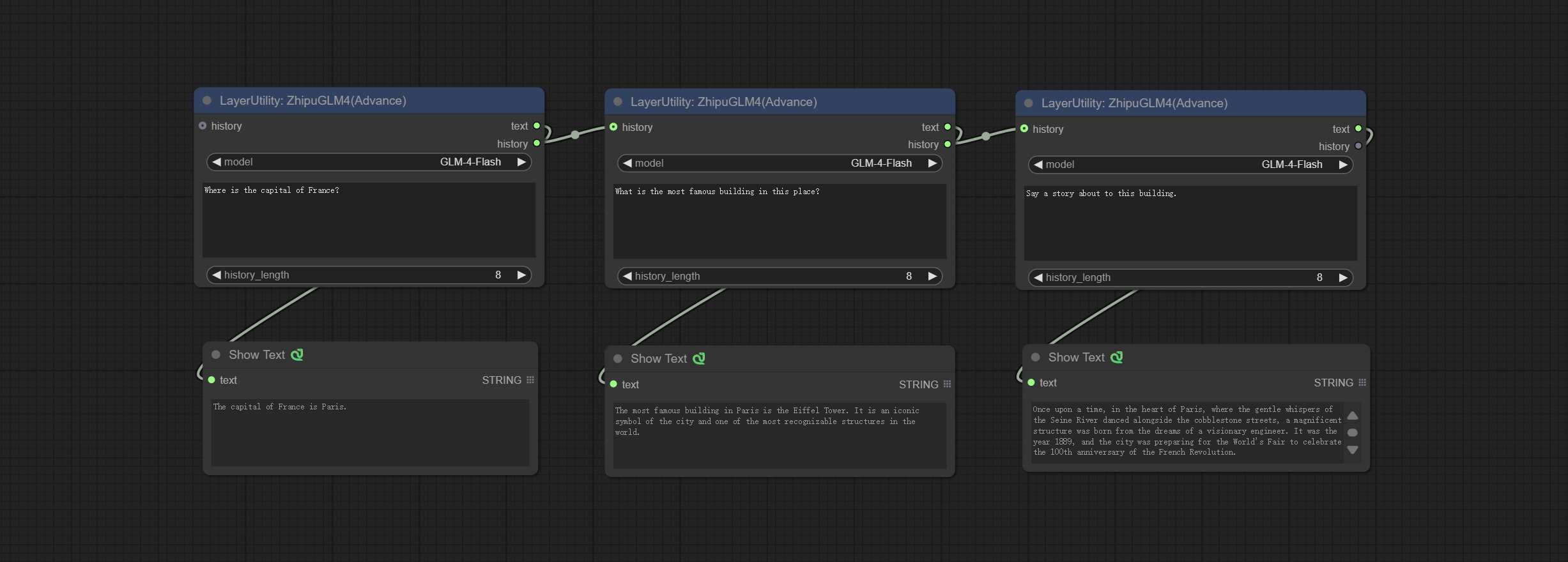
Node Options:
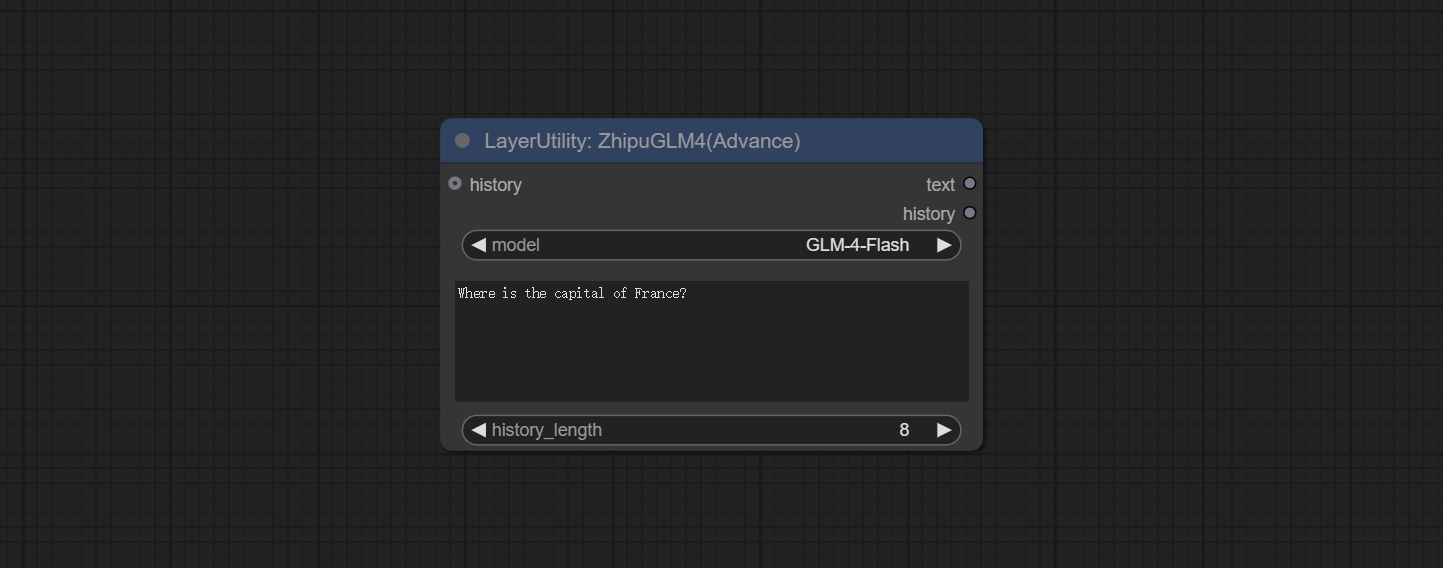
- history: History of GLM4 node, optional input. If there is input here, historical records will be used as context.
- model: Select GLM4 model. GLM-4-Flash is a free model.
- user_prompt: The user prompt.
- history_length: History record length. Records exceeding this length will be discarded.
Outputs:
- text: Output text of GLM4.
- history: History of GLM4 conversations.
<a id="table1">ZhipuGLM4V</a>
Use the Zhipu API for visual inference.
Apply for an API key for free at https://bigmodel.cn/usercenter/proj-mgmt/apikeys, And fill it in api_key.ini, this file is located in the root directory of the plug-in, and the default name is api_key.ini.example. to use this file for the first time, you need to change the file suffix to .ini. Open it using text editing software, fill in your API key after zhipu_api_key= and save it.
Node Options:
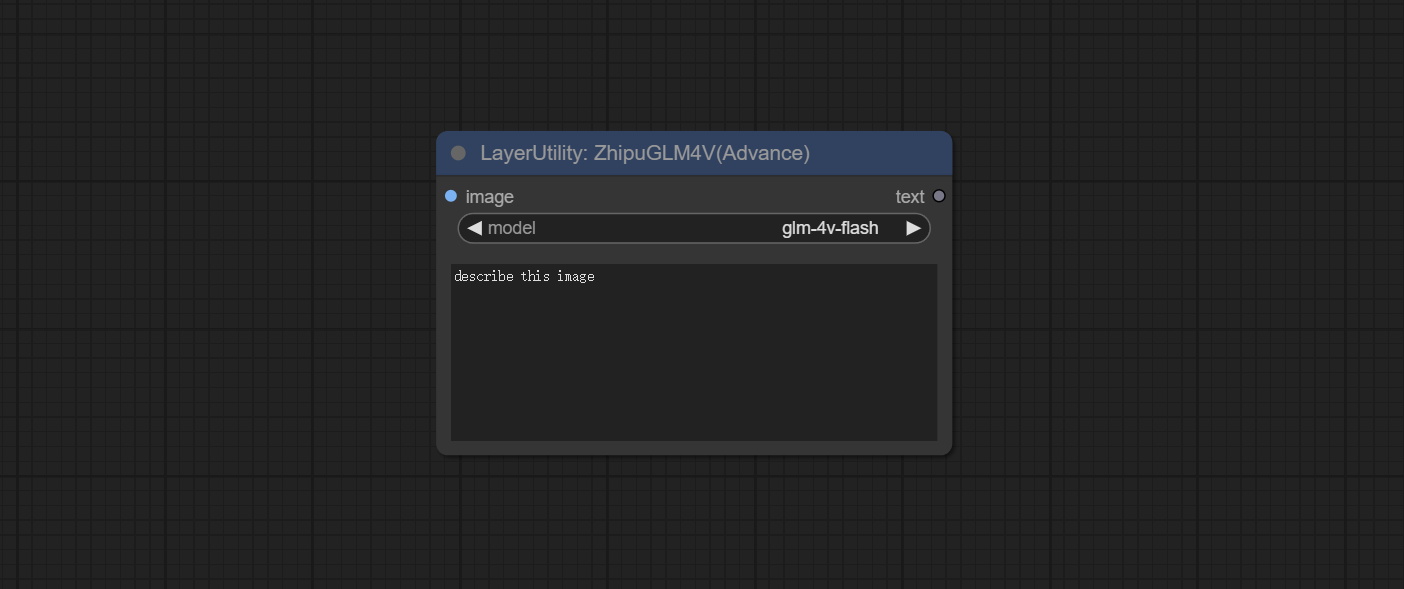
- image: The input image.
- model: Select the GLM4V model. glm-4v-flash is a free model.
- user_prompt: The user prompt.
Output:
- text: Output text of GLM4V.
<a id="table1">SmolLM2</a>
Use the SmolLM2 model for local inference.
Download model files from BaiduNetdisk or huggingface,
find the SmolLM2-135M-Instruct, SmolLM2-360M-Instruct, SmolLM2-1.7B-Instruct folders, download at least one of them, copy to ComfyUI/models/smol folder.
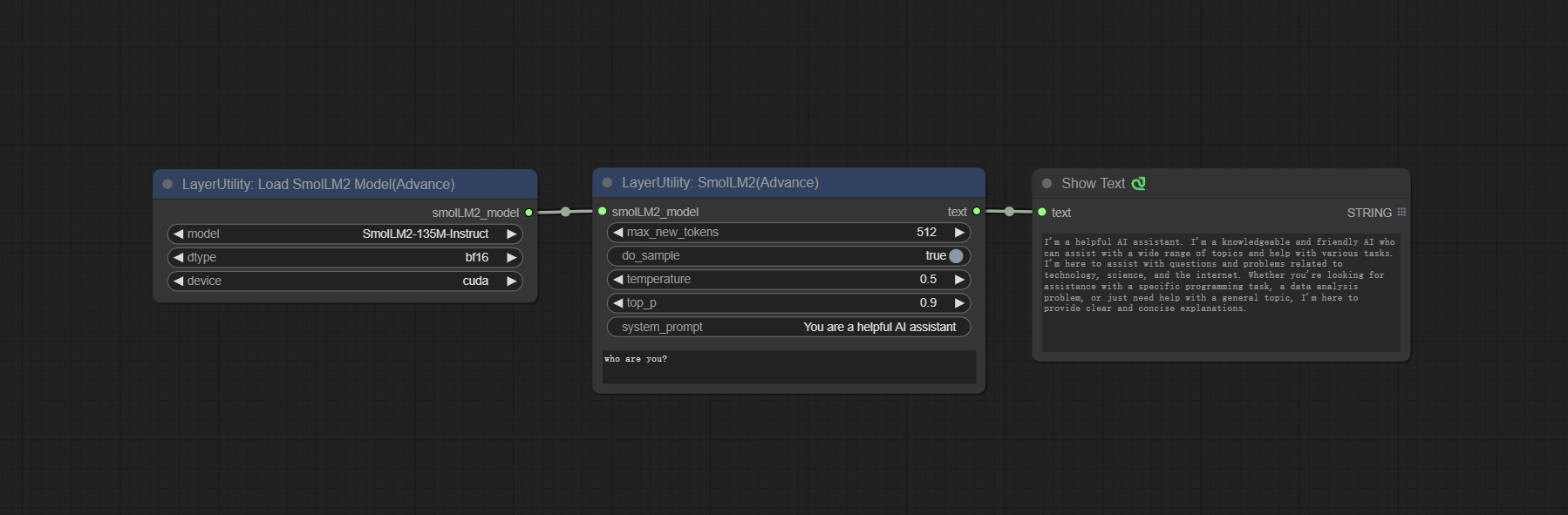
Node Options:
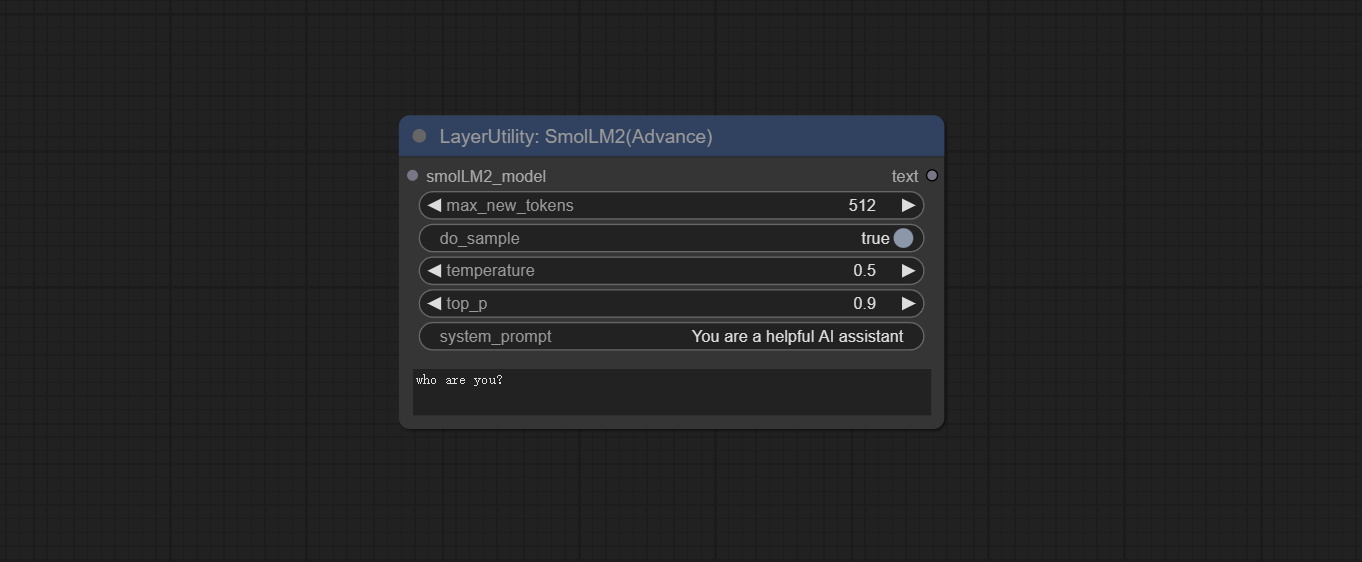
- smolLM2_model: The input of SmolLM2 model is loaded from the LoadSmolLM2Model node.
- max_new_tokens: The maximum number of tokens is 512 by default.
- do_sample: The do_Sample parameter defaults to True.
- temperature: The temperature parameter defaults to 0.5.
- top-p: The top_p parameter defaults to 0.9.
- system_prompt: System prompt words.
- user_prompt: User prompt words.
<a id="table1">LoadSmolLM2Model</a>
Load SmolLM2 model.
Node Options:
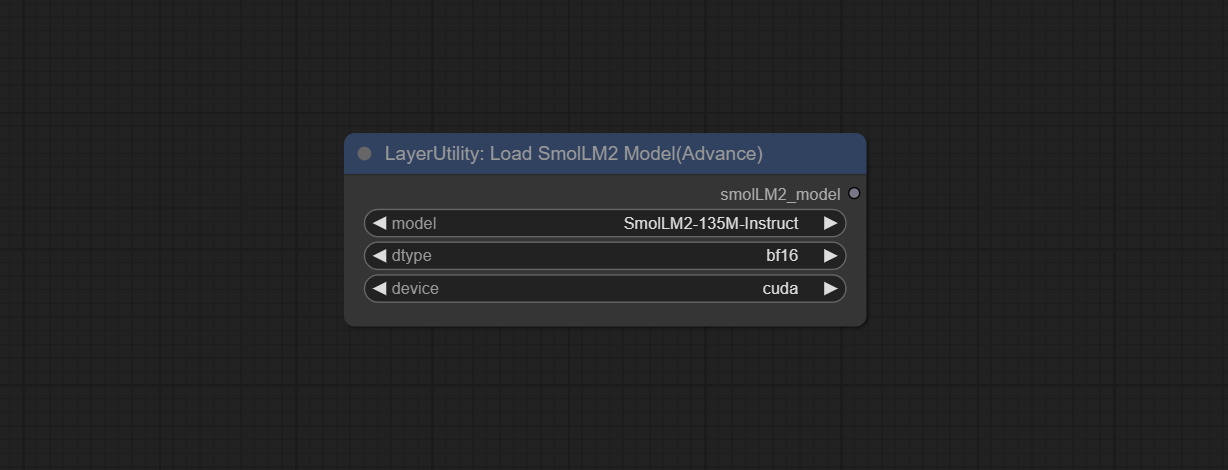
- model: There are three options for selecting the SmolLM2 model: SmolLM2-135M-Instruct, SmolLM2-360M-Instruct and SmolLM2-1.7B-Instruct.
- dtype: The model accuracy has two options: bf16 and fp32.
- device: The model loading device has two options: cuda or cpu.
<a id="table1">SmolVLM</a>
Using SmolVLM lightweight visual models for local inference.
Donwload the SmolVLM-Instruct folder from BaiduNetdisk or huggingface and copy to ComfyUI/models/smol folder.
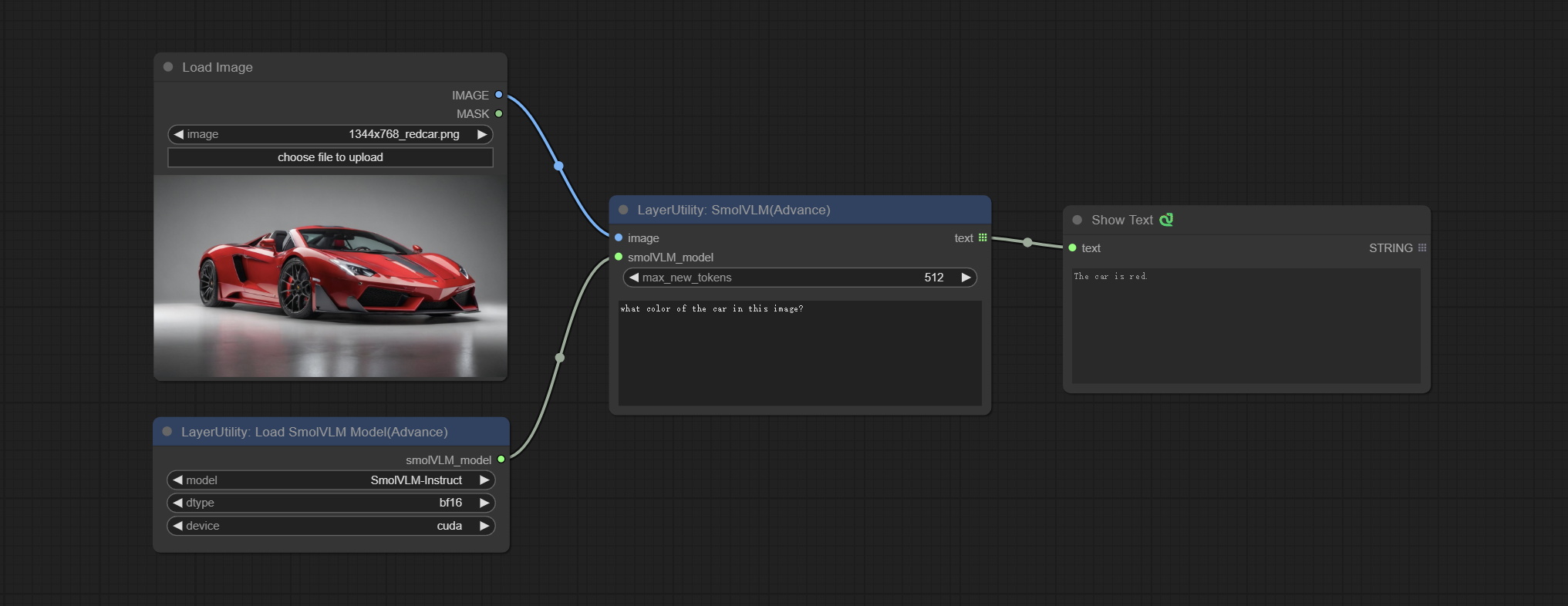
Node Options:
- image: Image input, supports batch images.
- smolVLM_model: The input of the SmolVLM model is loaded from the LoadSmolVLMModel node.
- max_new_tokens: The maximum number of tokens is 512 by default.
- user_prompt: User prompt words.
<a id="table1">LoadSmolVLMModel</a>
Load SmolVLM model.
Node Options:
- model: The SmolVLM model selection currently only has the option of SmolVLM-Instruct.
- dtype: The model accuracy has two options: bf16 and fp32.
- device: The model loading device has two options: cuda or cpu.
<a id="table1">JimengImageToImageAPI</a>
Edit images using the Jimeng API.
Please create an account on Volcano Engine, apply for API AccessKeyID and SecretAccessKey, and fill them in api_key. ini. This file is located in the root directory of the plugin and its default name is api_key.ini.example. When using this file for the first time, you need to change the file extension to '.ini'. Open with text editing software and fill in the corresponding values after volcengine_SecretAccessKey= and volcengine_SecretAccessKey=.
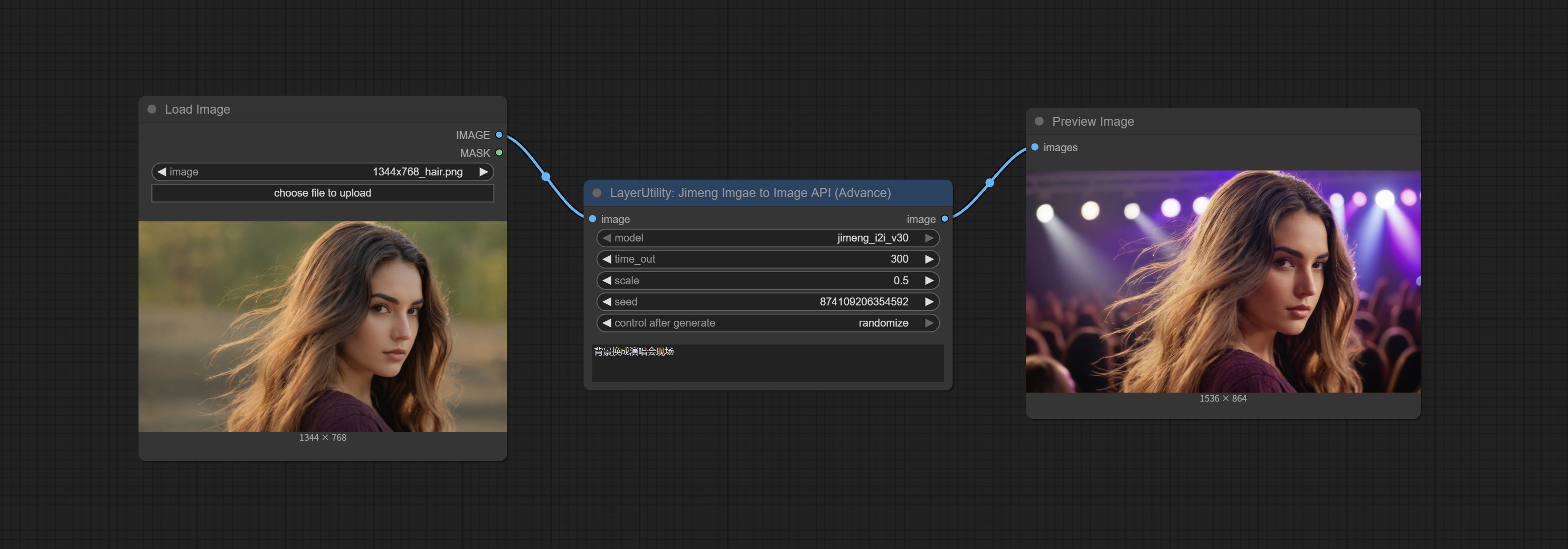
Node Options:
- image: The input image.
- model: Choose the DreamMap and Life Map model. Currently, only the Jimeng_i2i-v30 model is supported.
- time_out: The maximum time limit for waiting for API return, in seconds. If this time is exceeded, the node will end running.
- scale: The scale parameter of jimeng_i2iuv30 is set to 0.5 by default.
- seed: The seed value.
- prompt: The prompt.
<a id="table1">UserPromptGeneratorTxtImg</a>
UserPrompt preset for generating SD text to image prompt words.
Node options:
- template: Prompt word template. Currently, only the 'SD txt2img prompt' is available.
- describe: Prompt word description. Enter a simple description here.
- limit_word: Maximum length limit for output prompt words. For example, 200 means that the output text will be limited to 200 words.
<a id="table1">UserPromptGeneratorTxtImgWithReference</a>
UserCompt preset for generating SD text to image prompt words based on input content.
Node options:
- reference_text: Reference text input. Usually it is a style description of the image.
- template: Prompt word template. Currently, only the 'SD txt2img prompt' is available.
- describe: Prompt word description. Enter a simple description here.
- limit_word: Maximum length limit for output prompt words. For example, 200 means that the output text will be limited to 200 words.
<a id="table1">UserPromptGeneratorReplaceWord</a>
UserPrompt preset used to replace a keyword in text with different content. This is not only a simple replacement, but also a logical sorting of the text based on the context of the prompt words to achieve the rationality of the output content.
Node options:
- orig_prompt: Original prompt word input.
- template: Prompt word template. Currently, only 'prompt replace word' is available.
- exclude_word: Keywords that need to be excluded.
- replace_with_word: That word will replace the exclude_word.
<a id="table1">PromptTagger</a>
Inference the prompts based on the image. it can replace key word for the prompt. This node currently uses Google Gemini API as the backend service. Please ensure that the network environment can use Gemini normally.
Apply for your API key on Google AI Studio, And fill it in api_key.ini, this file is located in the root directory of the plug-in, and the default name is api_key.ini.example. to use this file for the first time, you need to change the file suffix to .ini. Open it using text editing software, fill in your API key after google_api_key= and save it.
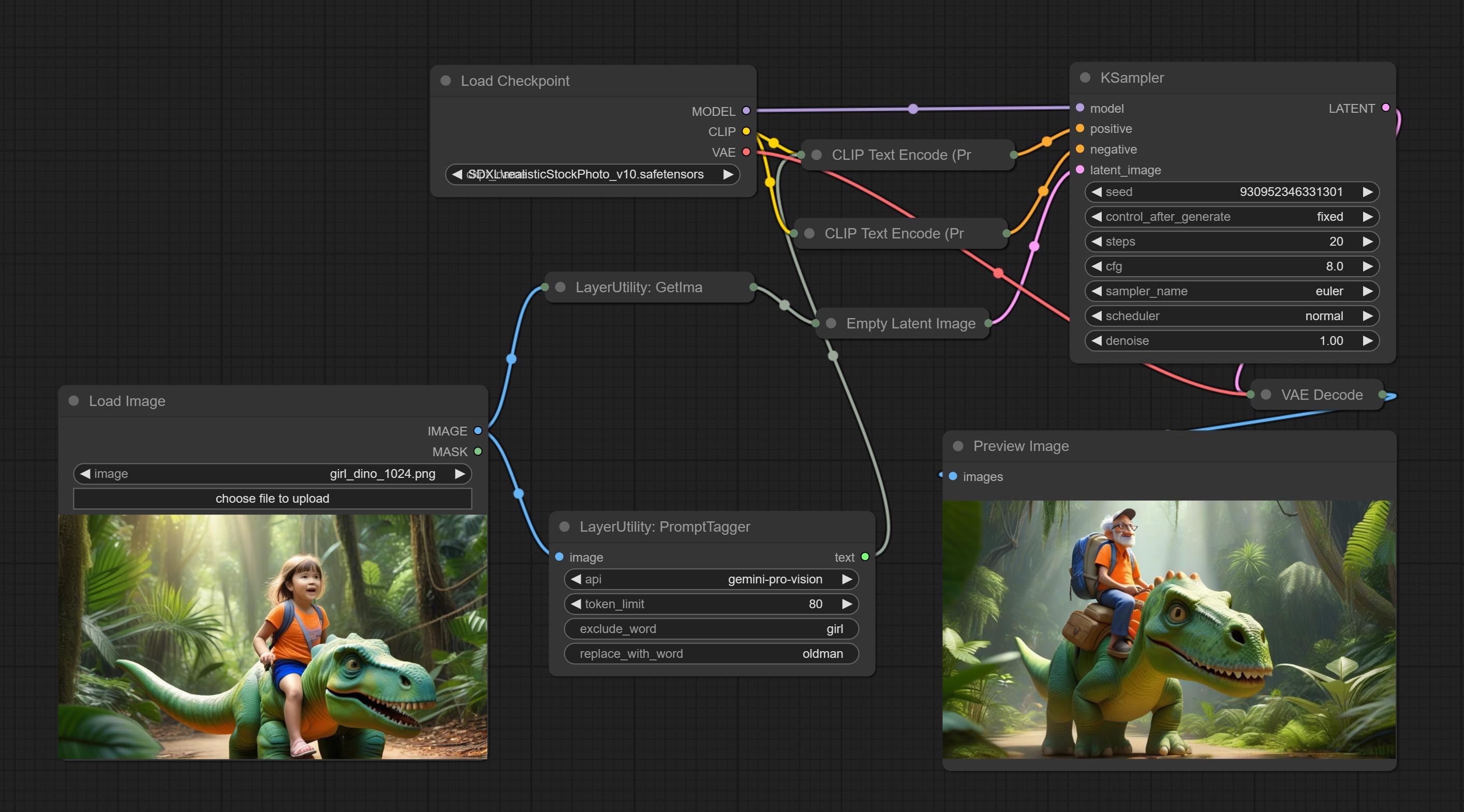
Node options:
- api: The Api used. At present, there are two options "gemini-1. 5-flash" and "google-gemini".
- token_limit: The maximum token limit for generating prompt words.
- exclude_word: Keywords that need to be excluded.
- replace_with_word: That word will replace the exclude_word.
<a id="table1">PromptEmbellish</a>
Enter simple prompt words, output polished prompt words, and support inputting images as references, and support Chinese input. This node currently uses Google Gemini API as the backend service. Please ensure that the network environment can use Gemini normally.
Apply for your API key on Google AI Studio, And fill it in api_key.ini, this file is located in the root directory of the plug-in, and the default name is api_key.ini.example. to use this file for the first time, you need to change the file suffix to .ini. Open it using text editing software, fill in your API key after google_api_key= and save it.
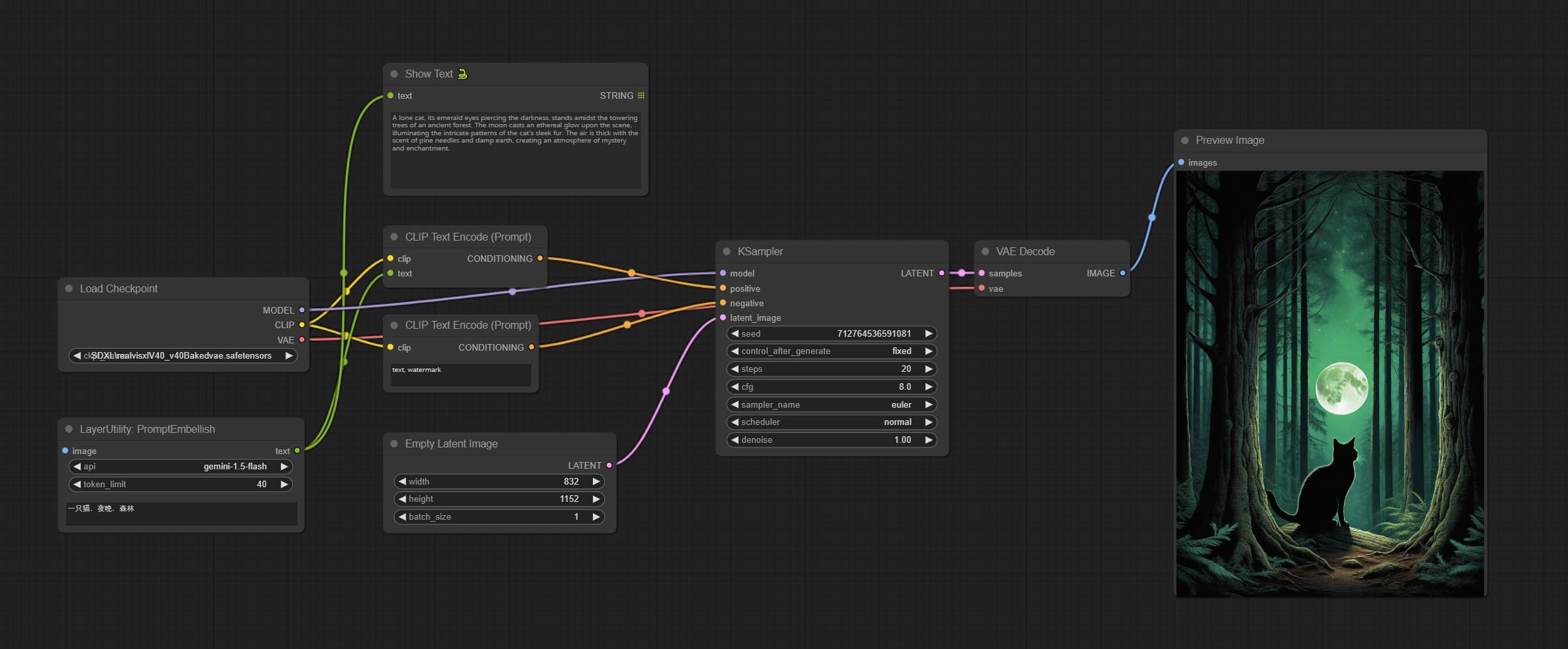
Node options:
- image: Optional, input image as a reference for prompt words.
- api: The Api used. At present, there are two options "gemini-1. 5-flash" and "google-gemini".
- token_limit: The maximum token limit for generating prompt words.
- discribe: Enter a simple description here. supports Chinese text input.
<a id="table1">Florence2Image2Prompt</a>
Use the Florence 2 model to infer prompt words. The code for this node section is fromyiwangsimple/florence_dw, thanks to the original author.
*When using it for the first time, the model will be automatically downloaded. You can also download the model file from BaiduNetdisk to ComfyUI/models/florence2 folder.
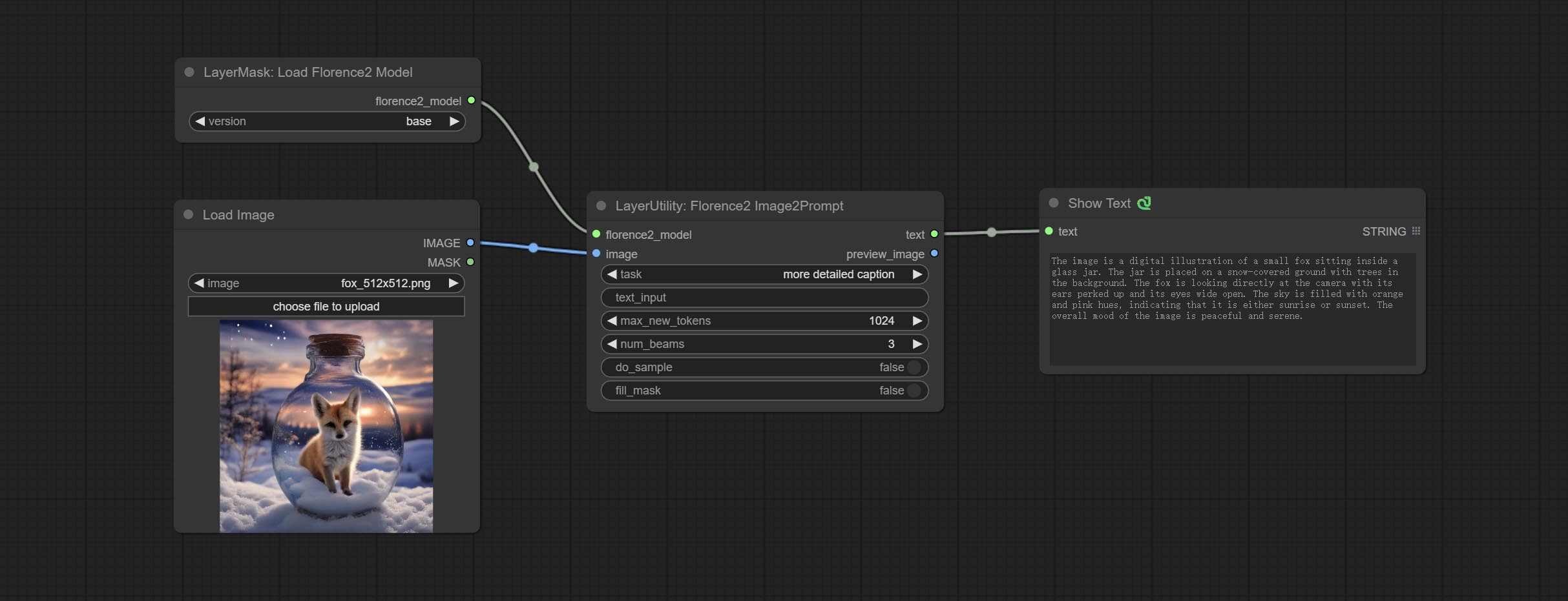
Node Options:
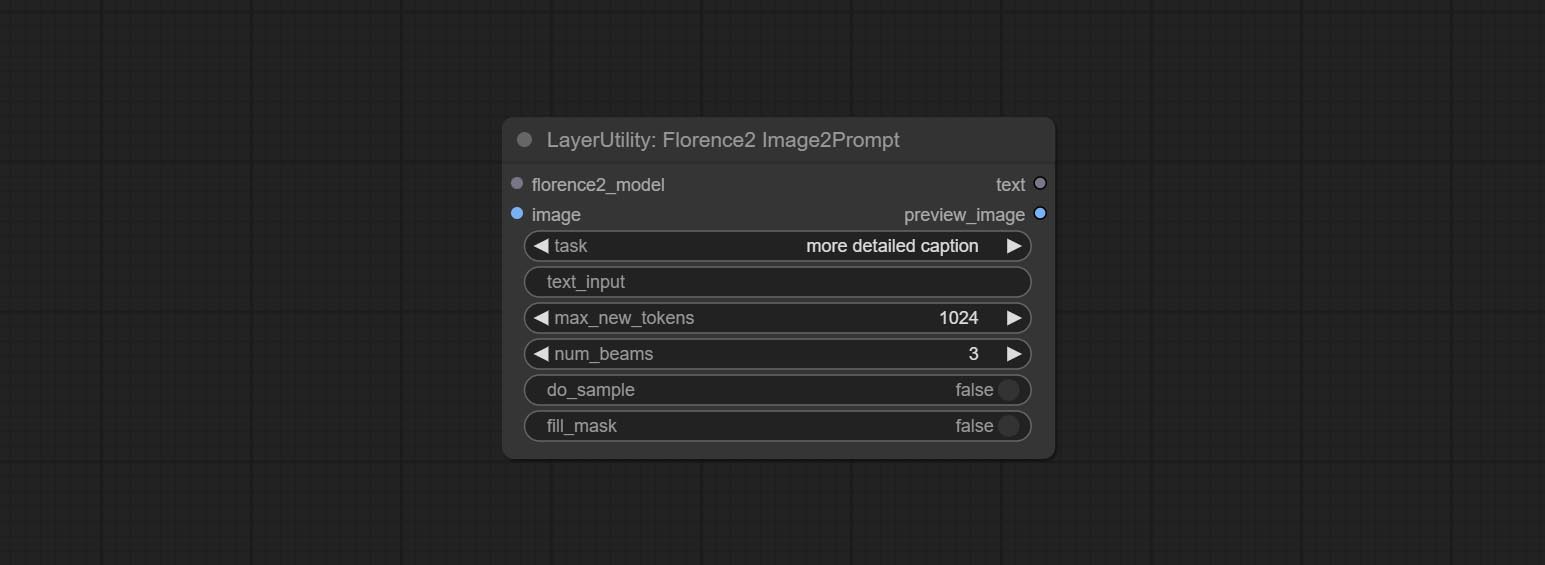
- florence2_model: Florence2 model input.
- image: Image input.
- task: Select the task for florence2.
- text_input: Text input for florence2.
- max_new_tokens: The maximum number of tokens for generating text.
- num_beams: The number of beam searches that generate text.
- do_sample: Whether to use text generated sampling.
- fill_mask: Whether to use text marker mask filling.
<a id="table1">GetColorTone</a>
Obtain the main color or average color from the image and output RGB values.
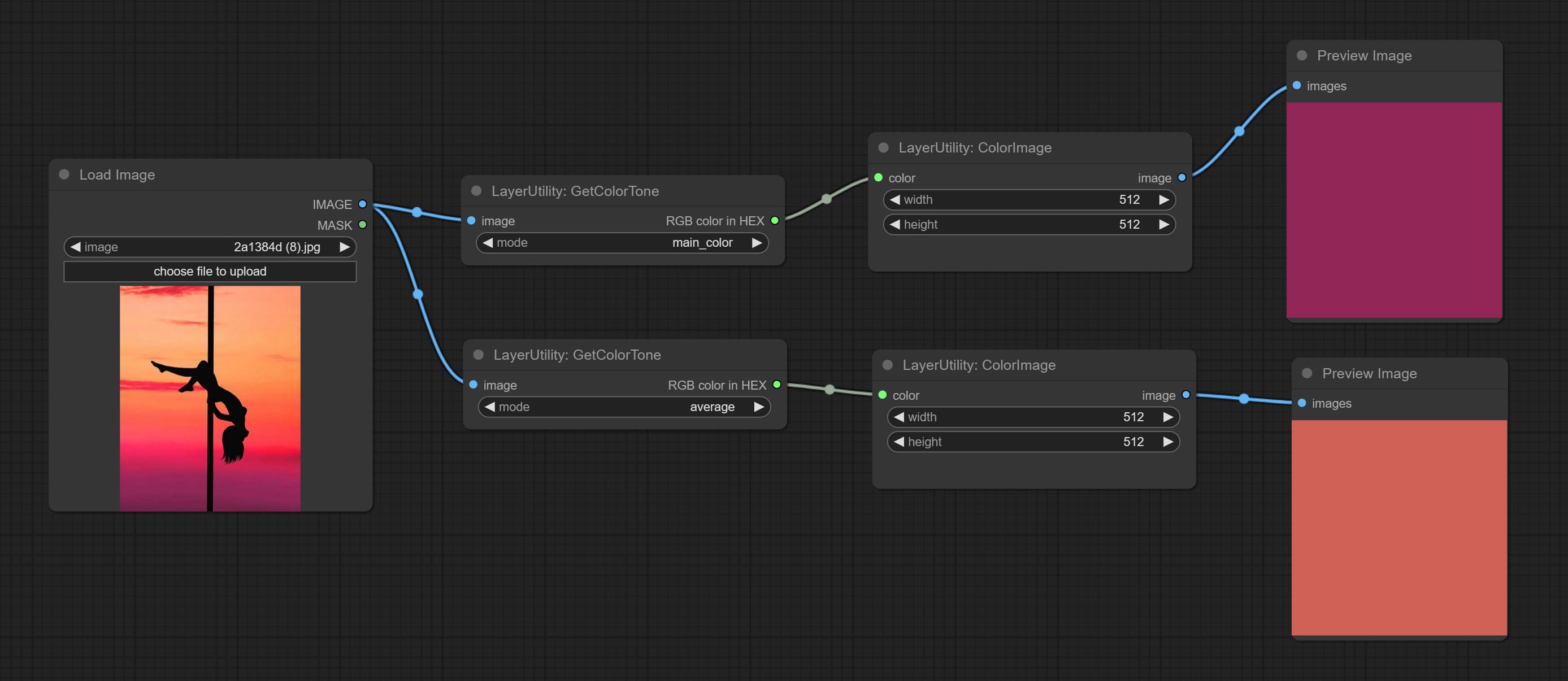
Node options:
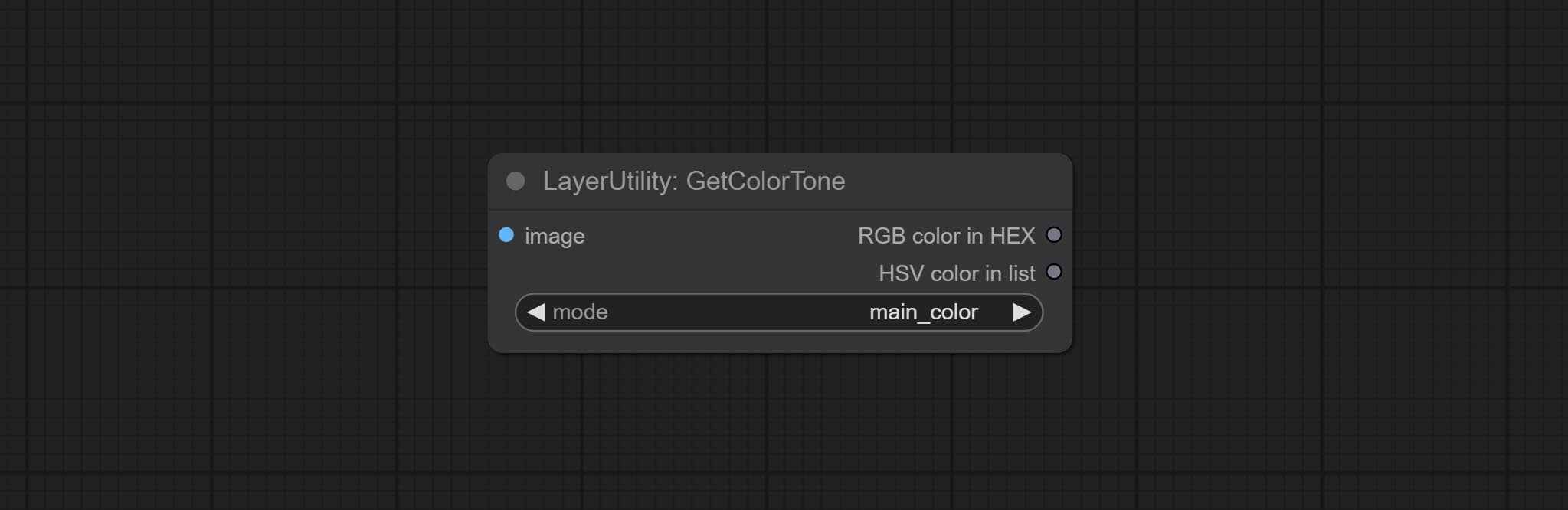
- mode: There are two modes to choose from, with the main color and average color.
Output type:
- RGB color in HEX: The RGB color described by hexadecimal RGB format, like '#FA3D86'.
- HSV color in list: The HSV color described by python's list data format.
<a id="table1">GetColorToneV2</a>
V2 upgrade of GetColorTone. You can specify the dominant or average color to get the body or background.
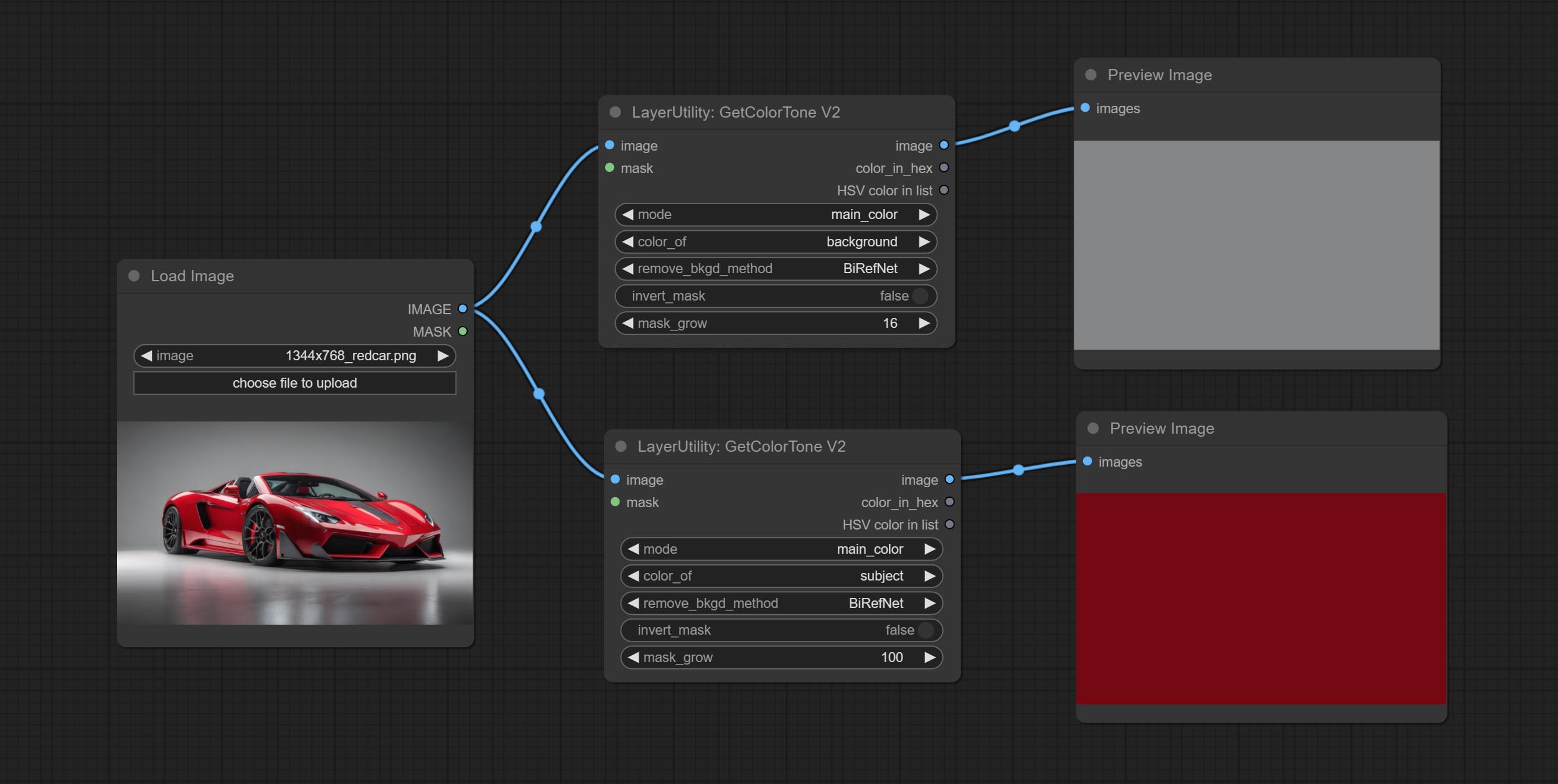
The following changes have been made on the basis of GetColorTong:
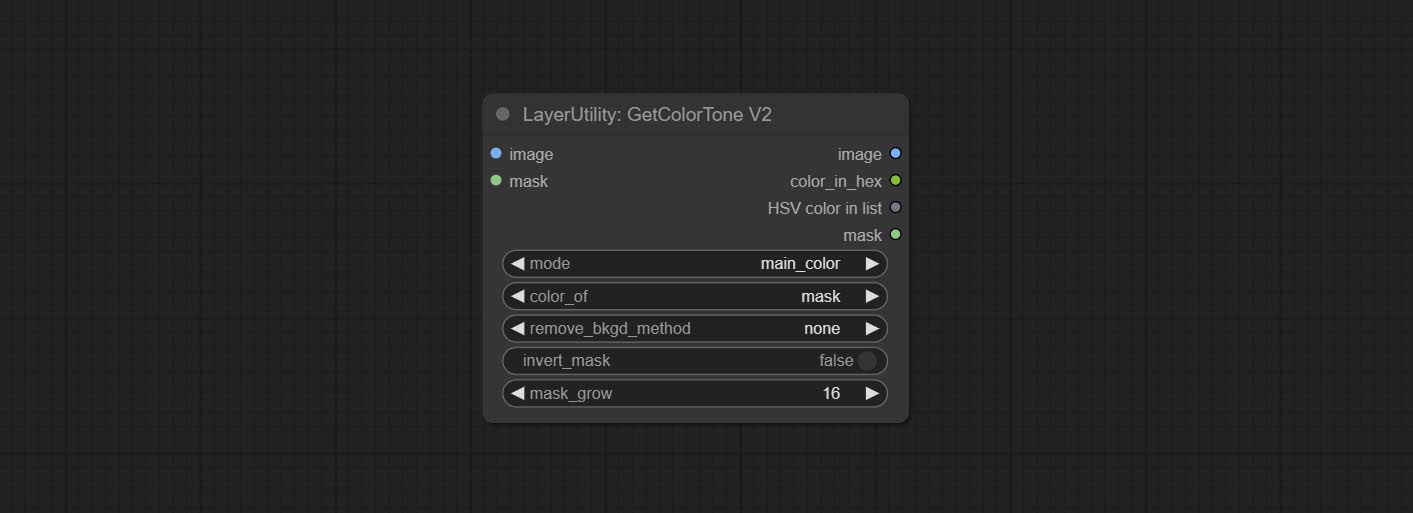
- color_of: Provides 4 options, mask, entire, background, and subject, to select the color of the mask area, entire picture, background, or subject, respectively.
- remove_background_method: There are two methods of background recognition: BiRefNet and RMBG V1.4.
- invert_mask: Whether to reverse the mask.
- mask_grow: Mask expansion. For subject, a larger value brings the obtained color closer to the color at the center of the body.
Output:
- image: Solid color picture output, the size is the same as the input picture.
- mask: Mask output.
<a id="table1">ImageRewardFilter</a>
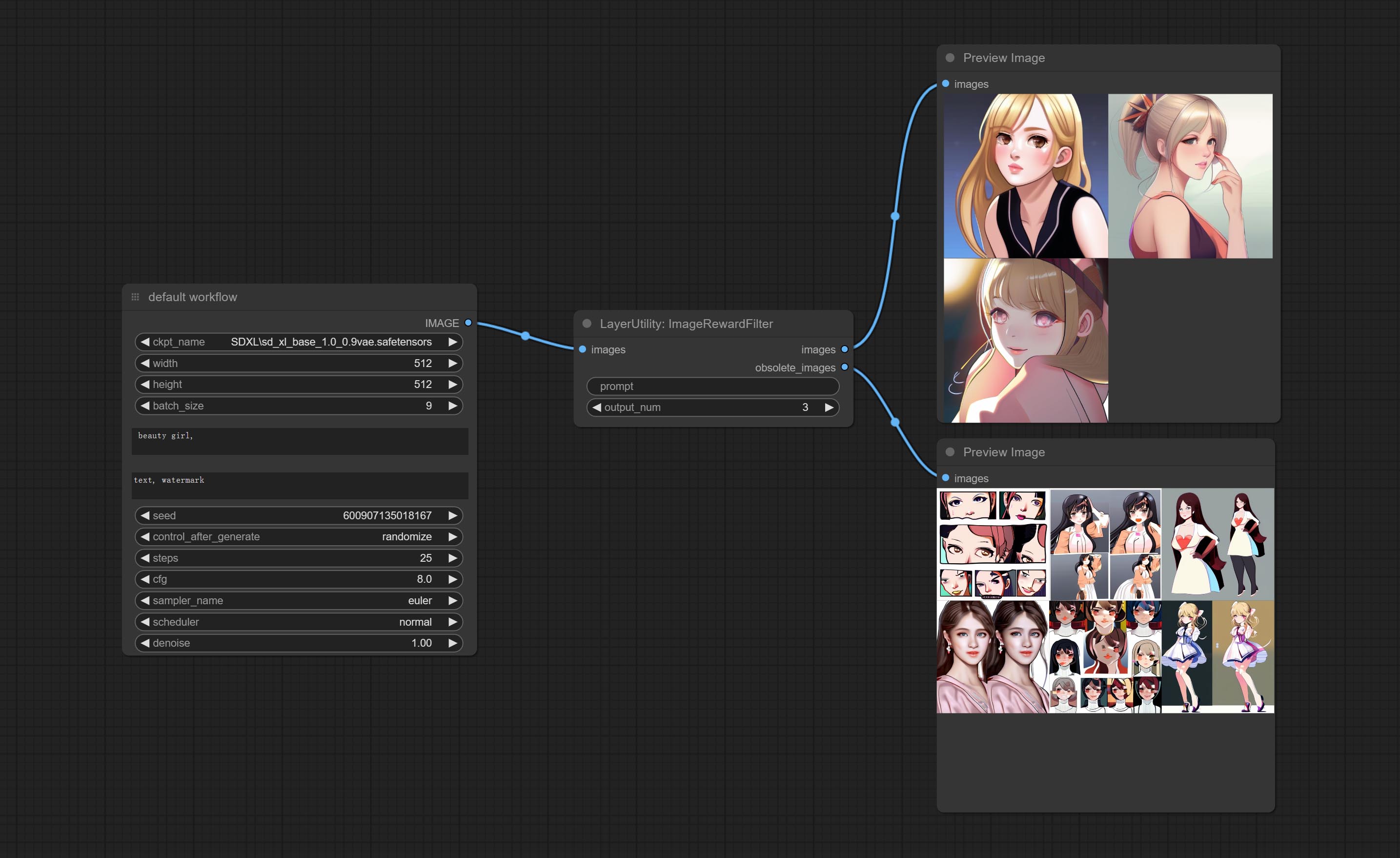
Rating bulk pictures and outputting top-ranked pictures. it used [ImageReward] (https://github.com/THUDM/ImageReward) for image scoring, thanks to the original authors.
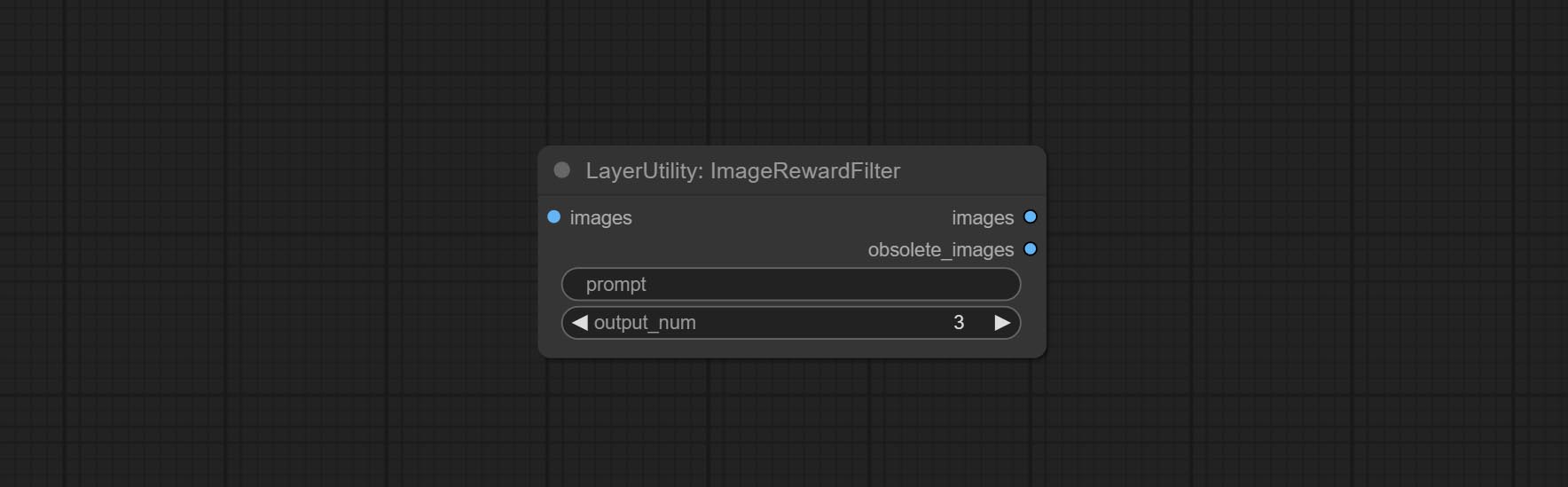
Node options:
- prompt: Optional input. Entering prompt here will be used as a basis to determine how well it matches the picture.
- output_nun: Number of pictures outputted. This value should be less than the picture batch.
Outputs:
- images: Bulk pictures output from high to low in order of rating.
- obsolete_images: Knockout pictures. Also output in order of rating from high to low.
<a id="table1">LaMa</a>
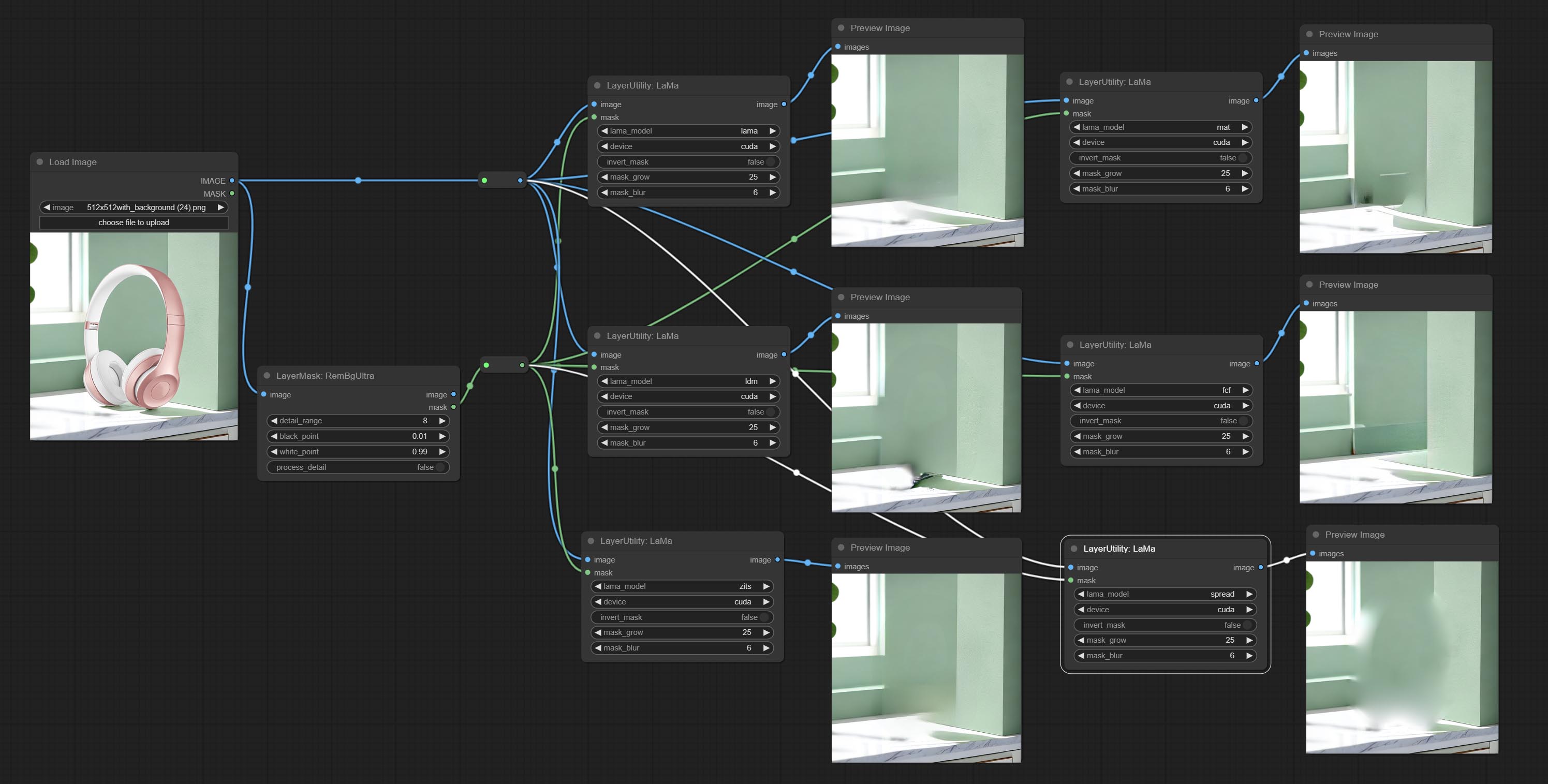
Erase objects from the image based on the mask. this node is repackage of IOPaint, powered by state-of-the-art AI models, thanks to the original author.
It is have LaMa, LDM, ZITS,MAT, FcF, Manga models and the SPREAD method to erase. Please refer to the original link for the introduction of each model.
Please download the model files from lama models(BaiduNetdisk) or lama models(Google Drive) to ComfyUI/models/lama folder.
Node optons:
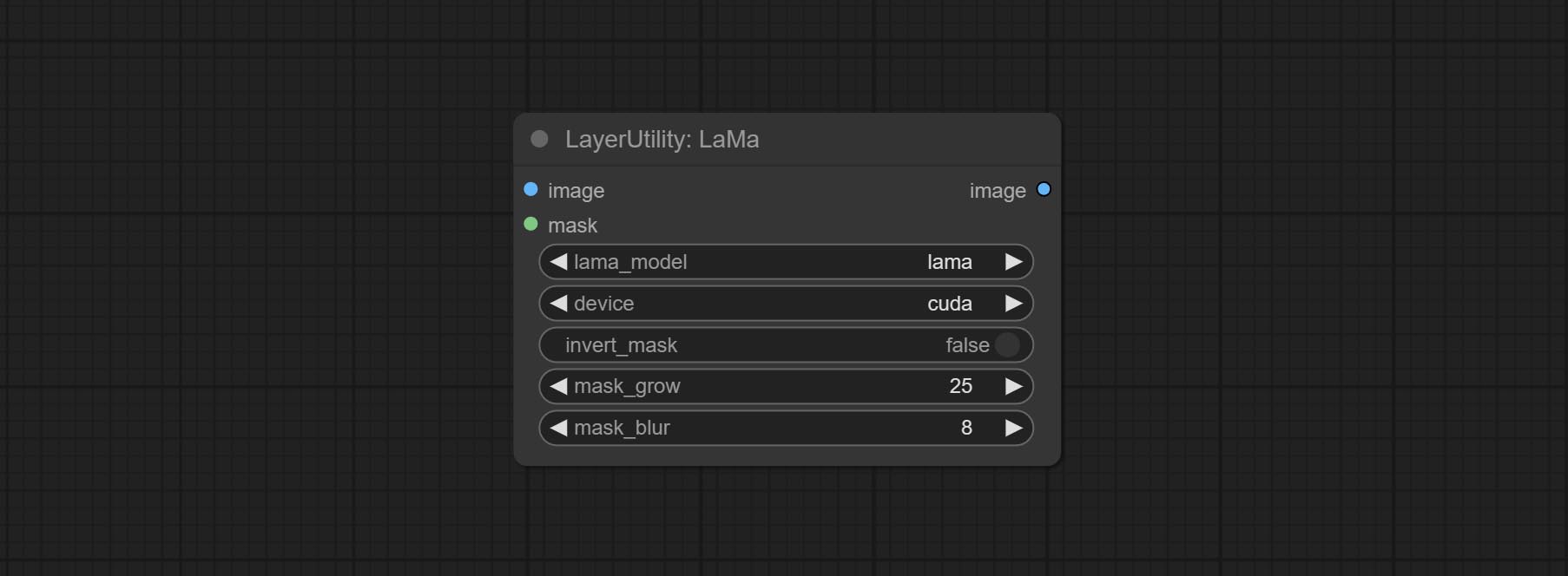
- lama_model: Choose a model or method.
- device: After correctly installing Torch and Nvidia CUDA drivers, using cuda will significantly improve running speed.
- invert_mask: Whether to reverse the mask.
- grow: Positive values expand outward, while negative values contract inward.
- blur: Blur the edge.
<a id="table1">ImageAutoCrop</a>
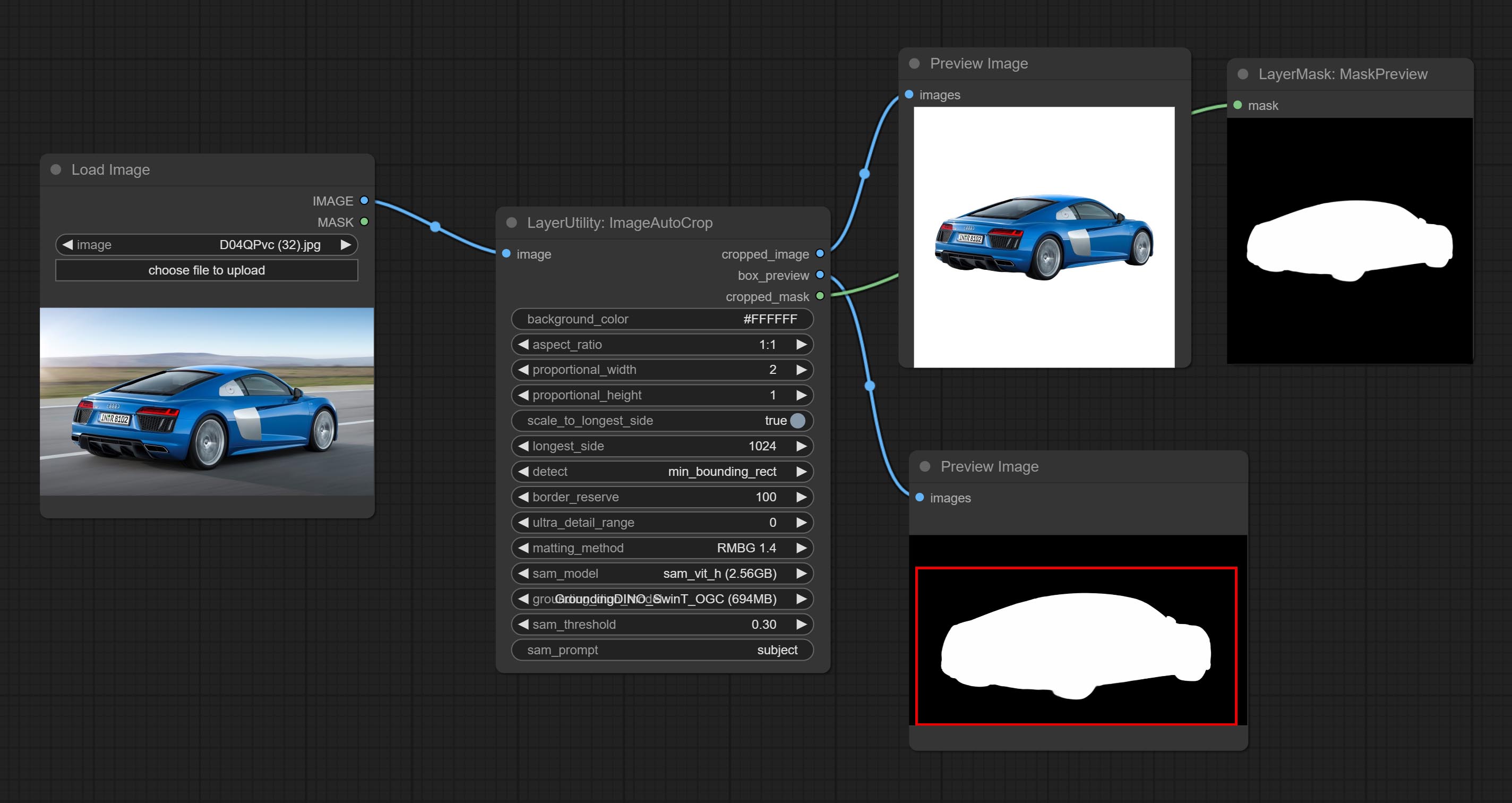
Automatically cutout and crop the image according to the mask. it can specify the background color, aspect ratio, and size for output image. this node is designed to generate the image materials for training models.
*Please refer to the model installation methods for SegmentAnythingUltra and RemBgUltra.
Node options:
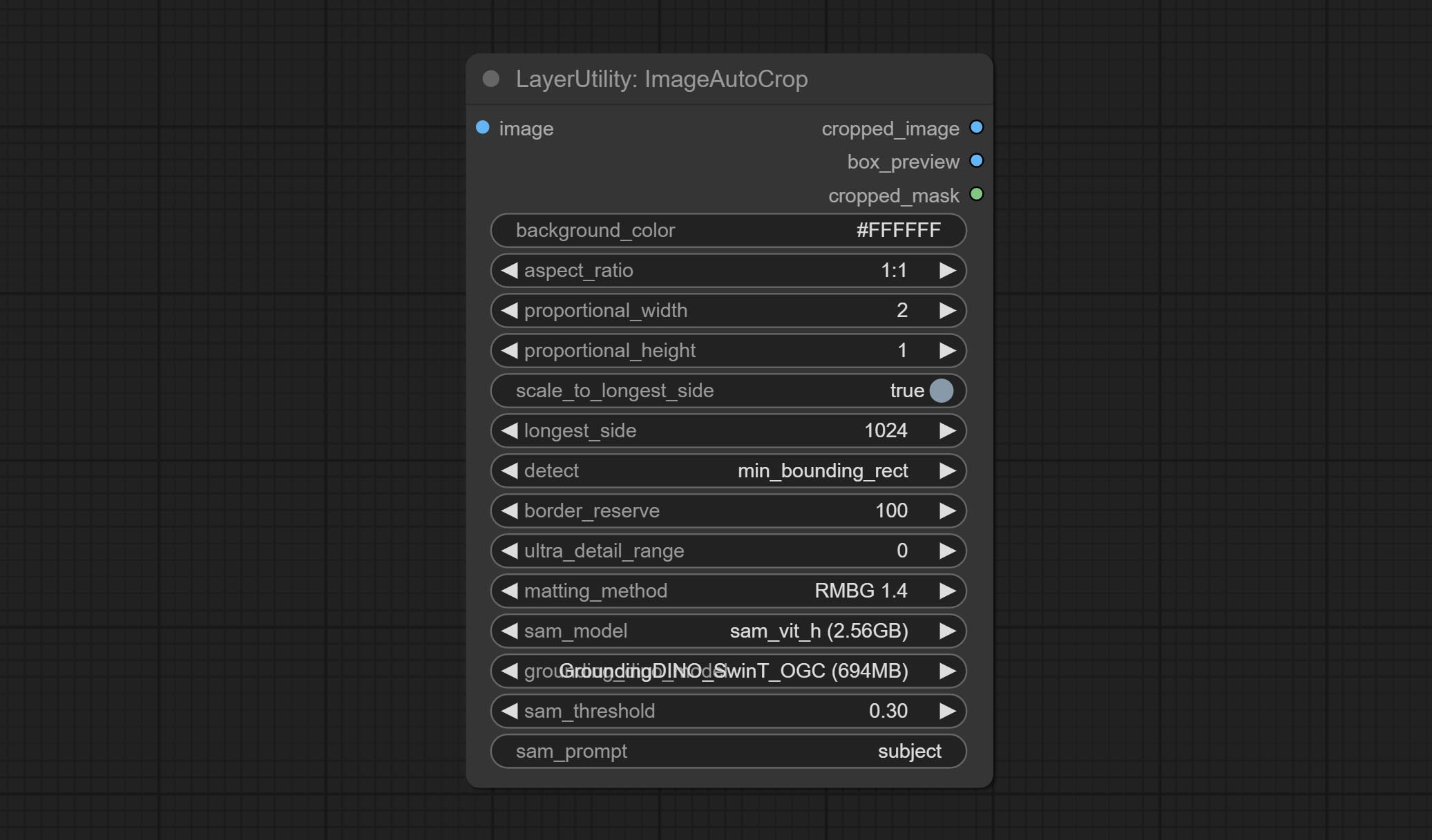
- background_color<sup>4</sup>: The background color.
- aspect_ratio: Here are several common frame ratios provided. alternatively, you can choose "original" to keep original ratio or customize the ratio using "custom".
- proportional_width: Proportional width. if the aspect ratio option is not "custom", this setting will be ignored.
- proportional_height: Proportional height. if the aspect ratio option is not "custom", this setting will be ignored.
- scale_by_longest_side: Allow scaling by long edge size.
- longest_side: When the scale_by_longest_side is set to True, this will be used this value to the long edge of the image. when the original_size have input, this setting will be ignored.
- detect: Detection method, min_bounding_rect is the minimum bounding rectangle, max_inscribed_rect is the maximum inscribed rectangle.
- border_reserve: Keep the border. expand the cutting range beyond the detected mask body area.
- ultra_detail_range: Mask edge ultra fine processing range, 0 is not processed, which can save generation time.
- matting_method: The method of generate masks. There are two methods available: Segment Anything and RMBG 1.4. RMBG 1.4 runs faster.
- sam_model: Select the SAM model used by Segment Anything here.
- grounding_dino_model: Select the Grounding_Dino model used by Segment Anything here.
- sam_threshold: The threshold for Segment Anything.
- sam_prompt: The prompt for Segment Anything.
Output: cropped_image: Crop and replace the background image. box_preview: Crop position preview. cropped_mask: Cropped mask.
<a id="table1">ImageAutoCropV2</a>
The V2 upgrad version of ImageAutoCrop, it has made the following changes based on the previous version:
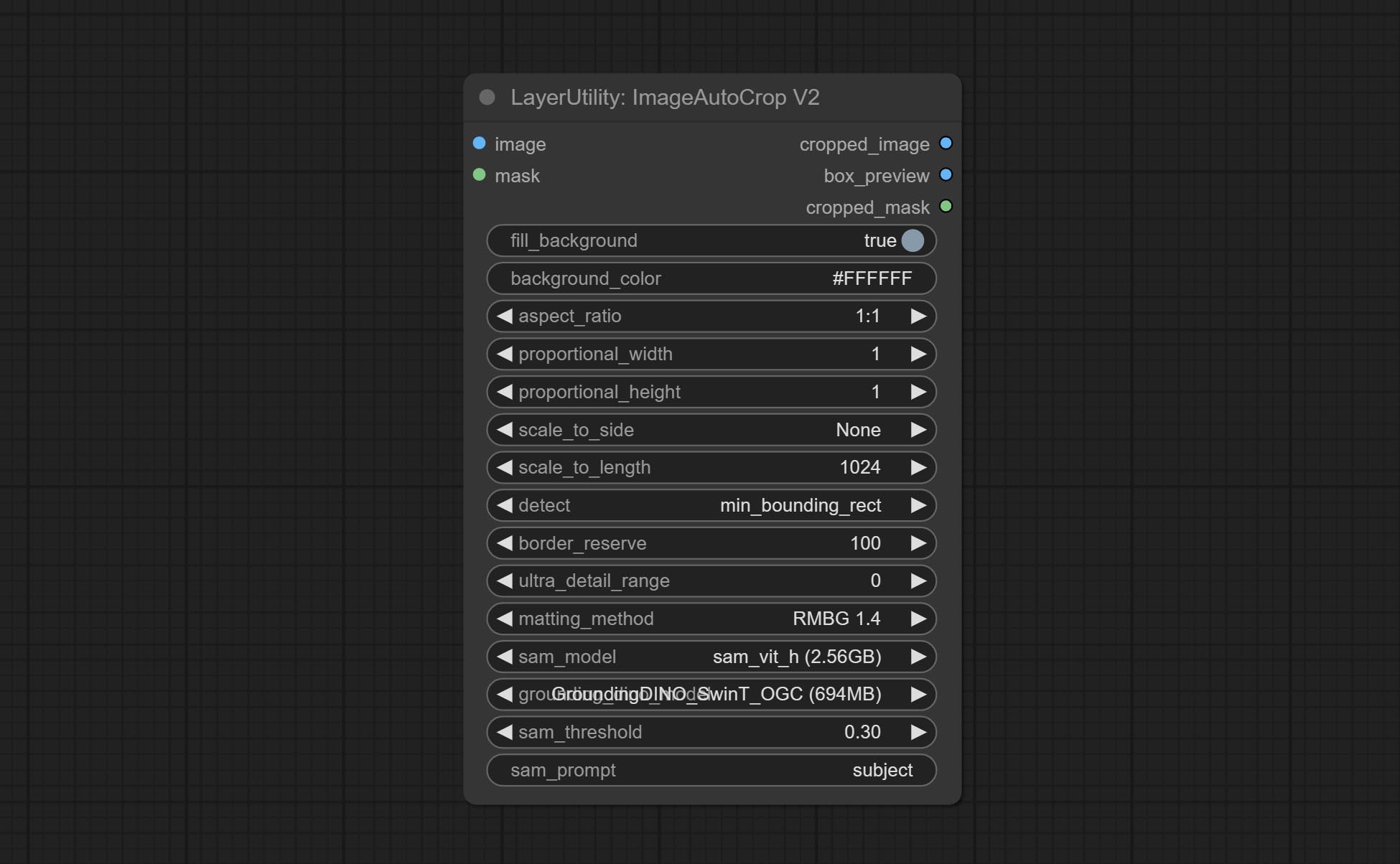
- Add optional input for mask. when there is a mask input, use that input directly to skip the built-in mask generation.
- Add
fill_background. When set to False, the background will not be processed and any parts beyond the frame will not be included in the output range. aspect_ratioadds theoriginaloption.- scale_by: Allow scaling by specified dimensions for longest, shortest, width, or height.
- scale_by_length: The value here is used as
scale_byto specify the length of the edge.
<a id="table1">ImageAutoCropV3</a>
Automatically crop the image to the specified size. You can input a mask to preserve the specified area of the mask. This node is designed to generate image materials for training the model.
Node Options:
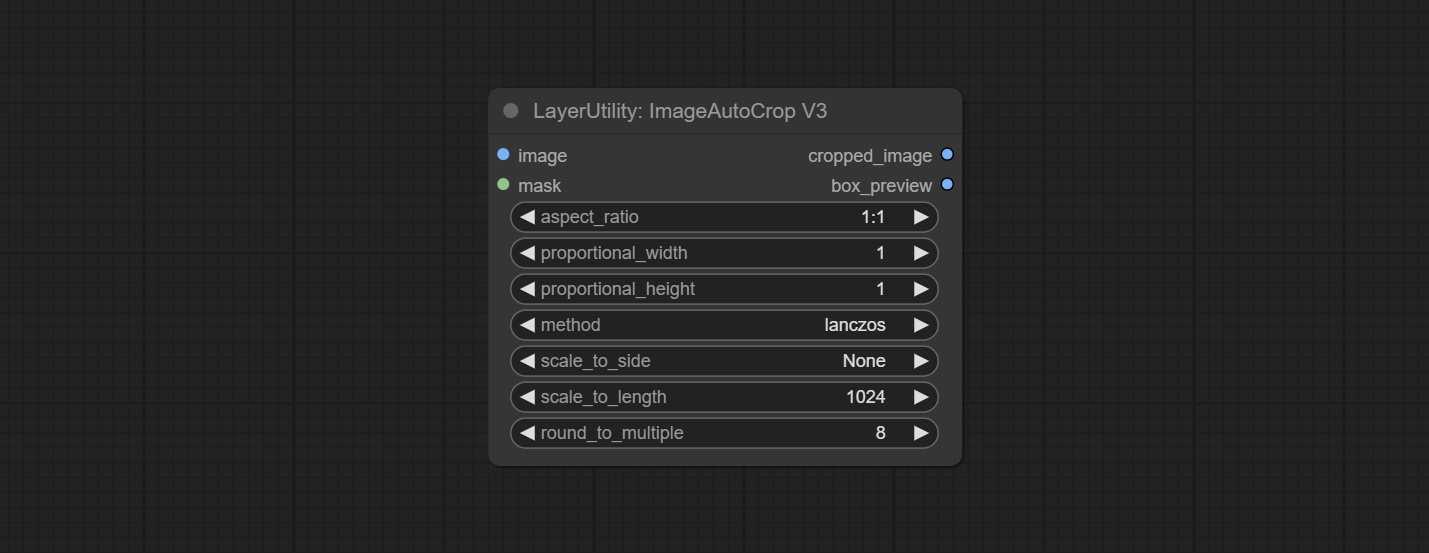
- image: The input image.
- mask: Optional input mask. The masking part will be preserved within the range of the cutting aspect ratio.
- aspect_ratio: The aspect ratio of the output. Here are common frame ratios provided, with "custom" being the custom ratio and "original" being the original frame ratio.
- proportional_width: Proportionally wide. If the aspect_ratio option is not 'custom', this setting will be ignored.
- proportional_height: High proportion. If the aspect_ratio option is not 'custom', this setting will be ignored.
- method: Scaling sampling methods include Lanczos, Bicubic, Hamming, Bilinear, Box, and Nearest.
- scale_to_side: Allow scaling to be specified by long side, short side, width, height, or total pixels.
- scale_to_length: The value here is used as the scale_to-side to specify the length of the edge or the total number of pixels (kilo pixels).
- round_to_multiple: Multiply to the nearest whole. For example, if set to 8, the width and height will be forcibly set to multiples of 8.
Outputs: cropped_image: The cropped image. box_preview: Preview of cutting position.
<a id="table1">SaveImagePlus</a>
Enhanced save image node. You can customize the directory where the picture is saved, add a timestamp to the file name, select the save format, set the image compression rate, set whether to save the workflow, and optionally add invisible watermarks to the picture. (Add information in a way that is invisible to the naked eye, and use the ShowBlindWaterMark node to decode the watermark). Optionally output the json file of the workflow.
Node Options:
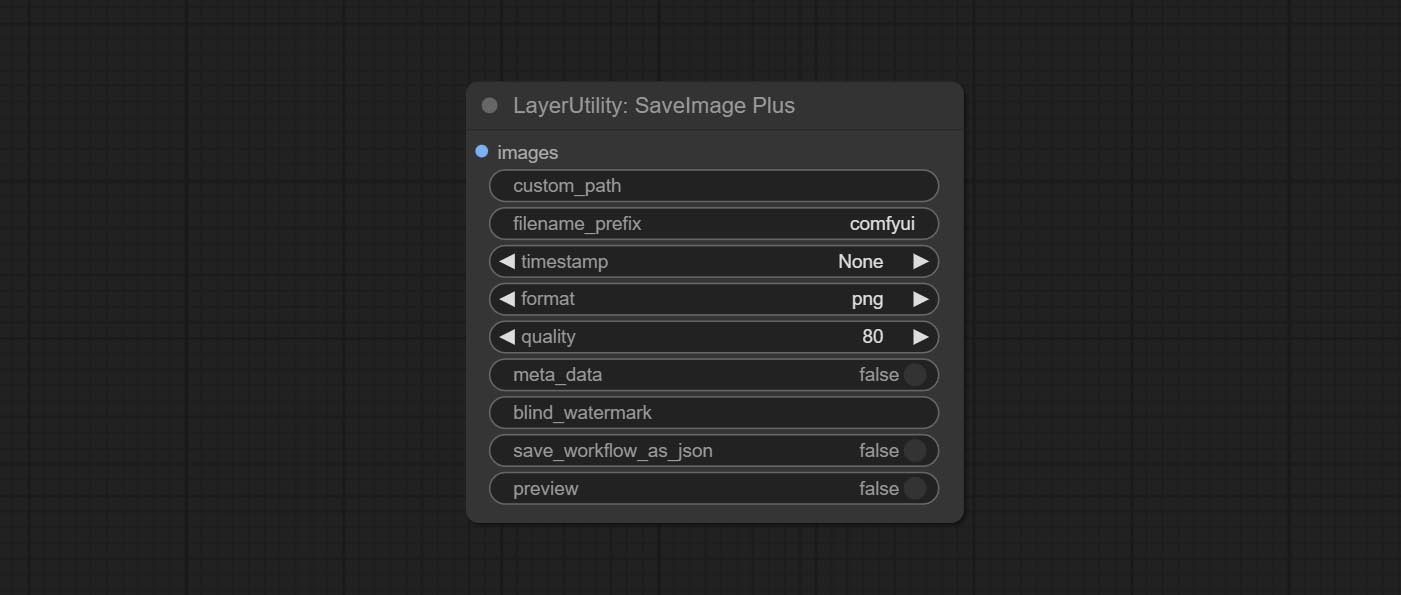
- image: The input image.
- custom_path<sup>*</sup>: User-defined directory, enter the directory name in the correct format. If empty, it is saved in the default output directory of ComfyUI.
- filename_prefix<sup>*</sup>: The prefix of file name.
- timestamp: Timestamp the file name, opting for date, time to seconds, and time to milliseconds.
- format: The format of image save. Currently available in
pngandjpg. Note that only png format is supported for RGBA mode pictures. - quality: Image quality, the value range 10-100, the higher the value, the better the picture quality, the volume of the file also correspondingly increases.
- meta_data: Whether to save metadata to png file, that is workflow information. Set this to false if you do not want the workflow to be leaked.
- blind_watermark: The text entered here (does not support multilingualism) will be converted into a QR code and saved as an invisible watermark. Use
ShowBlindWaterMarknode can decode watermarks. Note that pictures with watermarks are recommended to be saved in png format, and lower-quality jpg format will cause watermark information to be lost. - save_workflow_as_json: Whether the output workflow is a json file at the same time (the output json is in the same directory as the picture).
- preview: Preview switch.
<sup>*</sup> Enter%date for the current date (YY-mm-dd) and %time for the current time (HH-MM-SS). You can enter / for subdirectories. For example, %date/name_%tiem will output the image to the YY-mm-dd folder, with name_HH-MM-SS as the file name prefix.
<a id="table1">SaveImagePlusV2</a>
Added custom file name and dpi options on the SaveImagePlus node.
NodeOptions:
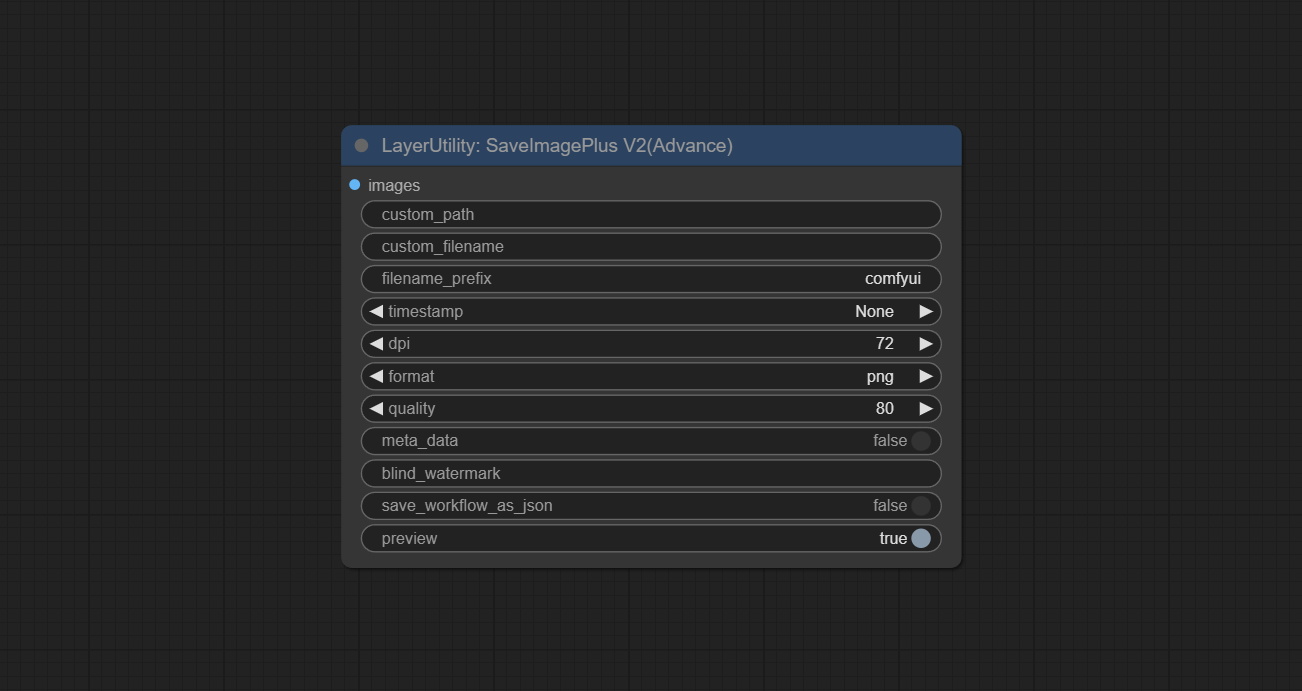
- custom_filename<sup>*</sup>: User defined file name, if entered here, will be used as the file name. Please note that duplicate files will be overwritten. If this is empty, use the file name prefix and timestamp as the file name.
- dpi: Set the DPI value of the image file.
<sup>*</sup> Enter%date for the current date (YY-mm-dd) and %time for the current time (HH-MM-SS). You can enter / for subdirectories. For example, %date/name_%tiem will output the image to the YY-mm-dd folder, with name_HH-MM-SS as the file name prefix.
<a id="table1">AddBlindWaterMark</a>

Add an invisible watermark to a picture. Add the watermark image in a way that is invisible to the naked eye, and use the ShowBlindWaterMark node to decode the watermark.
Node Options:
- iamge: The input image.
- watermark_image: Watermark image. The image entered here will automatically be converted to a square black and white image as a watermark. It is recommended to use a QR code as a watermark.
<a id="table1">ShowBlindWaterMark</a>
Decoding the invisible watermark added to the AddBlindWaterMark and SaveImagePlus nodes.
<a id="table1">CreateQRCode</a>
Generate a square QR code picture.
Node Options:
- size: The side length of image.
- border: The size of the border around the QR code, the larger the value, the wider the border.
- text: Enter the text content of the QR code here, and multi-language is not supported.
<a id="table1">DecodeQRCode</a>
Decoding the QR code.
Node Options:
- image: The input QR code image.
- pre_blur: Pre-blurring, you can try to adjust this value for QR codes that are difficult to identify.
<a id="table1">LoadPSD</a>

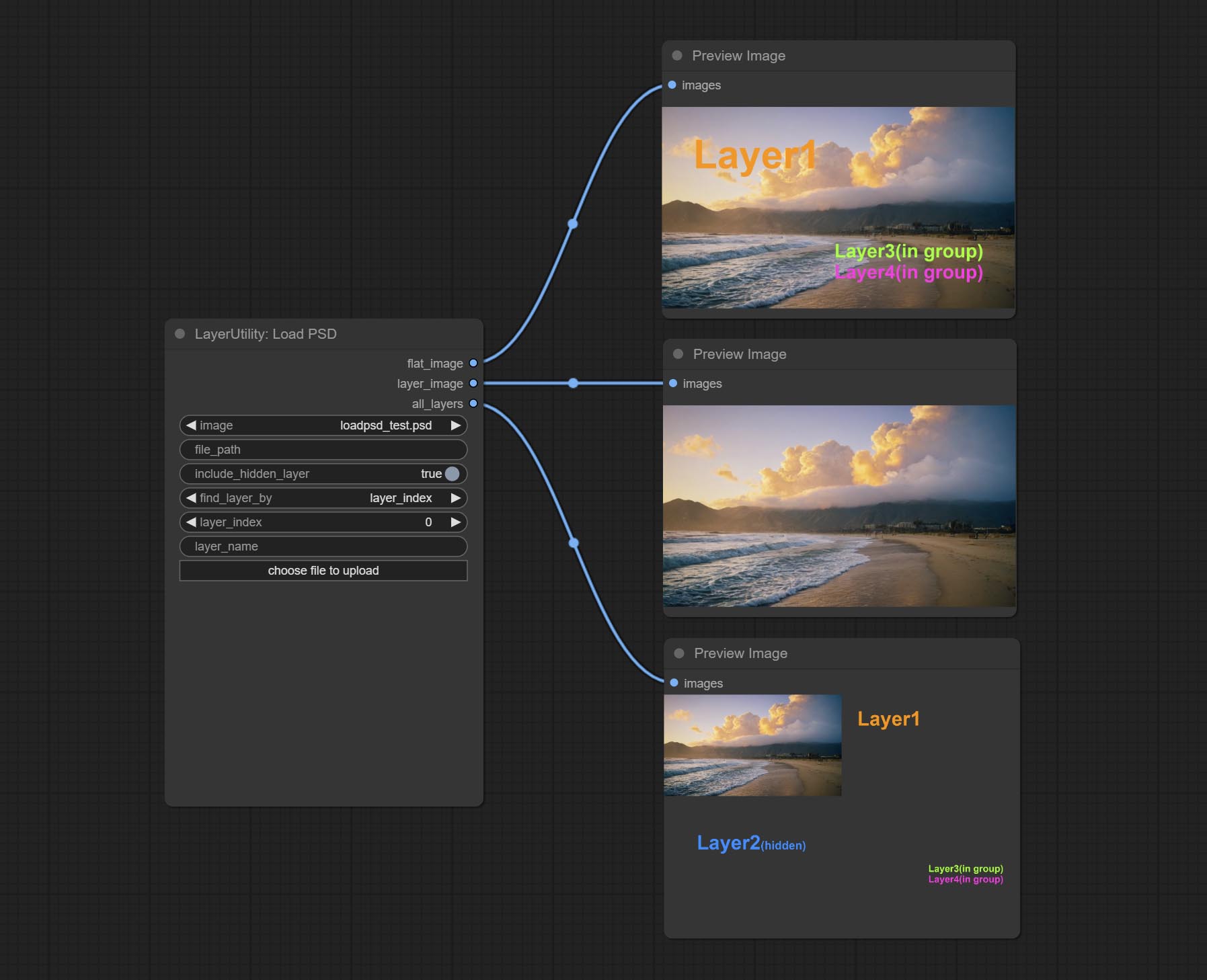
Load the PSD format file and export the layers.
Note that this node requires the installation of the psd_tools dependency package, If error occurs during the installation of psd_tool, such as ModuleNotFoundError: No module named 'docopt' , please download docopt's whl and manual install it.
Node Options:
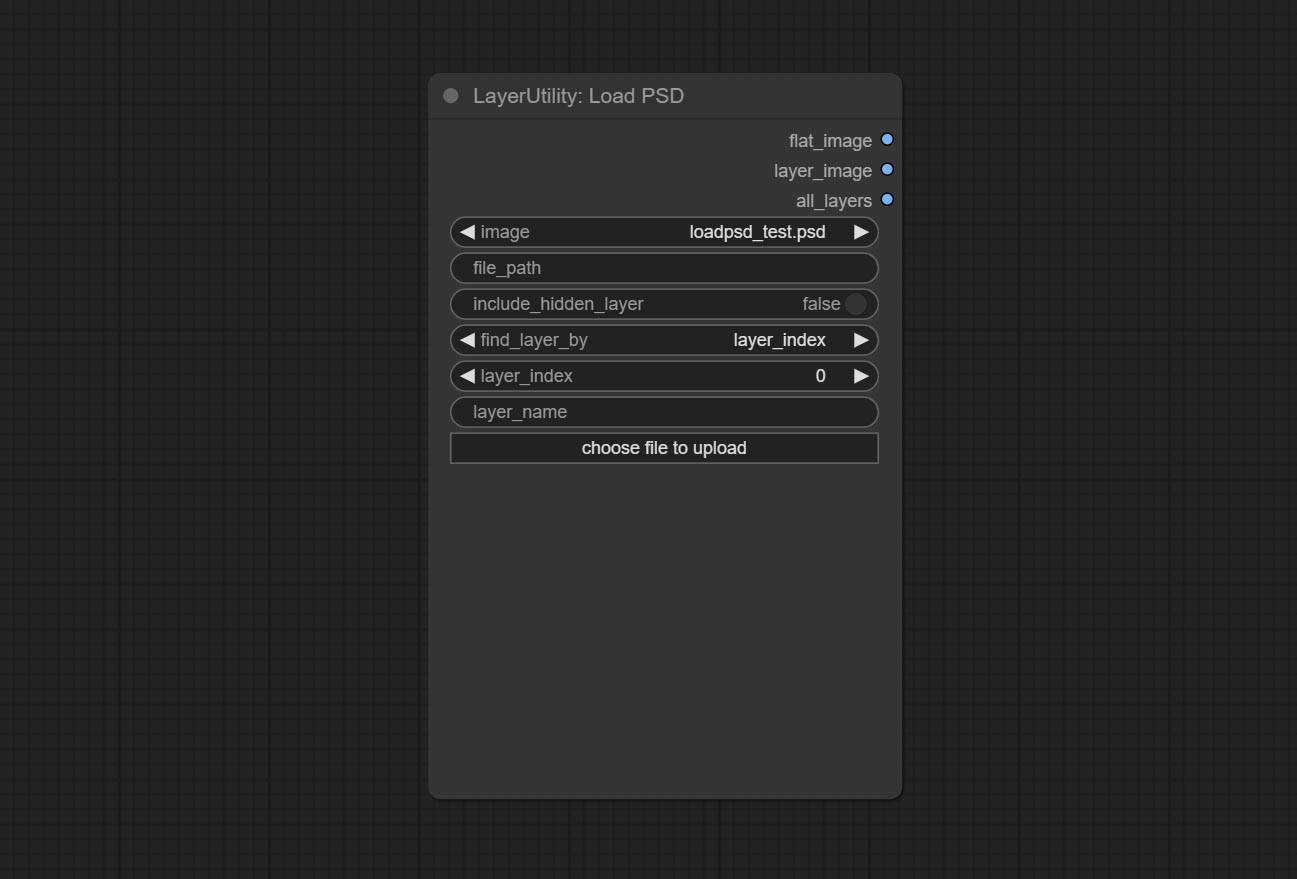
- image: Here is a list of *.psd files under
ComfyUI/input, where previously loaded psd images can be selected. - file_path: The complete path and file name of the psd file.
- include_hidden_layer: whether include hidden layers.
- find_layer_by: The method for finding layers can be selected by layer key number or layer name. Layer groups are treated as one layer.
- layer_index: The layer key number, where 0 is the bottom layer, is incremented sequentially. If include_hiddenlayer is set to false, hidden layers are not counted. Set to -1 to output the top layer.
- layer_name: Layer name. Note that capitalization and punctuation must match exactly.
Outputs: flat_image: PSD preview image. layer_iamge: Find the layer output. all_layers: Batch images containing all layers.
<a id="table1">SD3NegativeConditioning</a>
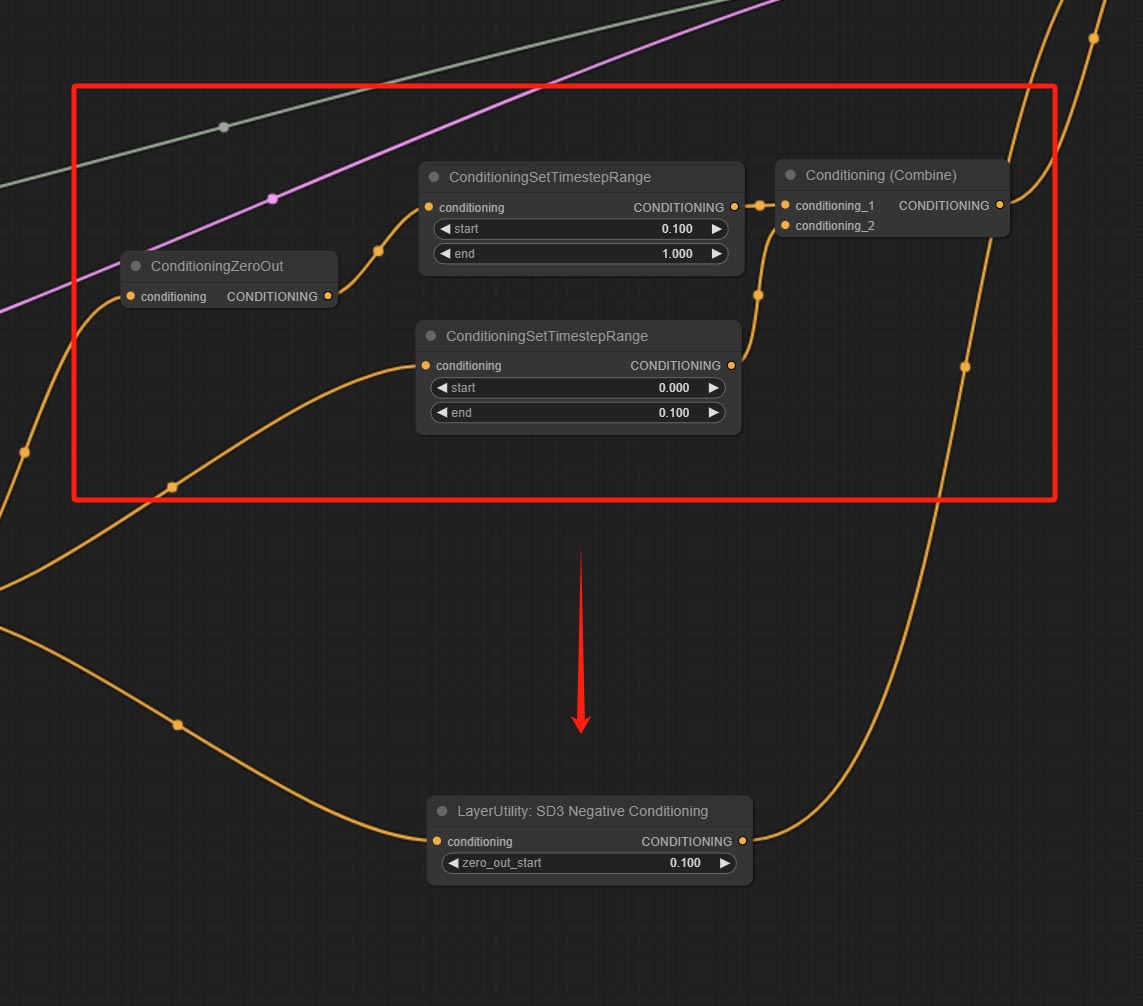
Encapsulate the four nodes of Negative Condition in SD3 into a separate node.
Node Options:
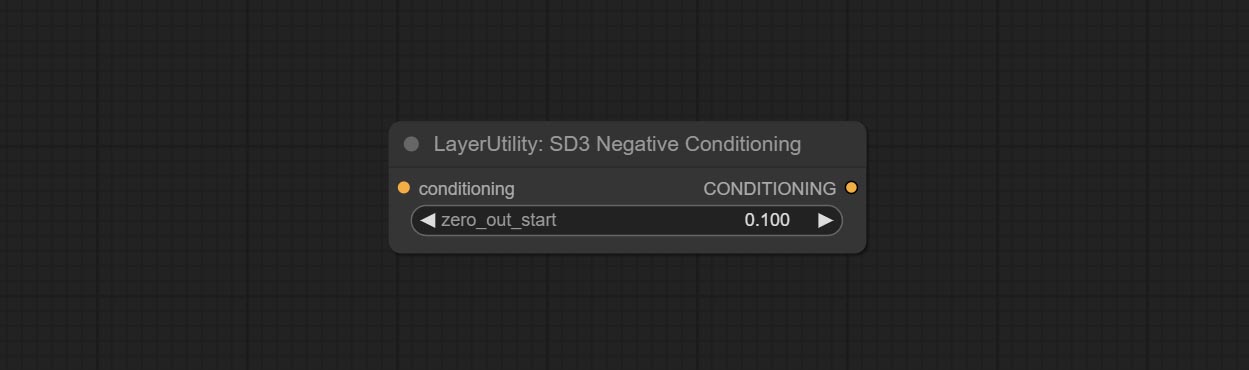
- zero_out_start: Set the ConditioningSetTimestepRange start value for Negative ConditioningZeroOut, which is the same as the ConditioningSetTimestepRange end value for Negative.
<a id="table1">BenUltra</a>
It is the implementation of PramaLLC/BEN project in ComfyUI. Thank you to the original author.
Download all files from huggingface or BaiduNetdisk and copy to ComfyUI/models/BEN folder.

Node Options:

- ben_model: Ben model input. There are two models to choose: BEN_Base and BEN2_base.
- image: Image input.
- detail_method: Edge processing methods. provides VITMatte, VITMatte(local), PyMatting, GuidedFilter. If the model has been downloaded after the first use of VITMatte, you can use VITMatte (local) afterwards.
- detail_erode: Mask the erosion range inward from the edge. the larger the value, the larger the range of inward repair.
- detail_dilate: The edge of the mask expands outward. the larger the value, the wider the range of outward repair.
- black_point: Edge black sampling threshold.
- white_point: Edge white sampling threshold.
- process_detail: Set to false here will skip edge processing to save runtime.
- max_megapixels: Set the maximum size for VitMate operations.
<a id="table1">LoadBenModel</a>
Load the BEN model.
Node Options:
- model: Select the model. Currently, only the Ben_Sase model is available for selection.
<a id="table1">SegmentAnythingUltra</a>
Improvements to ComfyUI Segment Anything, thanks to the original author.
*Please refer to the installation of ComfyUI Segment Anything to install the model. If ComfyUI Segment Anything has been correctly installed, you can skip this step.
- From here download the config.json,model.safetensors,tokenizer_config.json,tokenizer.json and vocab.txt 5 files to
ComfyUI/models/bert-base-uncasedfolder. - Download GroundingDINO_SwinT_OGC config file, GroundingDINO_SwinT_OGC model,
GroundingDINO_SwinB config file, GroundingDINO_SwinB model to
ComfyUI/models/grounding-dinofolder. - Download sam_vit_h,sam_vit_l,
sam_vit_b, sam_hq_vit_h,
sam_hq_vit_l, sam_hq_vit_b,
mobile_sam to
ComfyUI/models/samsfolder. *Or download them from GroundingDino models on BaiduNetdisk and SAM models on BaiduNetdisk .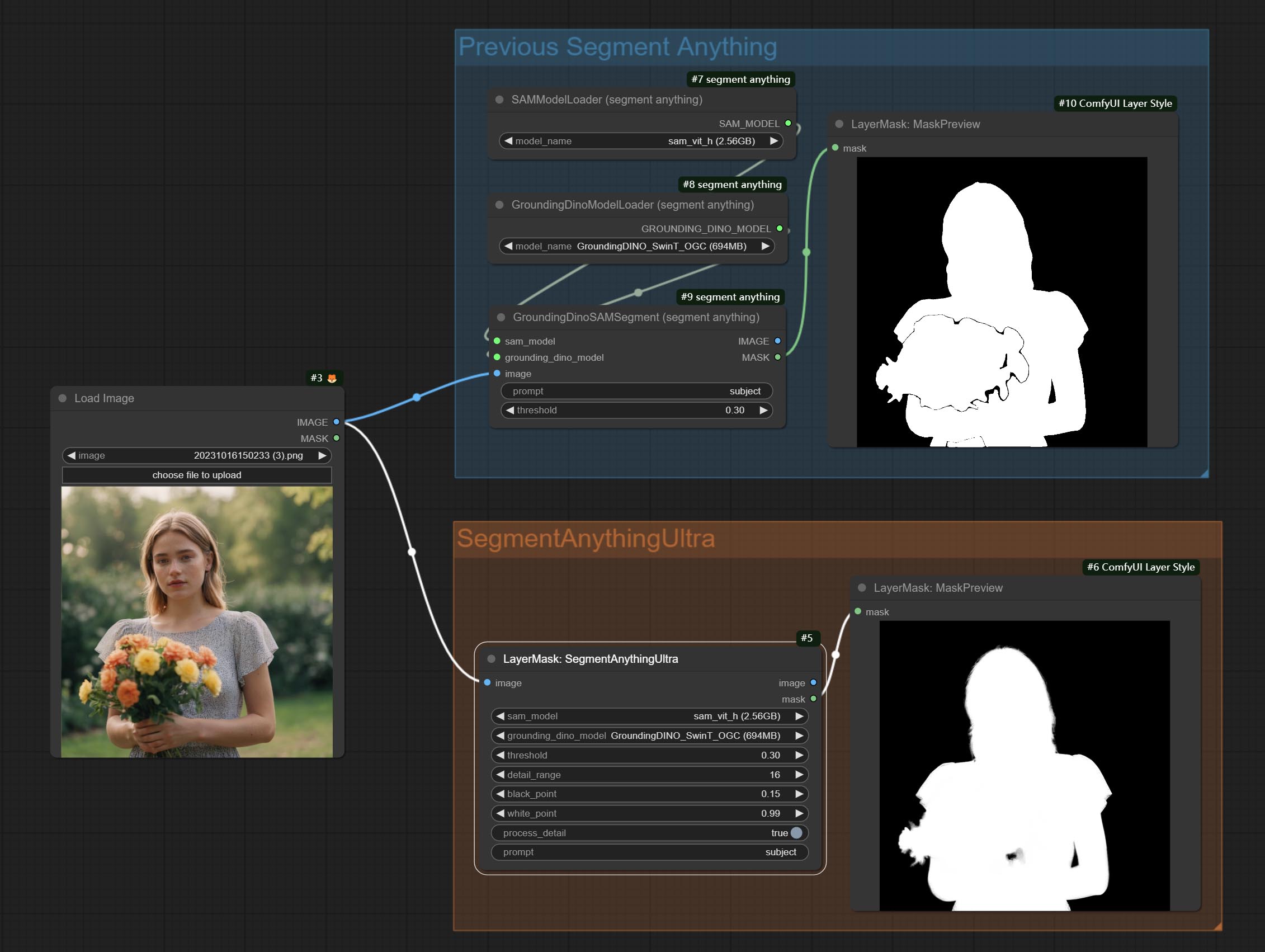
Node options:
- sam_model: Select the SAM model.
- ground_dino_model: Select the Grounding DINO model.
- threshold: The threshold of SAM.
- detail_range: Edge detail range.
- black_point: Edge black sampling threshold.
- white_point: Edge white sampling threshold.
- process_detail: Set to false here will skip edge processing to save runtime.
- prompt: Input for SAM's prompt.
- cache_model: Set whether to cache the model.
<a id="table1">SegmentAnythingUltraV2</a>
The V2 upgraded version of SegmentAnythingUltra has added the VITMatte edge processing method.(Note: Images larger than 2K in size using this method will consume huge memory)
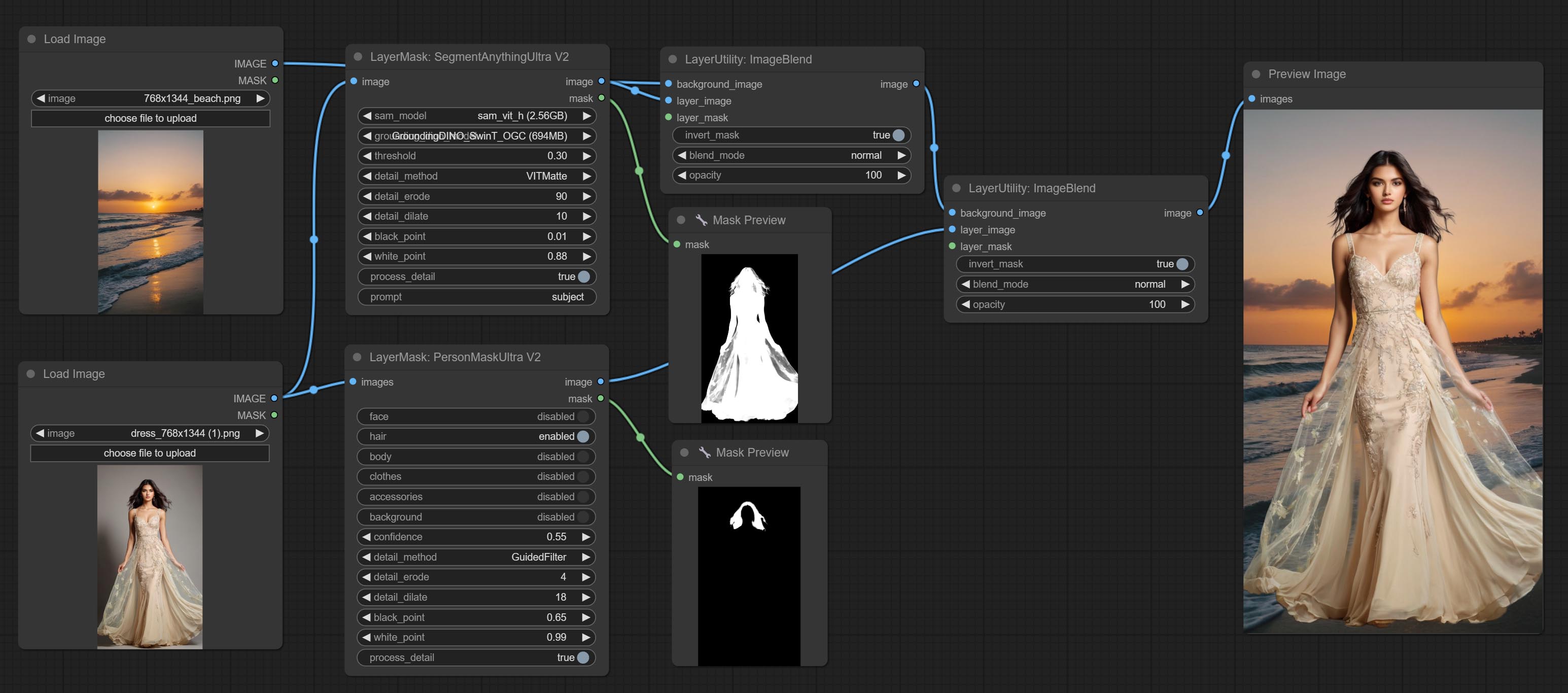
On the basis of SegmentAnythingUltra, the following changes have been made:
- detail_method: Edge processing methods. provides VITMatte, VITMatte(local), PyMatting, GuidedFilter. If the model has been downloaded after the first use of VITMatte, you can use VITMatte (local) afterwards.
- detail_erode: Mask the erosion range inward from the edge. the larger the value, the larger the range of inward repair.
- detail_dilate: The edge of the mask expands outward. the larger the value, the wider the range of outward repair.
- device: Set whether the VitMatte to use cuda.
- max_megapixels: Set the maximum size for VitMate operations.
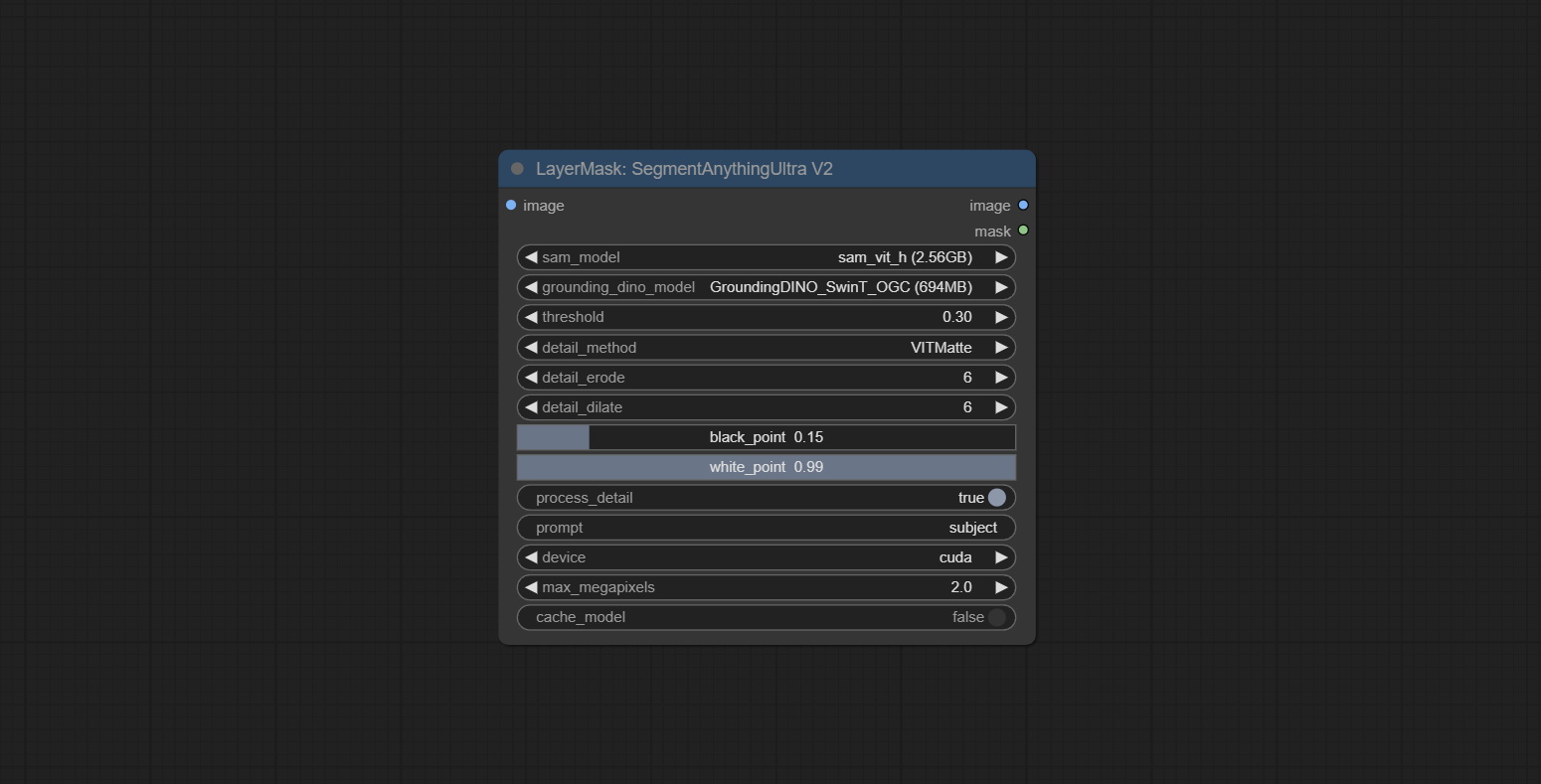
<a id="table1">SegmentAnythingUltraV3</a>
Separate model loading from inference nodes to avoid duplicate model loading when using multiple SAM nodes.
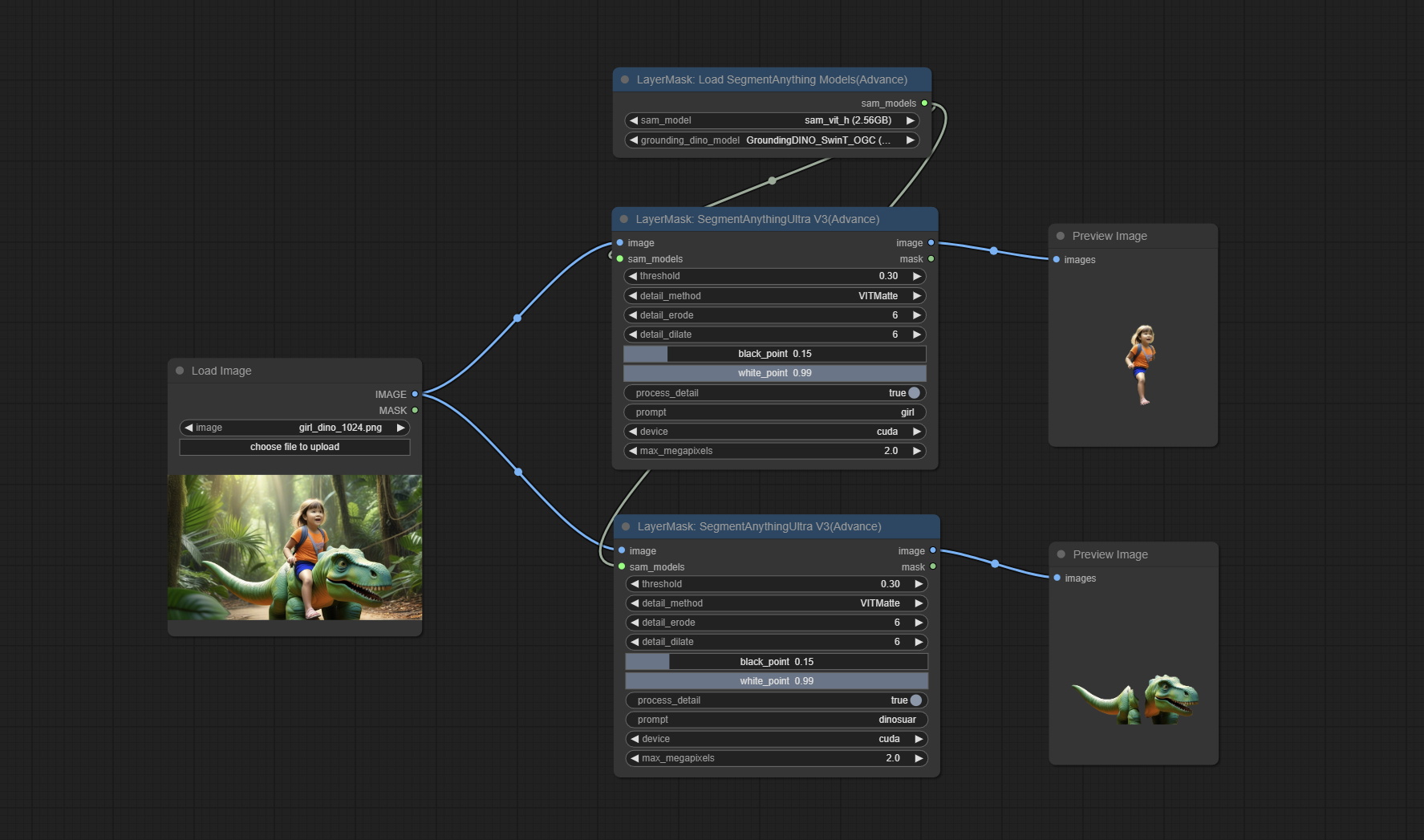
Node Options:
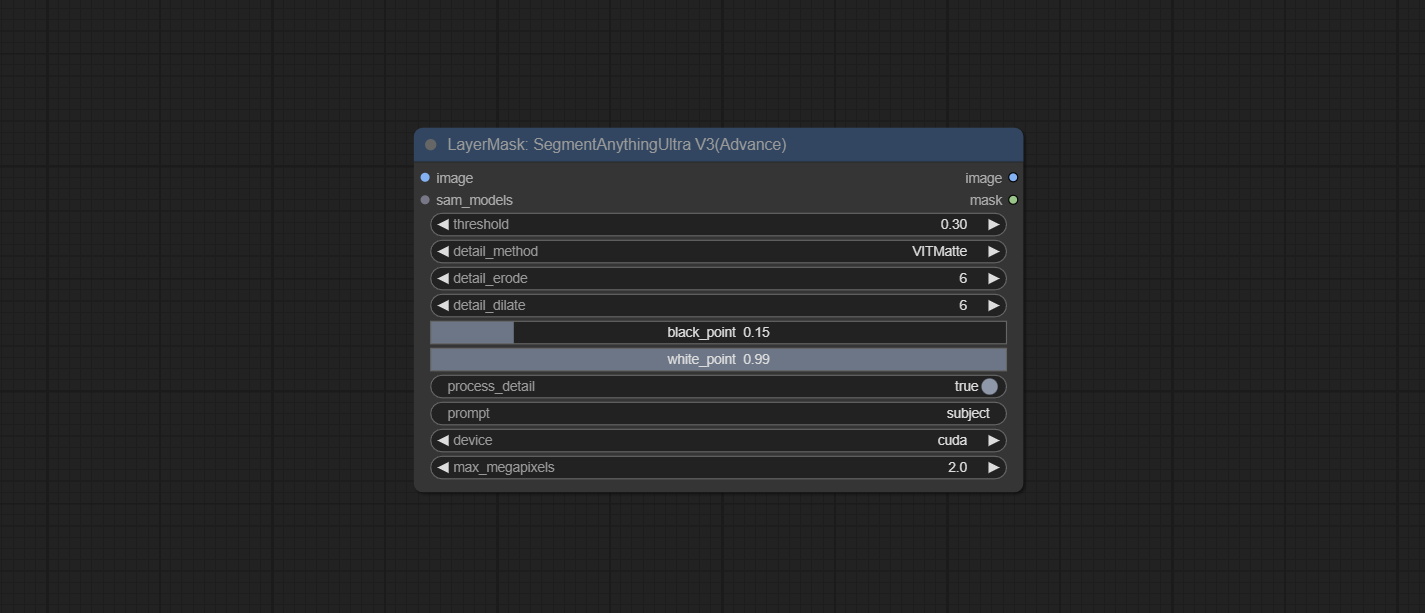 Same as SegmentAnythingUltra, removed
Same as SegmentAnythingUltra, removed sam_comodel and ground-dino_comodel, changed them to be obtained from node input.
<a id="table1">LoadSegmentAnythingModels</a>
Load SegmentAnything models.
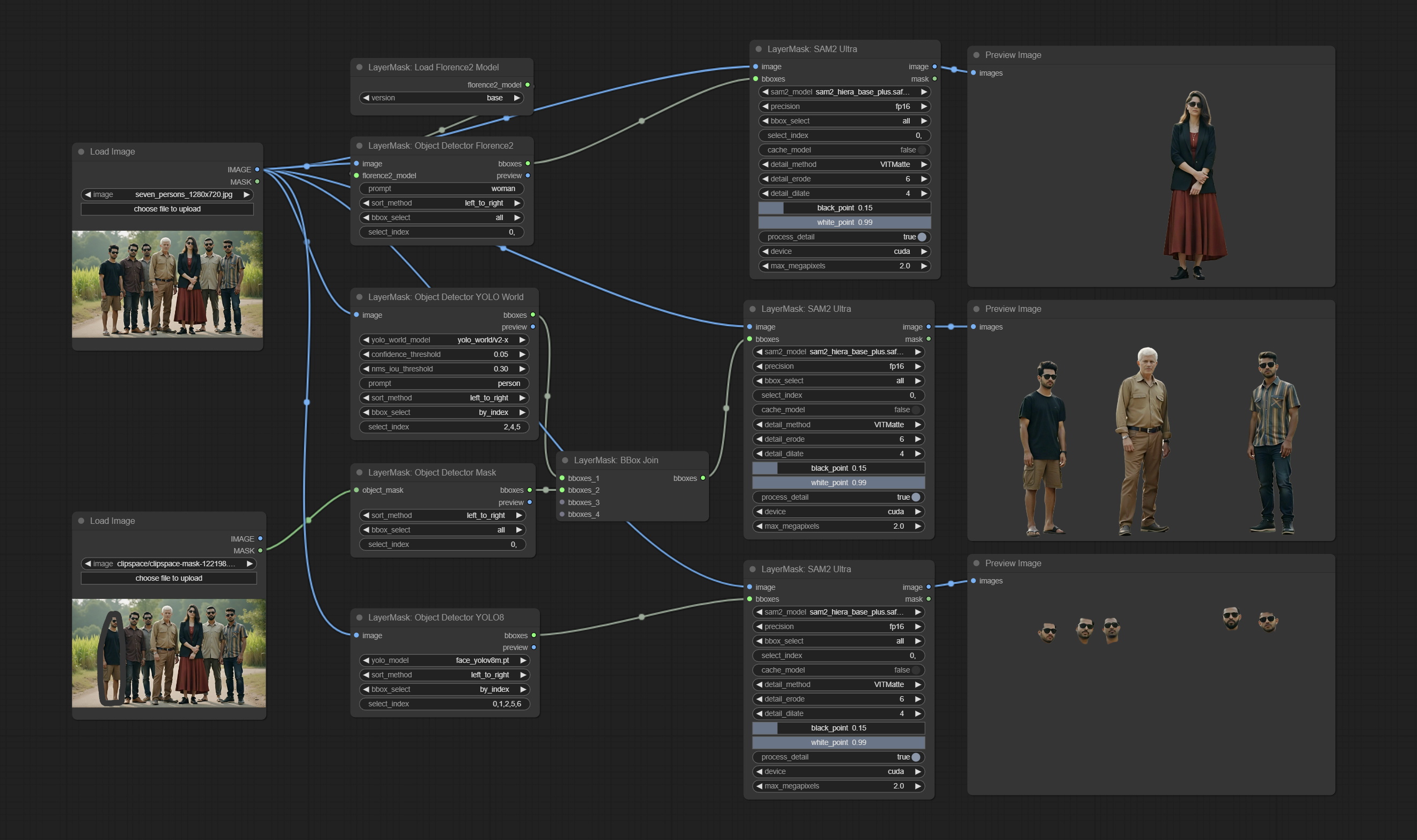
<a id="table1">SAM2Ultra</a>
This node is modified from kijai/ComfyUI-segment-anything-2. Thank to kijai for making significant contributions to the Comfyui community.
SAM2 Ultra node only support single image. If you need to process multiple images, please first convert the image batch to image list.
*Download models from BaiduNetdisk or huggingface.co/Kijai/sam2-safetensors and copy to ComfyUI/models/sam2 folder.
Node Options:
- image: The image to segment.
- bboxes: Input recognition box data.
- sam2_model: Select the SAM2 model.
- presicion: Model's persicion. can be selected from fp16, bf16, and fp32.
- bbox_select: Select the input box data. There are three options: "all" to select all, "first" to select the box with the highest confidence, and "by_index" to specify the index of the box.
- select_index: This option is valid when bbox_delect is 'by_index'. 0 is the first one. Multiple values can be entered, separated by any non numeric character, including but not limited to commas, periods, semicolons, spaces or letters, and even Chinese.
- cache_model: Whether to cache the model. After caching the model, it will save time for model loading.
- detail_method: Edge processing methods. provides VITMatte, VITMatte(local), PyMatting, GuidedFilter. If the model has been downloaded after the first use of VITMatte, you can use VITMatte (local) afterwards.
- detail_erode: Mask the erosion range inward from the edge. the larger the value, the larger the range of inward repair.
- detail_dilate: The edge of the mask expands outward. the larger the value, the wider the range of outward repair.
- black_point: Edge black sampling threshold.
- white_point: Edge white sampling threshold.
- process_detail: Set to false here will skip edge processing to save runtime.
- device: Set whether the VitMatte to use cuda.
- max_megapixels: Set the maximum size for VitMate operations.
<a id="table1">SAM2UltraV2</a>
On the basis of SAM2 Ultra nodes, changing the SAM2 model to an external input saves resources when using multiple nodes.
Modified node options:
- sam2_model: SAM2 model input, the model is loaded by the
Load SAM2 Modelnode.
<a id="table1">LoadSAM2Model</a>
Load SAM2 model.
Node Options:
- sam2_model: Select the SAM2 model.
- presicion: Model's persicion. can be selected from fp16, bf16, and fp32.
- device: Set whether to use cuda.
<a id="table1">SAM2VideoUltra</a>
SAM2 Video Ultra node support processing multiple frames of images or video sequences. Please define the recognition box data in the first frame of the sequence to ensure correct recognition.
https://github.com/user-attachments/assets/4726b8bf-9b98-4630-8f54-cb7ed7a3d2c5
https://github.com/user-attachments/assets/b2a45c96-4be1-4470-8ceb-addaf301b0cb
Node Options:
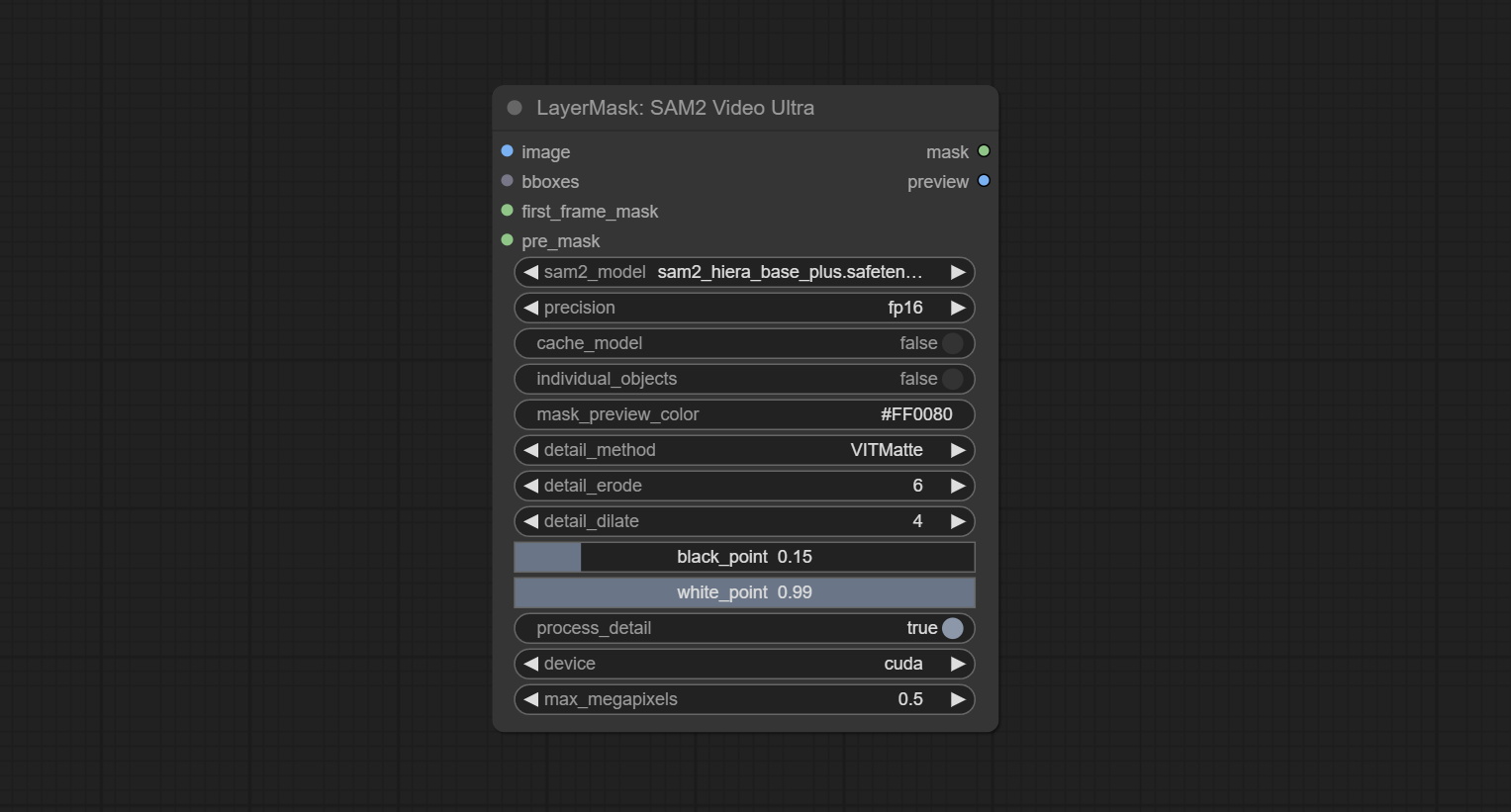
- image: The image to segment.
- bboxes: Optional input of recognition bbox data.
bboxesandfirst_frame_maskmust have least one input. If first_frame_mask inputed, bbboxes will be ignored. - first_frame_mask: Optional input of the first frame mask. The mask will be used as the first frame recognition object.
bboxesandfirst_frame_maskmust have least one input. If first_frame_mask inputed, bbboxes will be ignored. - pre_mask: Optional input mask, which will serve as a propagation focus range limitation and help improve recognition accuracy.
- sam2_model: Select the SAM2 model.
- presicion: Model's persicion. can be selected from fp16 and bf16.
- cache_model: Whether to cache the model. After caching the model, it will save time for model loading.
- individual_object: When set to True, it will focus on identifying a single object. When set to False, attempts will be made to generate recognition boxes for multiple objects.
- mask_preview_color: Display the color of non masked areas in the preview output.
- detail_method: Edge processing methods. Only VITMatte method can be used.
- detail_erode: Mask the erosion range inward from the edge. the larger the value, the larger the range of inward repair.
- detail_dilate: The edge of the mask expands outward. the larger the value, the wider the range of outward repair.
- black_point: Edge black sampling threshold.
- white_point: Edge white sampling threshold.
- process_detail: Set to false here will skip edge processing to save runtime.
- device: Only cuda can be used.
- max_megapixels: Set the maximum size for VitMate operations.A larger size will result in finer mask edges, but it will lead to a significant decrease in computation speed.
<a id="table1">ObjectDetectorGemini</a>
Use Gemini API for object detection.
Apply for your API key on Google AI Studio, And fill it in api_key.ini, this file is located in the root directory of the plug-in, and the default name is api_key.ini.example. to use this file for the first time, you need to change the file suffix to .ini. Open it using text editing software, fill in your API key after google_api_key= and save it.
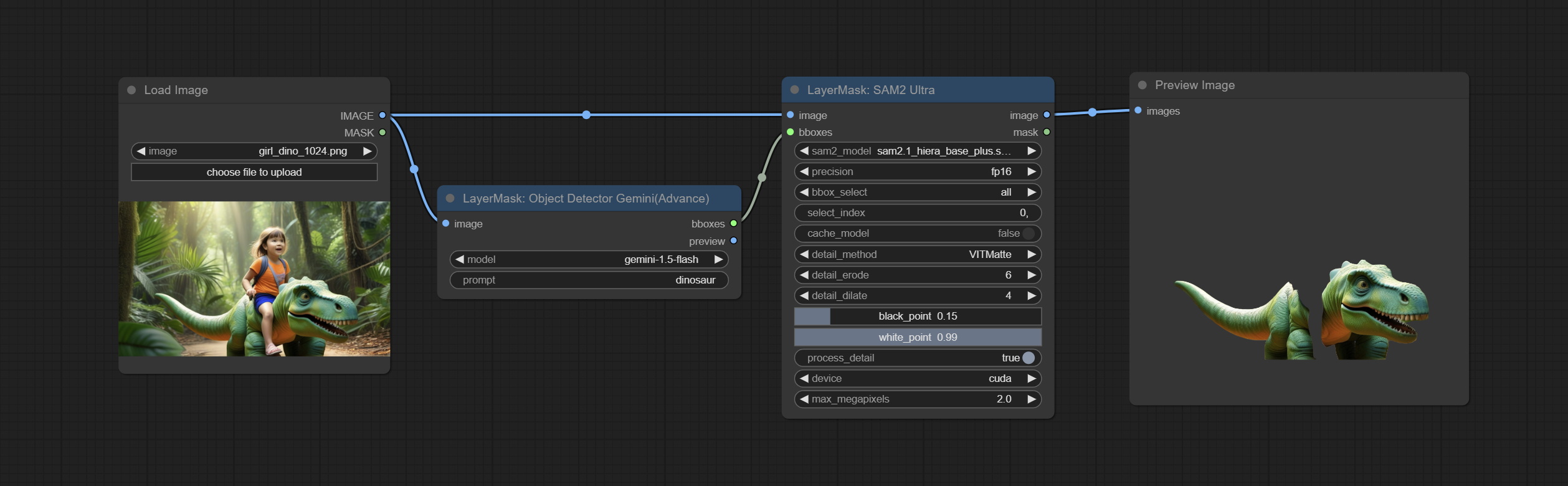
Node Options:
- image: The input image.
- model: Selete Gemini model.
- prompt: Describe the object that needs to be identified.
<a id="table1">ObjectDetectorGeminiV2</a>
On the basis of the ObjectDetectorGemini node, change to using a new google-genai dependency package that supports the latest gemini-2.5-pro-exp-03-25 model.
Node Options:
Same as ObjectDetectorGemini
<a id="table1">ObjectDetectorFL2</a>
Use the Florence2 model to identify objects in images and output recognition box data.
*Download models from BaiduNetdisk and copy to ComfyUI/models/florence2 folder.
Node Options:
- image: The image to segment.
- florence2_model: Florence2 model, it from LoadFlorence2Model node.
- prompt: Describe the object that needs to be identified.
- sort_method: The selection box sorting method has 4 options: "left_to_right", "top_to_bottom", "big_to_small" and "confidence".
- bbox_select: Select the input box data. There are three options: "all" to select all, "first" to select the box with the highest confidence, and "by_index" to specify the index of the box.
- select_index: This option is valid when bbox_delect is 'by_index'. 0 is the first one. Multiple values can be entered, separated by any non numeric character, including but not limited to commas, periods, semicolons, spaces or letters, and even Chinese.
<a id="table1">ObjectDetectorYOLOWorld</a>
(Obsoleted. If you want to continue using it, you need to manually install the dependency package)
Due to potential installation issues with dependency packages, this node has been obsoleted. To use, please manually install the following dependency packages:
pip install inference-cli>=0.13.0
pip install inference-gpu[yolo-world]>=0.13.0
Use the YOLO-World model to identify objects in images and output recognition box data.
*Download models from BaiduNetdisk or GoogleDrive and copy to ComfyUI/models/yolo-world folder.
Node Options:
- image: The image to segment.
- confidence_threshold: The threshold of confidence.
- nms_iou_threshold: The threshold of Non-Maximum Suppression.
- prompt: Describe the object that needs to be identified.
- sort_method: The selection box sorting method has 4 options: "left_to_right", "top_to_bottom", "big_to_small" and "confidence".
- bbox_select: Select the input box data. There are three options: "all" to select all, "first" to select the box with the highest confidence, and "by_index" to specify the index of the box.
- select_index: This option is valid when bbox_delect is 'by_index'. 0 is the first one. Multiple values can be entered, separated by any non numeric character, including but not limited to commas, periods, semicolons, spaces or letters, and even Chinese.
<a id="table1">ObjectDetectorYOLO8</a>
Use the YOLO-8 model to identify objects in images and output recognition box data.
*Download models from GoogleDrive or BaiduNetdisk and copy to ComfyUI/models/yolo folder.
Node Options:
- image: The image to segment.
- yolo_model: Choose the yolo model.
- sort_method: The selection box sorting method has 4 options: "left_to_right", "top_to_bottom", "big_to_small" and "confidence".
- bbox_select: Select the input box data. There are three options: "all" to select all, "first" to select the box with the highest confidence, and "by_index" to specify the index of the box.
- select_index: This option is valid when bbox_delect is 'by_index'. 0 is the first one. Multiple values can be entered, separated by any non numeric character, including but not limited to commas, periods, semicolons, spaces or letters, and even Chinese.
<a id="table1">ObjectDetectorMask</a>
Use mask as recognition box data. All areas surrounded by white areas on the mask will be recognized as an object. Multiple enclosed areas will be identified separately.
Node Options:
- object_mask: The mask input.
- sort_method: The selection box sorting method has 4 options: "left_to_right", "top_to_bottom", "big_to_small" and "confidence".
- bbox_select: Select the input box data. There are three options: "all" to select all, "first" to select the box with the highest confidence, and "by_index" to specify the index of the box.
- select_index: This option is valid when bbox_delect is 'by_index'. 0 is the first one. Multiple values can be entered, separated by any non numeric character, including but not limited to commas, periods, semicolons, spaces or letters, and even Chinese.
<a id="table1">BBoxJoin</a>
Merge recognition box data.
Node Options:
- bboxes_1: Required input. The first set of identification boxes.
- bboxes_2: Optional input. The second set of identification boxes.
- bboxes_3: Optional input. The third set of identification boxes.
- bboxes_4: Optional input. The fourth set of identification boxes.
<a id="table1">DrawBBoxMask</a>
Draw the recognition BBoxes data output by the Object Detector node as a mask.
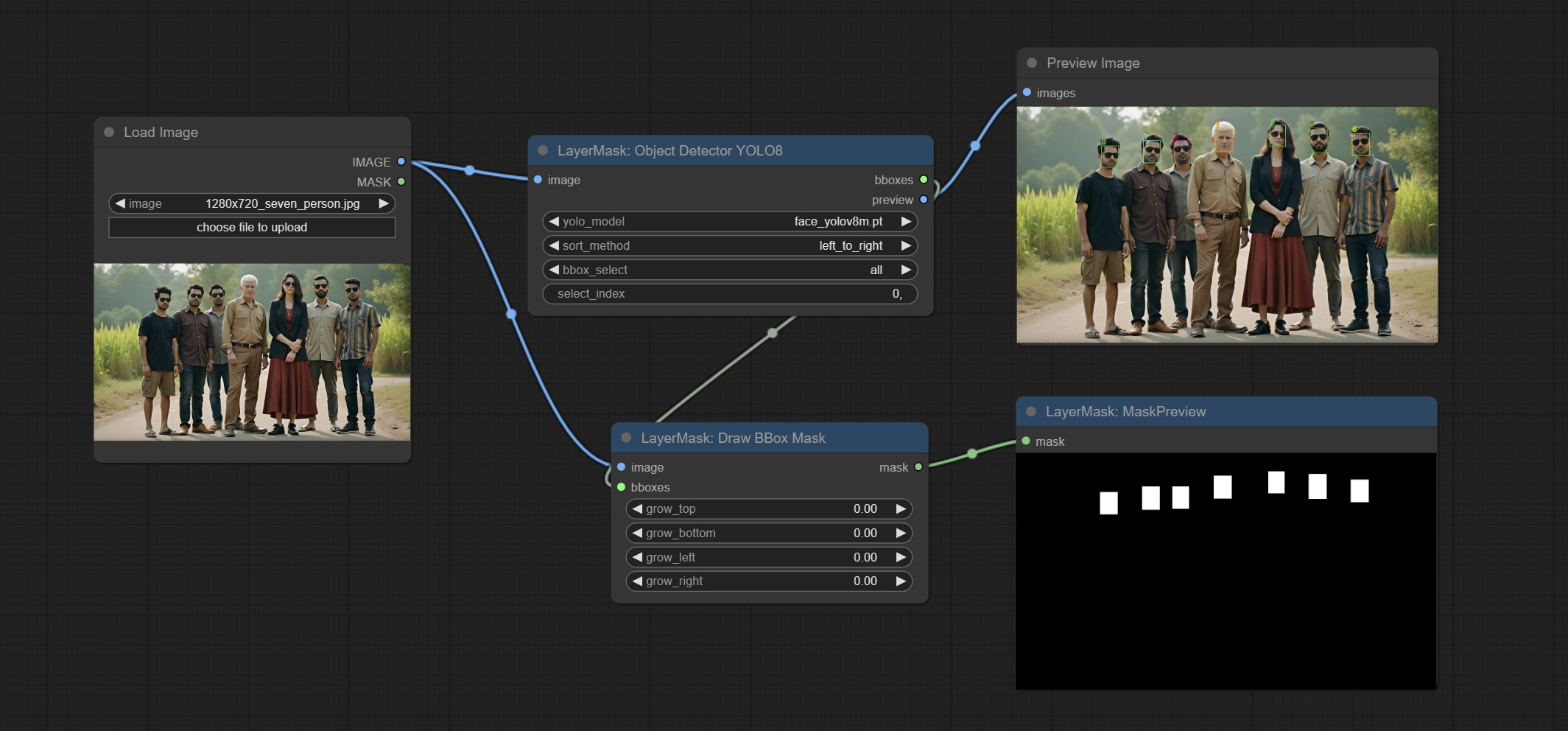
Node Options:
- image: Image input. It must be consistent with the image recognized by the Object Detector node.
- bboxes: Input recognition BBoxes data.
- grow_top: Each BBox expands upwards as a percentage of its height, positive values indicate upward expansion and negative values indicate downward expansion.
- grow_bottom: Each BBox expands downwards as a percentage of its height, positive values indicating downward expansion and negative values indicating upward expansion.
- grow_left: Each BBox expands to the left as a percentage of its width, positive values expand to the left and negative values expand to the right.
- grow_right: Each BBox expands to the right as a percentage of its width, positive values indicate expansion to the right and negative values indicate expansion to the left.
<a id="table1">DrawBBoxMaskV2</a>
Add rounded rectangle drawing to the DrawBBoxMask node.
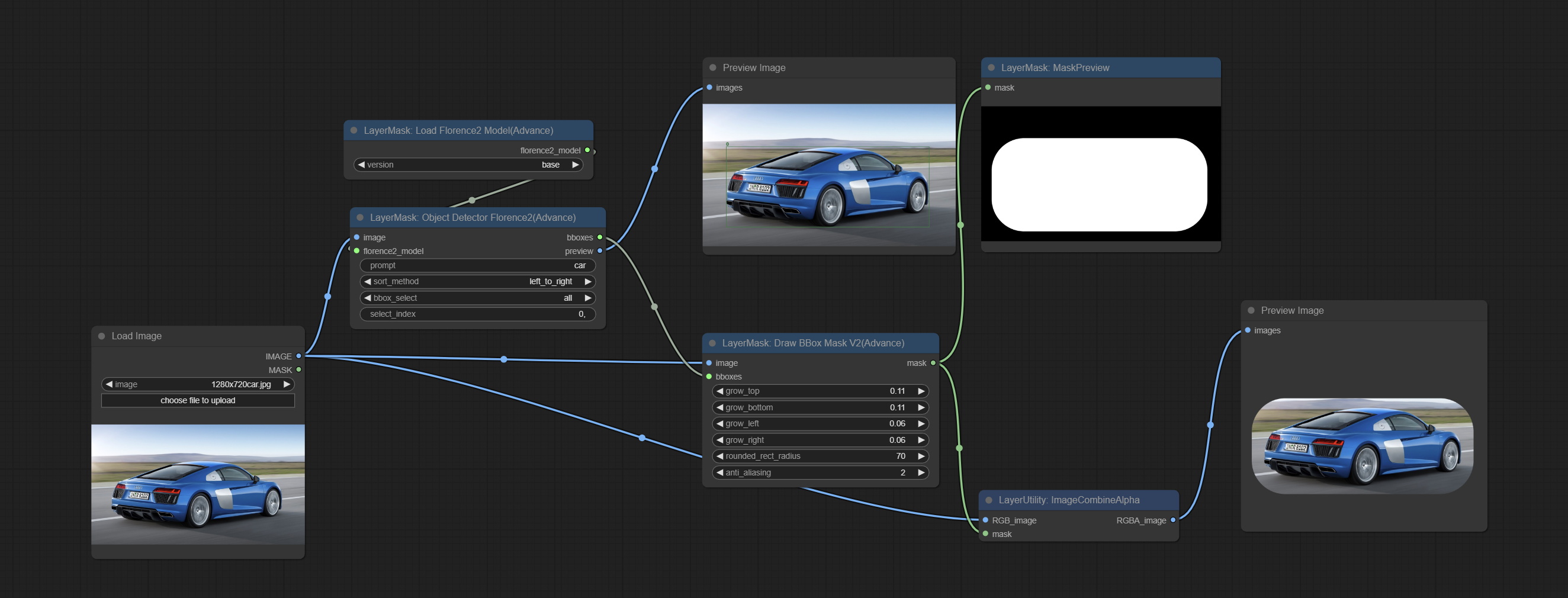
Add Options:
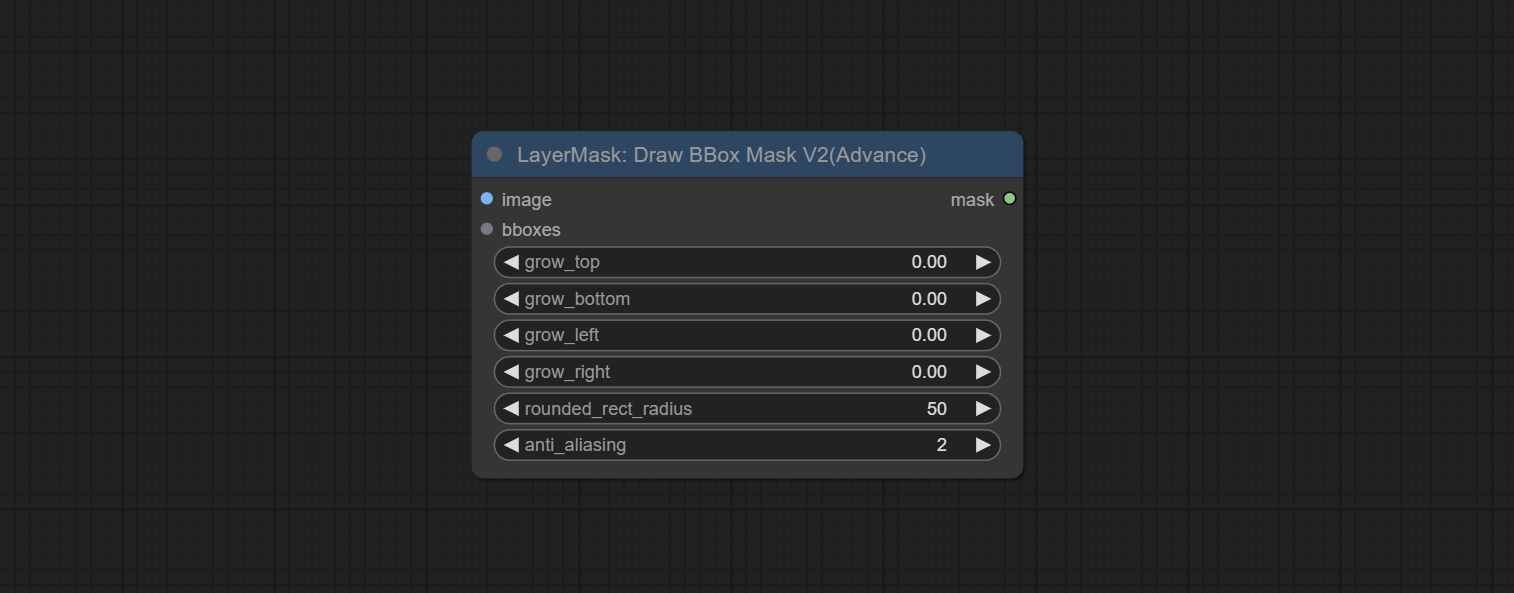
- rounded_rect_radius: Rounded rectangle radius. The range is 0-100, and the larger the value, the more pronounced the rounded corners.
- anti_aliasing: Anti aliasing, ranging from 0-16, with larger values indicating less pronounced aliasing. Excessive values will significantly reduce the processing speed of nodes.
<a id="table1">EVF-SAMUltra</a>
This node is implementation of EVF-SAM in ComfyUI.
*Please download model files from BaiduNetdisk or huggingface/EVF-SAM2, huggingface/EVF-SAM to ComfyUI/models/EVF-SAM folder(save the models in their respective subdirectories).
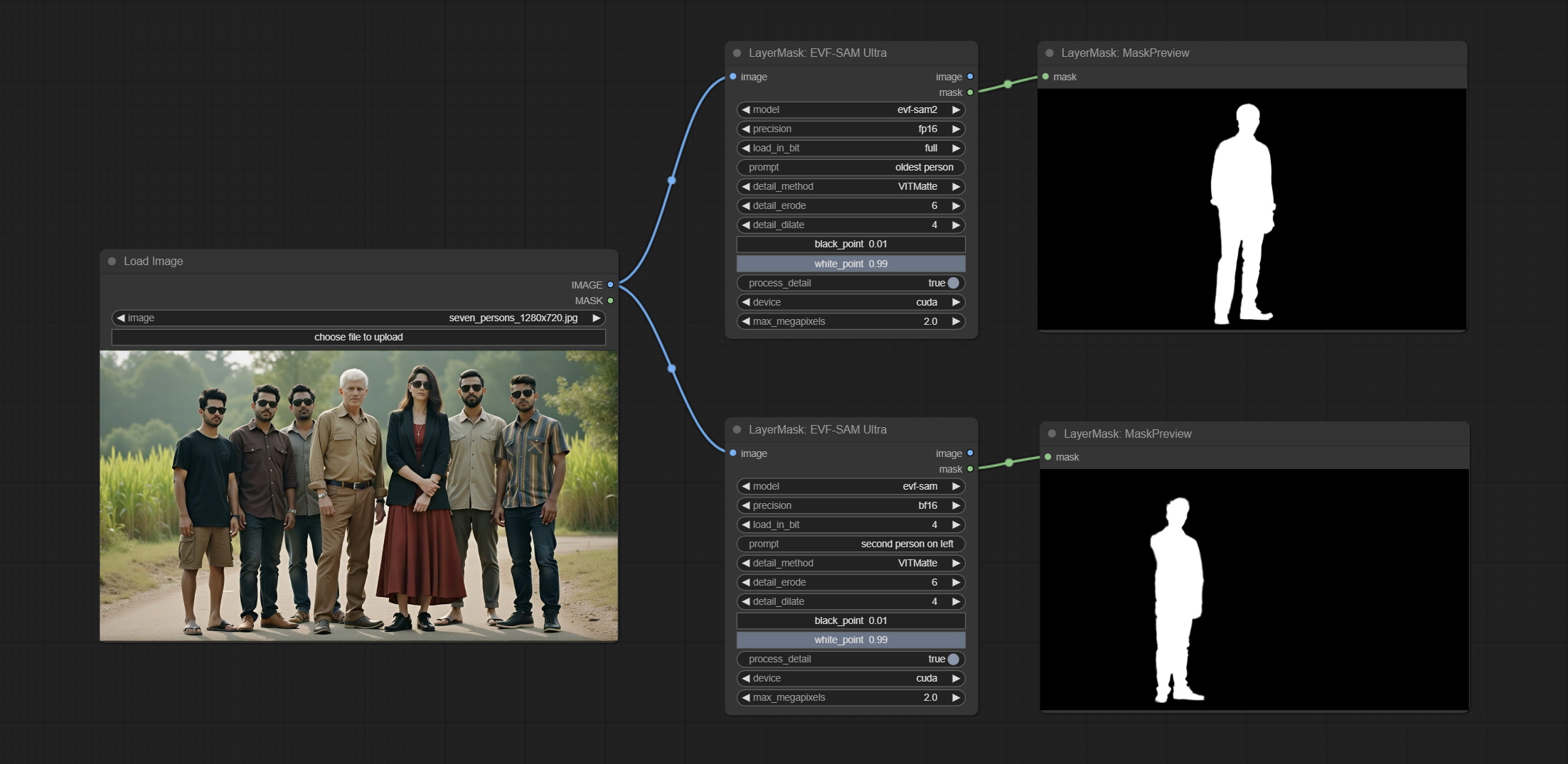
Node Options:
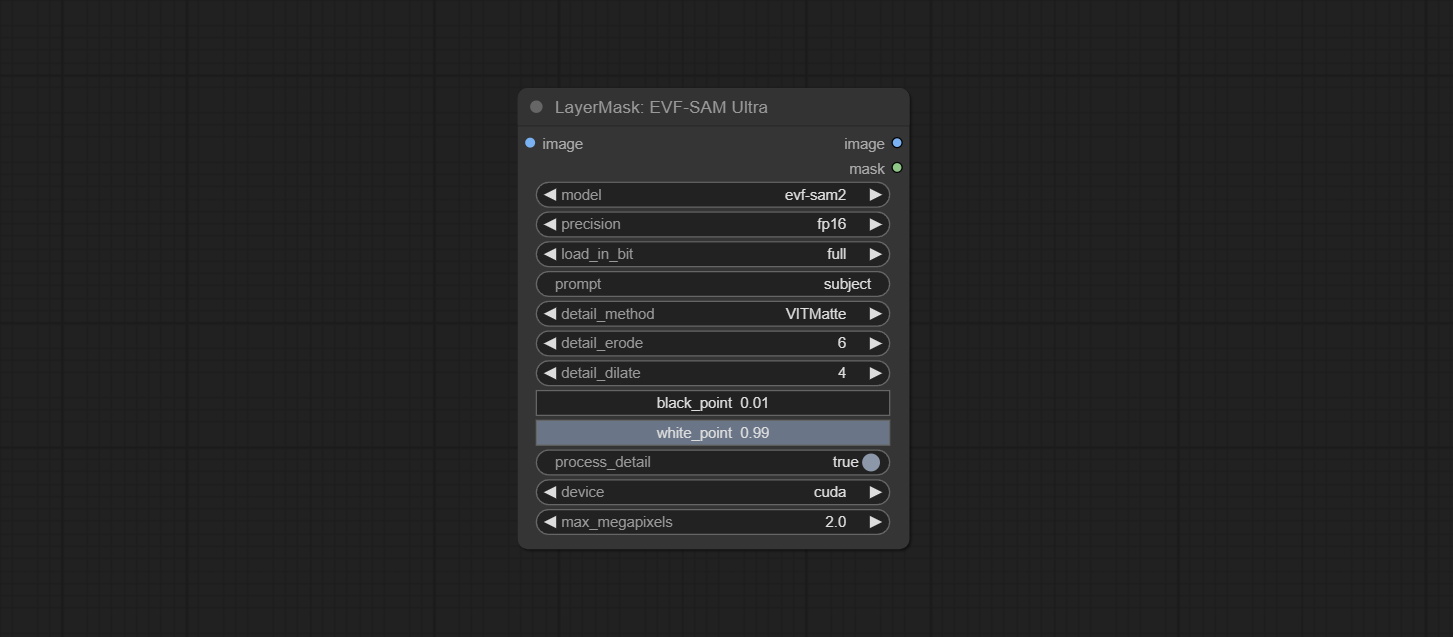
- image: The input image.
- model: Select the model. Currently, there are options for evf-sam2 and evf sam.
- presicion: Model accuracy can be selected from fp16, bf16, and fp32.
- load_in_bit: Load the model with positional accuracy. You can choose from full, 8, and 4.
- pormpt: Prompt words used for segmentation.
- detail_method: Edge processing methods. provides VITMatte, VITMatte(local), PyMatting, GuidedFilter. If the model has been downloaded after the first use of VITMatte, you can use VITMatte (local) afterwards.
- detail_erode: Mask the erosion range inward from the edge. the larger the value, the larger the range of inward repair.
- detail_dilate: The edge of the mask expands outward. the larger the value, the wider the range of outward repair.
- black_point: Edge black sampling threshold.
- white_point: Edge white sampling threshold.
- process_detail: Set to false here will skip edge processing to save runtime.
- device: Set whether the VitMatte to use cuda.
- max_megapixels: Set the maximum size for VitMate operations.
<a id="table1">Florence2Ultra</a>
Using the segmentation function of the Florence2 model, while also having ultra-high edge details.
The code for this node section is from spacepxl/ComfyUI-Florence-2, thanks to the original author.
*Download the model files from BaiduNetdisk to ComfyUI/models/florence2 folder.
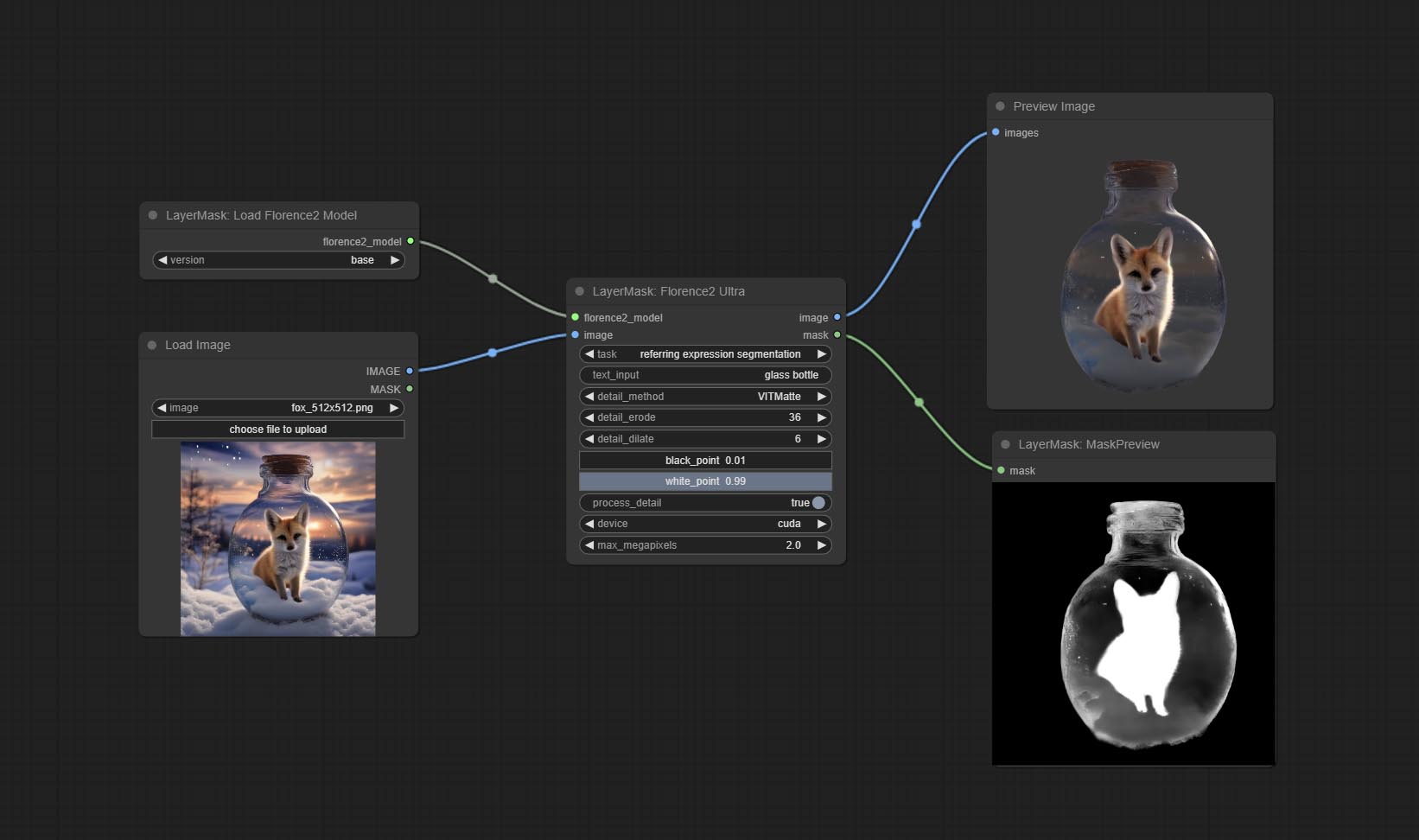
Node Options:
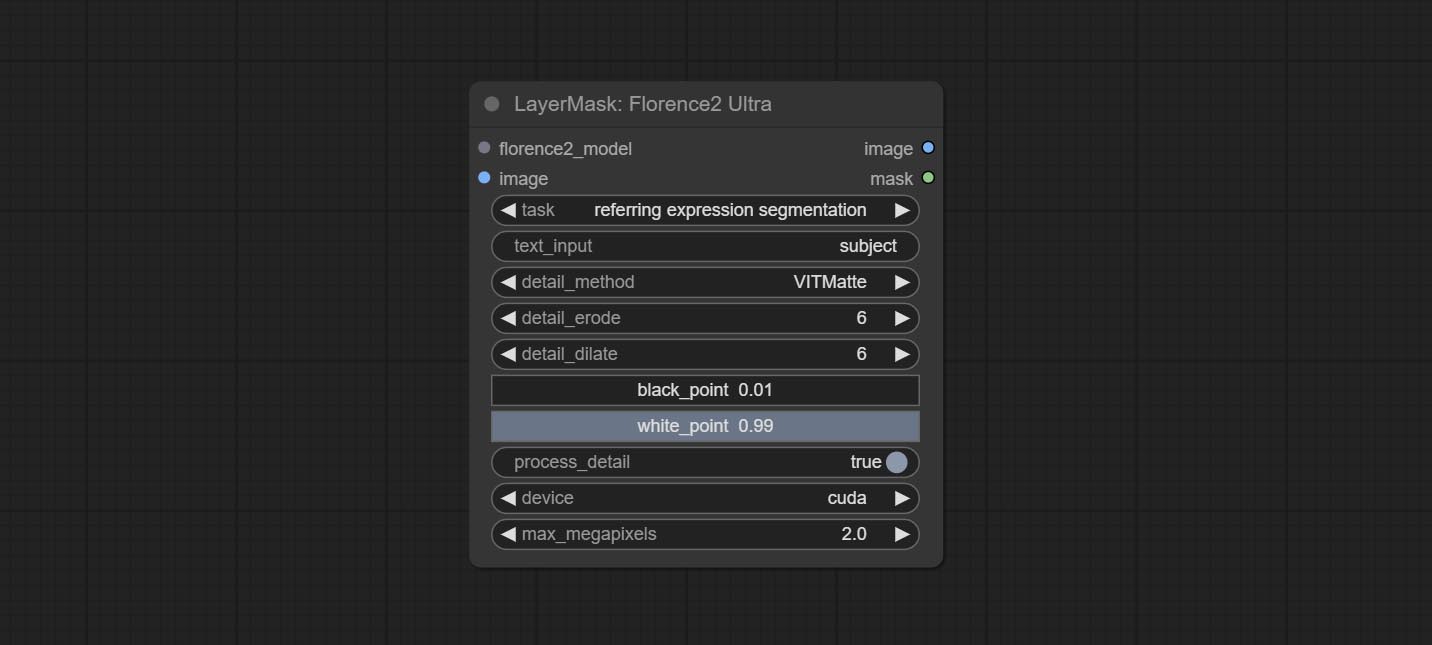
- florence2_model: Florence2 model input.
- image: Image input.
- task: Select the task for florence2.
- text_input: Text input for florence2.
- detail_method: Edge processing methods. provides VITMatte, VITMatte(local), PyMatting, GuidedFilter. If the model has been downloaded after the first use of VITMatte, you can use VITMatte (local) afterwards.
- detail_erode: Mask the erosion range inward from the edge. the larger the value, the larger the range of inward repair.
- detail_dilate: The edge of the mask expands outward. the larger the value, the wider the range of outward repair.
- black_point: Edge black sampling threshold.
- white_point: Edge white sampling threshold.
- process_detail: Set to false here will skip edge processing to save runtime.
- device: Set whether the VitMatte to use cuda.
- max_megapixels: Set the maximum size for VitMate operations.
<a id="table1">LoadFlorence2Model</a>
Florence2 model loader. *When using it for the first time, the model will be automatically downloaded.
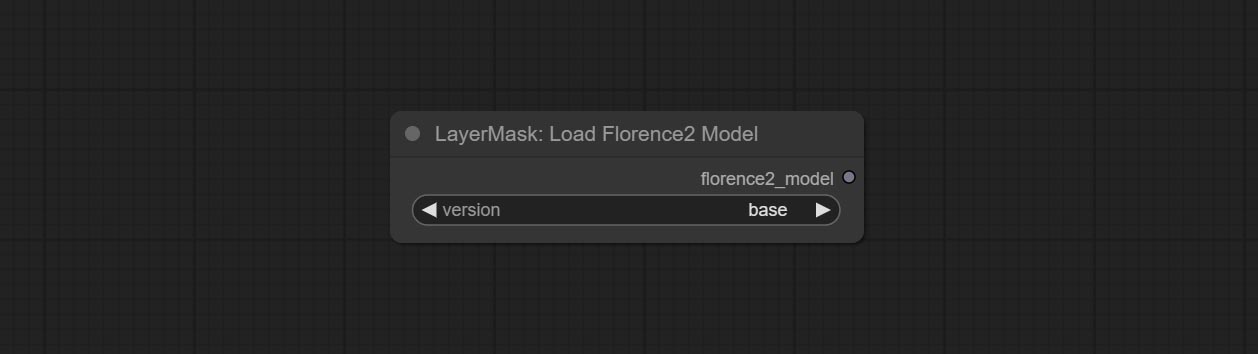
At present, there are base, base-ft, large, large-ft, DocVQA, SD3-Captioner and base-PromptGen models to choose from.
<a id="table1">BiRefNetUltra</a>
Using the BiRefNet model to remove background has better recognition ability and ultra-high edge details. The code for the model part of this node comes from Viper's ComfyUI-BiRefNet,thanks to the original author.
*From https://huggingface.co/ViperYX/BiRefNet or BaiduNetdisk download the BiRefNet-ep480.pth,pvt_v2_b2.pth,pvt_v2_b5.pth,swin_base_patch4_window12_384_22kto1k.pth, swin_large_patch4_window12_384_22kto1k.pth 5 files to ComfyUI/models/BiRefNet folder.
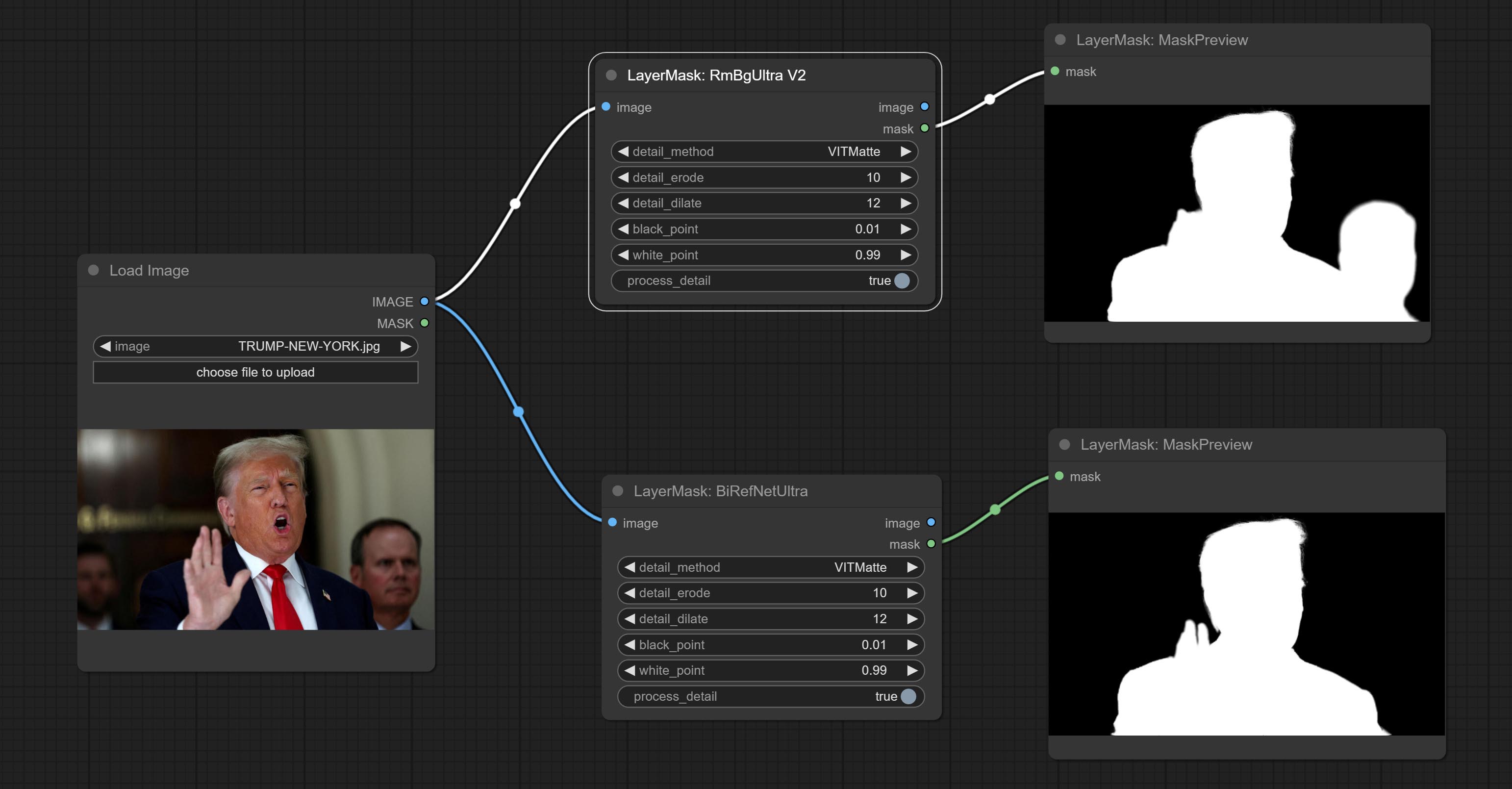
Node options:
- detail_method: Edge processing methods. provides VITMatte, VITMatte(local), PyMatting, GuidedFilter. If the model has been downloaded after the first use of VITMatte, you can use VITMatte (local) afterwards.
- detail_erode: Mask the erosion range inward from the edge. the larger the value, the larger the range of inward repair.
- detail_dilate: The edge of the mask expands outward. the larger the value, the wider the range of outward repair.
- black_point: Edge black sampling threshold.
- white_point: Edge white sampling threshold.
- process_detail: Set to false here will skip edge processing to save runtime.
- device: Set whether the VitMatte to use cuda.
- max_megapixels: Set the maximum size for VitMate operations.
<a id="table1">BiRefNetUltraV2</a>
This node supports the use of the latest BiRefNet model.
*Download model file from BaiduNetdisk or GoogleDrive named BiRefNet-general-epoch_244.pth to ComfyUI/Models/BiRefNet/pth folder. You can also download more BiRefNet models and put them here.
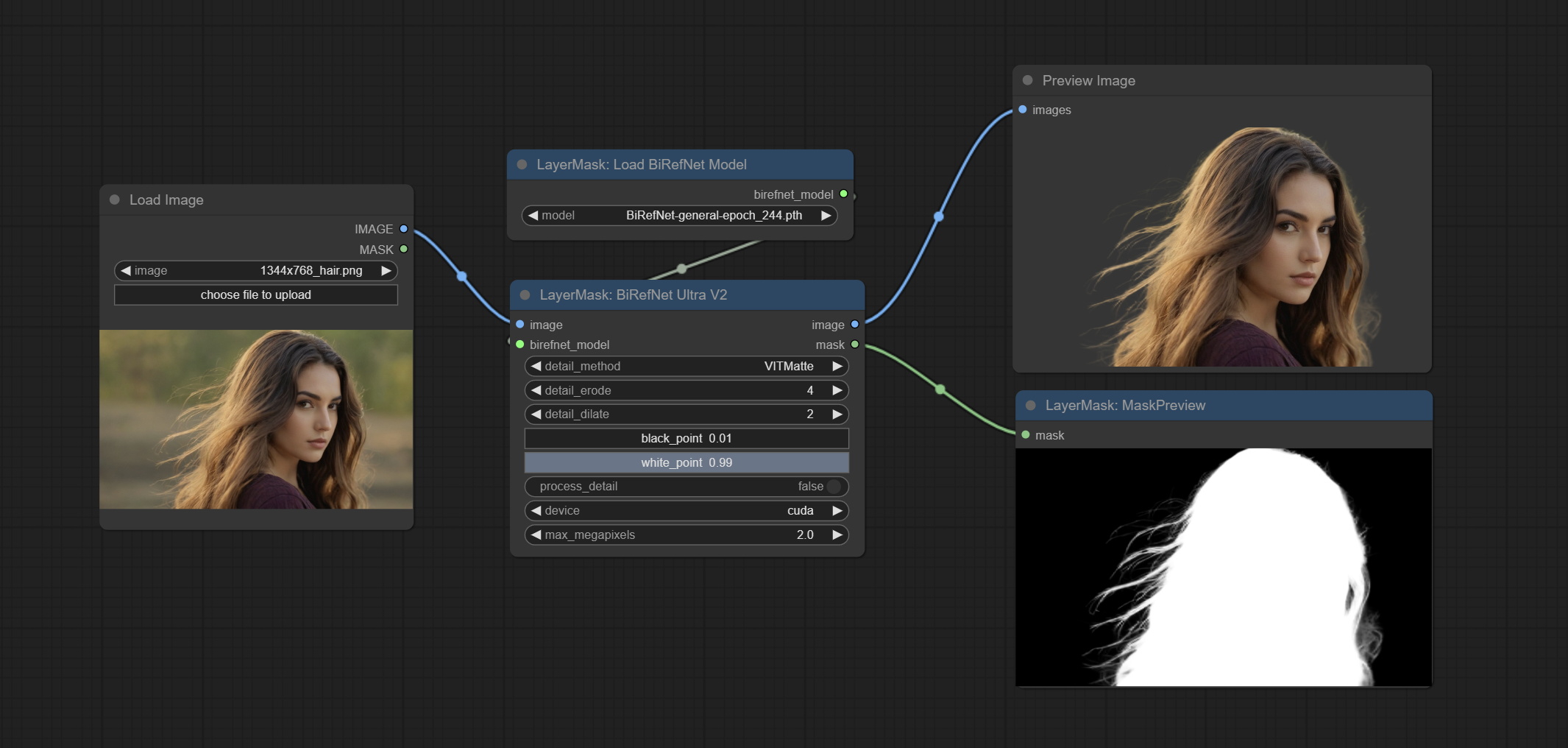
Node Options:
- image: The input image.
- birefnet_model: The BiRefNet model is input and it is output from the LoadBiRefNetModel node.
- detail_method: Edge processing methods. provides VITMatte, VITMatte(local), PyMatting, GuidedFilter. If the model has been downloaded after the first use of VITMatte, you can use VITMatte (local) afterwards.
- detail_erode: Mask the erosion range inward from the edge. the larger the value, the larger the range of inward repair.
- detail_dilate: The edge of the mask expands outward. the larger the value, the wider the range of outward repair.
- black_point: Edge black sampling threshold.
- white_point: Edge white sampling threshold.
- process_detail: Due to the excellent edge processing of BiRefNet, it is set to False by default here.
- device: Set whether the VitMatte to use cuda.
- max_megapixels: Set the maximum size for VitMate operations.
<a id="table1">LoadBiRefNetModel</a>
Load the BiRefNet model.
Node Options:
- model: Select the model. List the files in the
CoomfyUI/models/BiRefNet/pthfolder for selection.
<a id="table1">LoadBiRefNetModelV2</a>
This node is a PR submitted by jimlee2048 and supports loading RMBG-2.0 models.
Download model files from huggingface or 百度网盘 and copy to ComfyUI/models/BiRefNet/RMBG-2.0 folder.
Node Options:
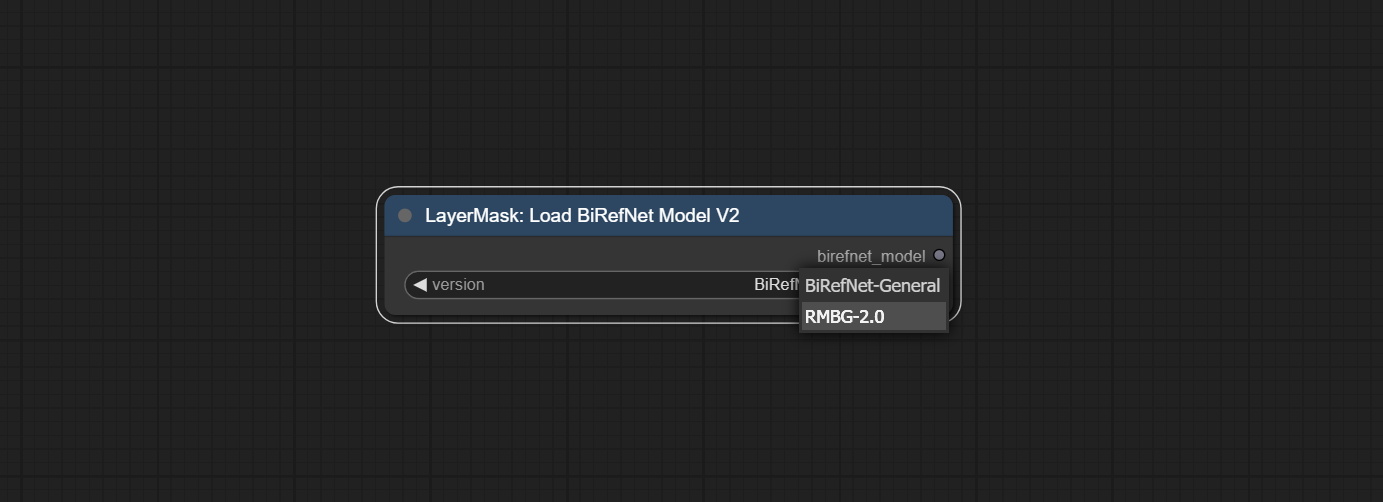
- model: Select the model. There are two options,
BiRefNet-GeneralandRMBG-2.0.
<a id="table1">TransparentBackgroundUltra</a>
Using the transparent-background model to remove background has better recognition ability and speed, while also having ultra-high edge details.
*From googledrive or BaiduNetdisk download all files to ComfyUI/models/transparent-background folder.
Node Options:
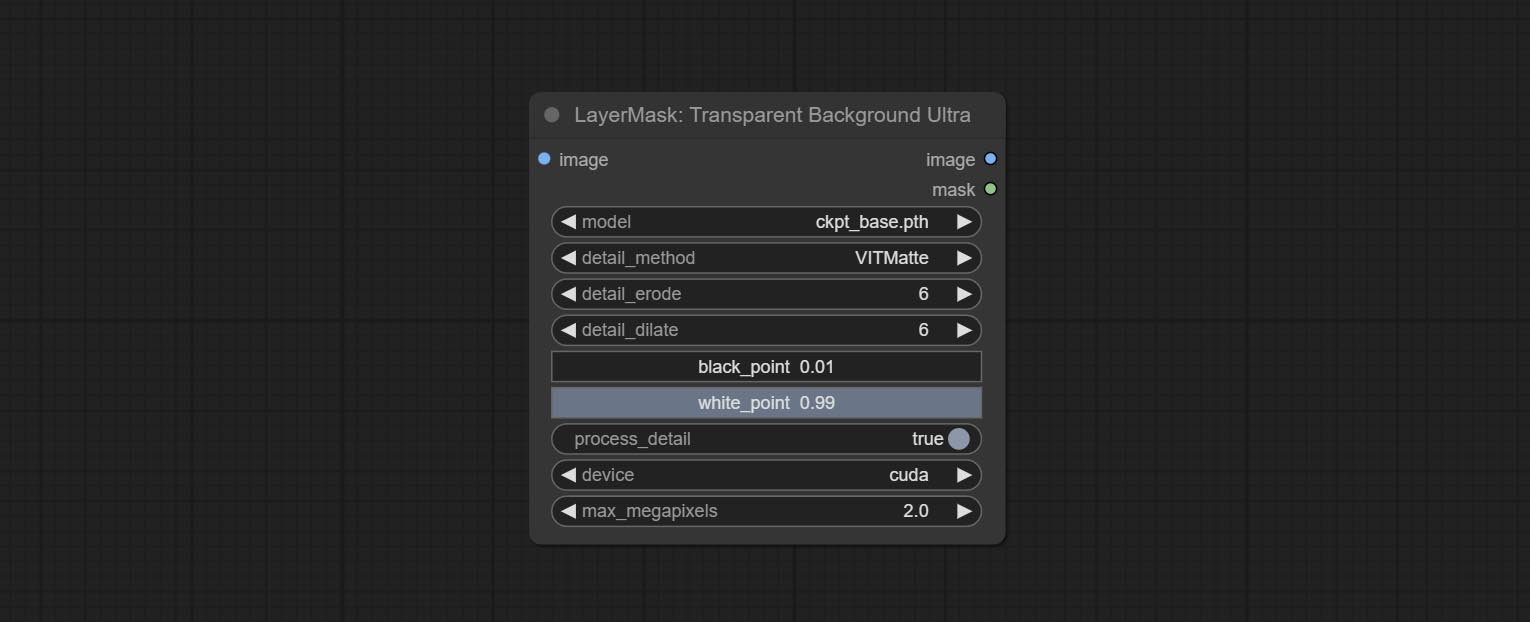
- model: Select the model.
- detail_method: Edge processing methods. provides VITMatte, VITMatte(local), PyMatting, GuidedFilter. If the model has been downloaded after the first use of VITMatte, you can use VITMatte (local) afterwards.
- detail_erode: Mask the erosion range inward from the edge. the larger the value, the larger the range of inward repair.
- detail_dilate: The edge of the mask expands outward. the larger the value, the wider the range of outward repair.
- black_point: Edge black sampling threshold.
- white_point: Edge white sampling threshold.
- process_detail: Set to false here will skip edge processing to save runtime.
- device: Set whether the VitMatte to use cuda.
- max_megapixels: Set the maximum size for VitMate operations.
<a id="table1">PersonMaskUltra</a>
Generate masks for portrait's face, hair, body skin, clothing, or accessories. Compared to the previous A Person Mask Generator node, this node has ultra-high edge details.
The model code for this node comes from a-person-mask-generator, edge processing code from ComfyUI-Image-Filters,thanks to the original author.
*Download model files from BaiduNetdisk to ComfyUI/models/mediapipe folder.
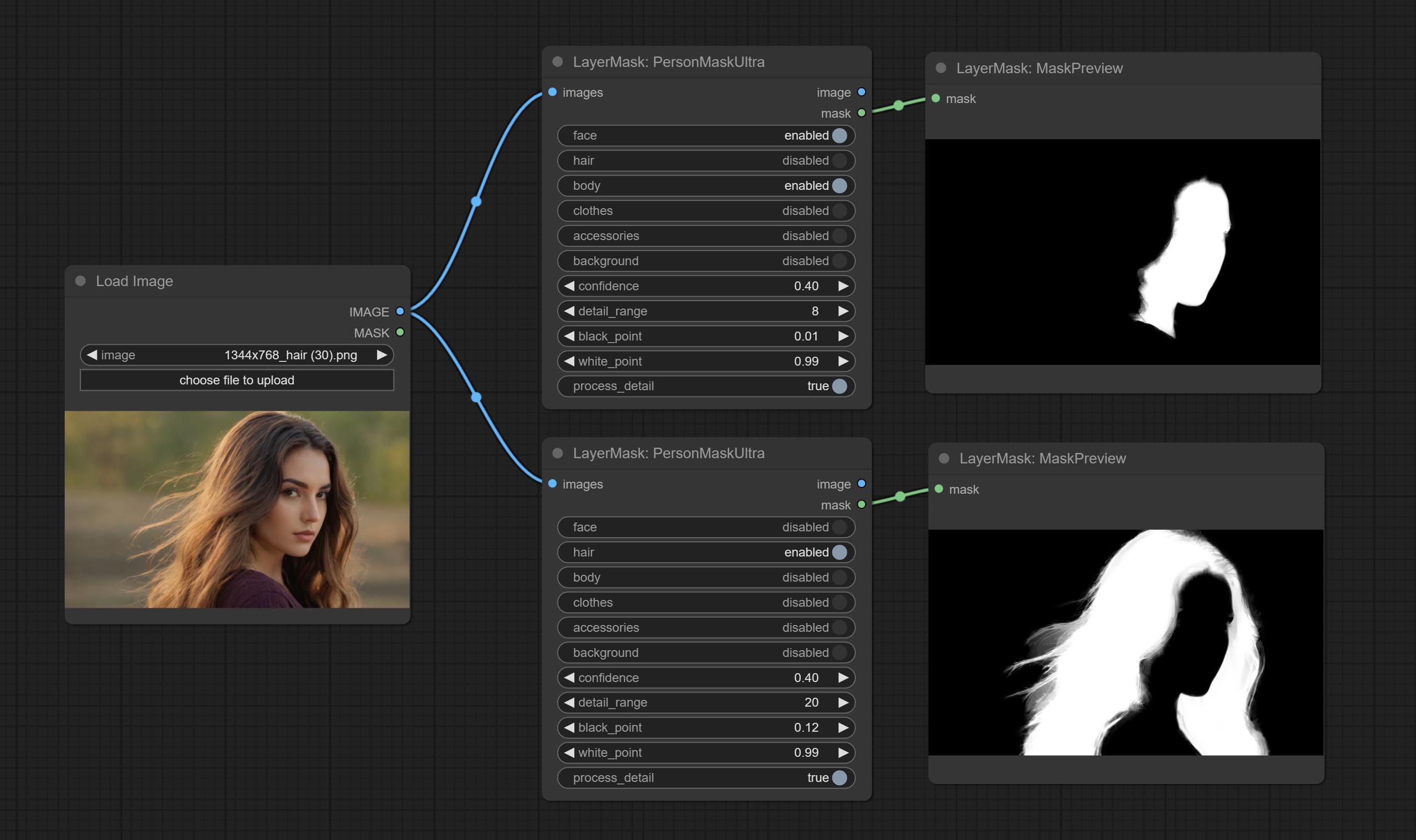
Node options:
- face: Face recognition.
- hair: Hair recognition.
- body: Body skin recognition.
- clothes: Clothing recognition.
- accessories: Identification of accessories (such as backpacks).
- background: Background recognition.
- confidence: Recognition threshold, lower values will output more mask ranges.
- detail_range: Edge detail range.
- black_point: Edge black sampling threshold.
- white_point: Edge white sampling threshold.
- process_detail: Set to false here will skip edge processing to save runtime.
<a id="table1">PersonMaskUltraV2</a>
The V2 upgraded version of PersonMaskUltra has added the VITMatte edge processing method.(Note: Images larger than 2K in size using this method will consume huge memory)
On the basis of PersonMaskUltra, the following changes have been made:
- detail_method: Edge processing methods. provides VITMatte, VITMatte(local), PyMatting, GuidedFilter. If the model has been downloaded after the first use of VITMatte, you can use VITMatte (local) afterwards.
- detail_erode: Mask the erosion range inward from the edge. the larger the value, the larger the range of inward repair.
- detail_dilate: The edge of the mask expands outward. the larger the value, the wider the range of outward repair.
- device: Set whether the VitMatte to use cuda.
- max_megapixels: Set the maximum size for VitMate operations.
<a id="table1">HumanPartsUltra</a>
Used for generate human body parts masks, it is based on the warrper of metal3d/ComfyUI_Human_Parts, thank the original author.
This node has added ultra-fine edge processing based on the original work. Download model file from BaiduNetdisk or huggingface and copy to ComfyUI\models\onnx\human-parts folder.
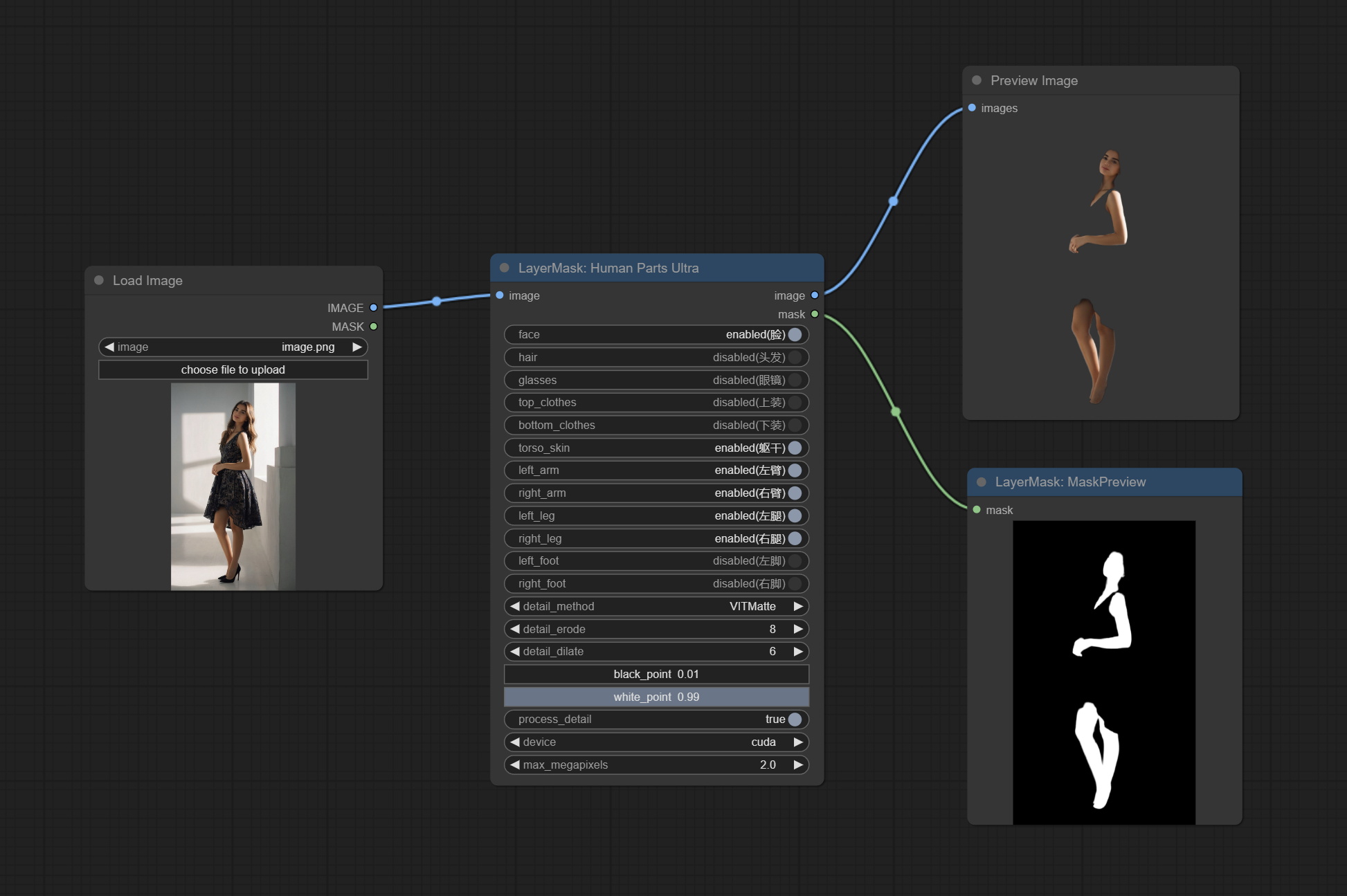
Node Options:
- image: The input image.
- face: Recognize face switch.
- hair: Recognize hair switch.
- galsses: Recognize glasses switch.
- top_clothes: Recognize top clothes switch.
- bottom_clothes: Recognize bottom clothes switch.
- torso_skin: Recognize torso skin switch.
- left_arm: Recognize left arm switch.
- right_arm: Recognize right arm switch.
- left_leg: Recognize left leg switch.
- right_leg: Recognize right leg switch.
- left_foot: Recognize left foot switch.
- right_foot: Recognize right foot switch.
- detail_method: Edge processing methods. provides VITMatte, VITMatte(local), PyMatting, GuidedFilter. If the model has been downloaded after the first use of VITMatte, you can use VITMatte (local) afterwards.
- detail_erode: Mask the erosion range inward from the edge. the larger the value, the larger the range of inward repair.
- detail_dilate: The edge of the mask expands outward. the larger the value, the wider the range of outward repair.
- black_point: Edge black sampling threshold.
- white_point: Edge white sampling threshold.
- process_detail: Set to false here will skip edge processing to save runtime.
- device: Set whether the VitMatte to use cuda.
- max_megapixels: Set the maximum size for VitMate operations.
<a id="table1">YoloV8Detect</a>
Use the YoloV8 model to detect faces, hand box areas, or character segmentation. Supports the output of the selected number of channels.
Download the model files from GoogleDrive or BaiduNetdisk to ComfyUI/models/yolo folder.
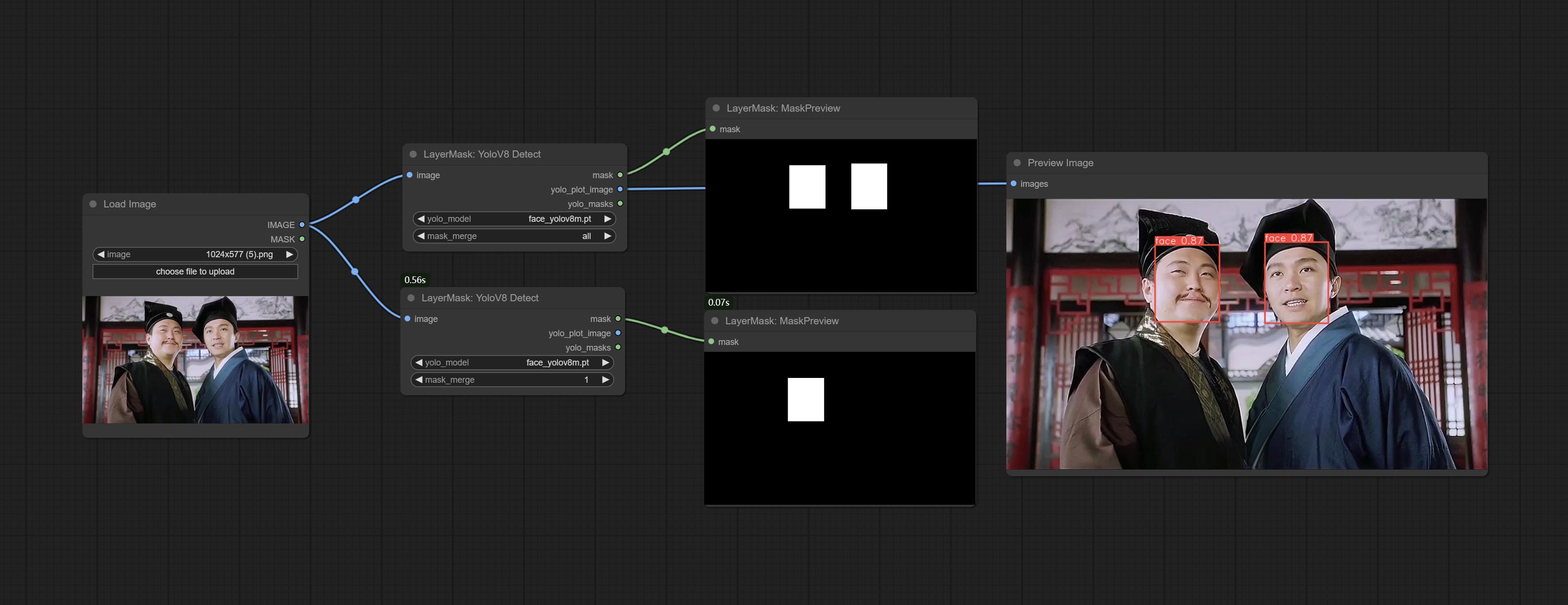
Node Options:
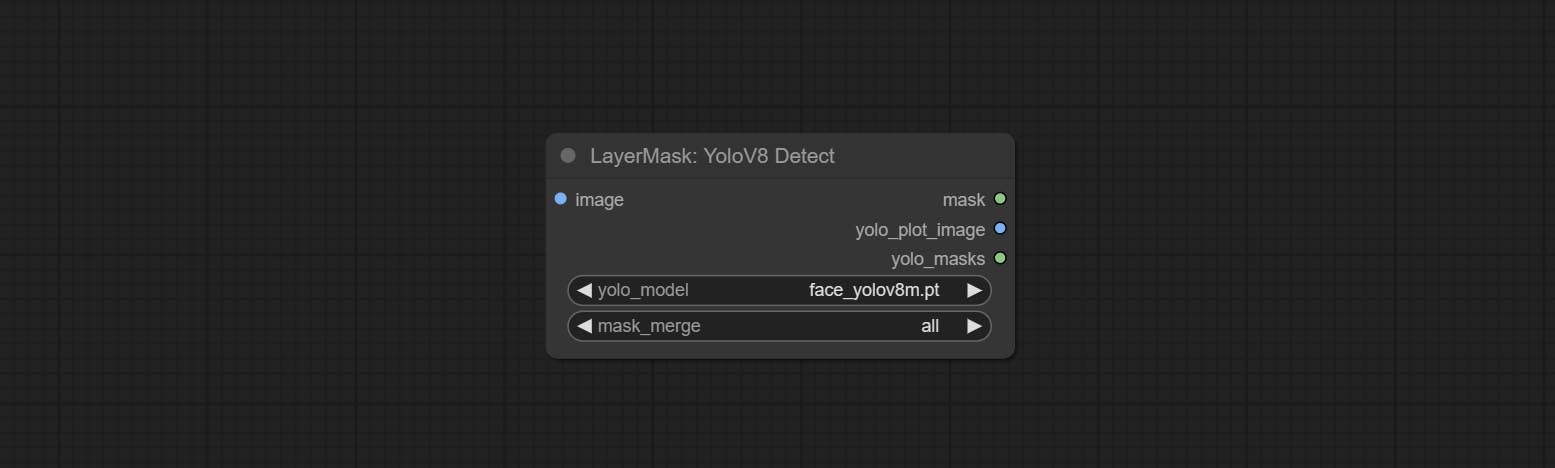
- yolo_model: Yolo model selection. the model with
segname can output segmented masks, otherwise they can only output box masks. - mask_merge: Select the merged mask.
allis to merge all mask outputs. The selected number is how many masks to output, sorted by recognition confidence to merge the output.
Outputs:
- mask: The output mask.
- yolo_plot_image: Preview of yolo recognition results.
- yolo_masks: For all masks identified by yolo, each individual mask is output as a mask.
<a id="table1">MediapipeFacialSegment</a>
Use the Mediapipe model to detect facial features, segment left and right eyebrows, eyes, lips, and tooth.
*Download the model files from BaiduNetdisk to ComfyUI/models/mediapipe folder.
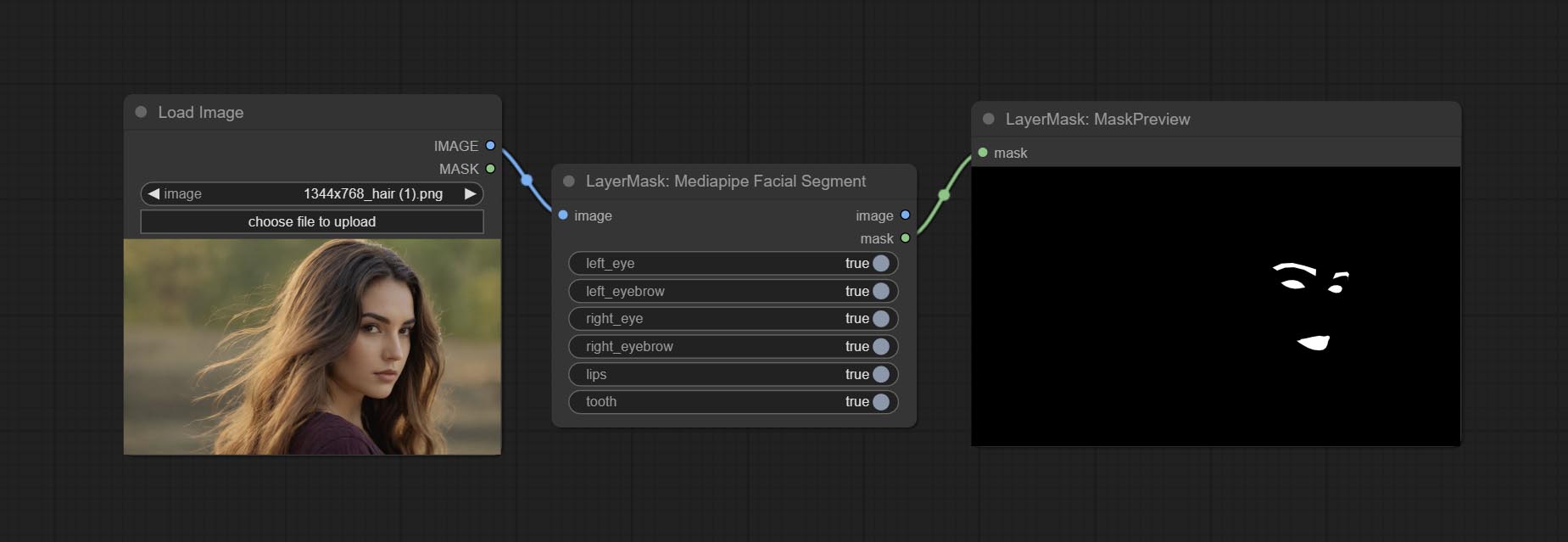
Node Options:
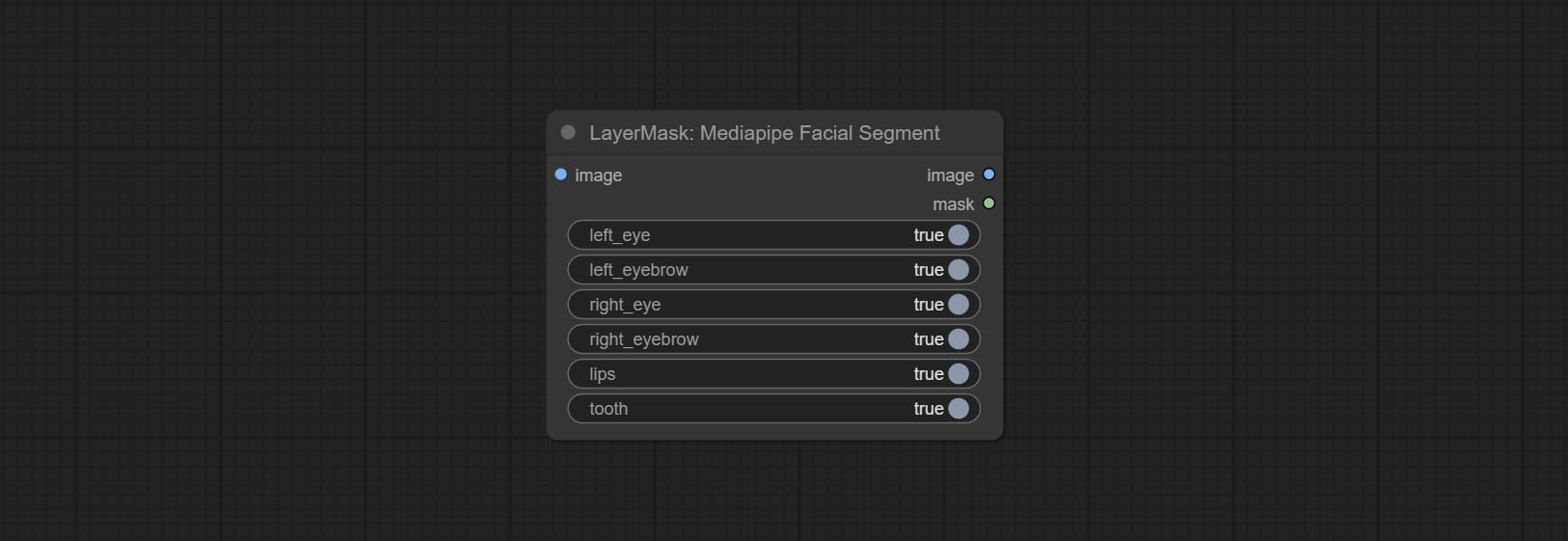
- left_eye: Recognition switch of left eye.
- left_eyebrow: Recognition switch of left eyebrow.
- right_eye: Recognition switch of right eye.
- right_eyebrow: Recognition switch of right eyebrow.
- lips: Recognition switch of lips.
- tooth: Recognition switch of tooth.
<a id="table1">MaskByDifferent</a>
Calculate the differences between two images and output them as mask.
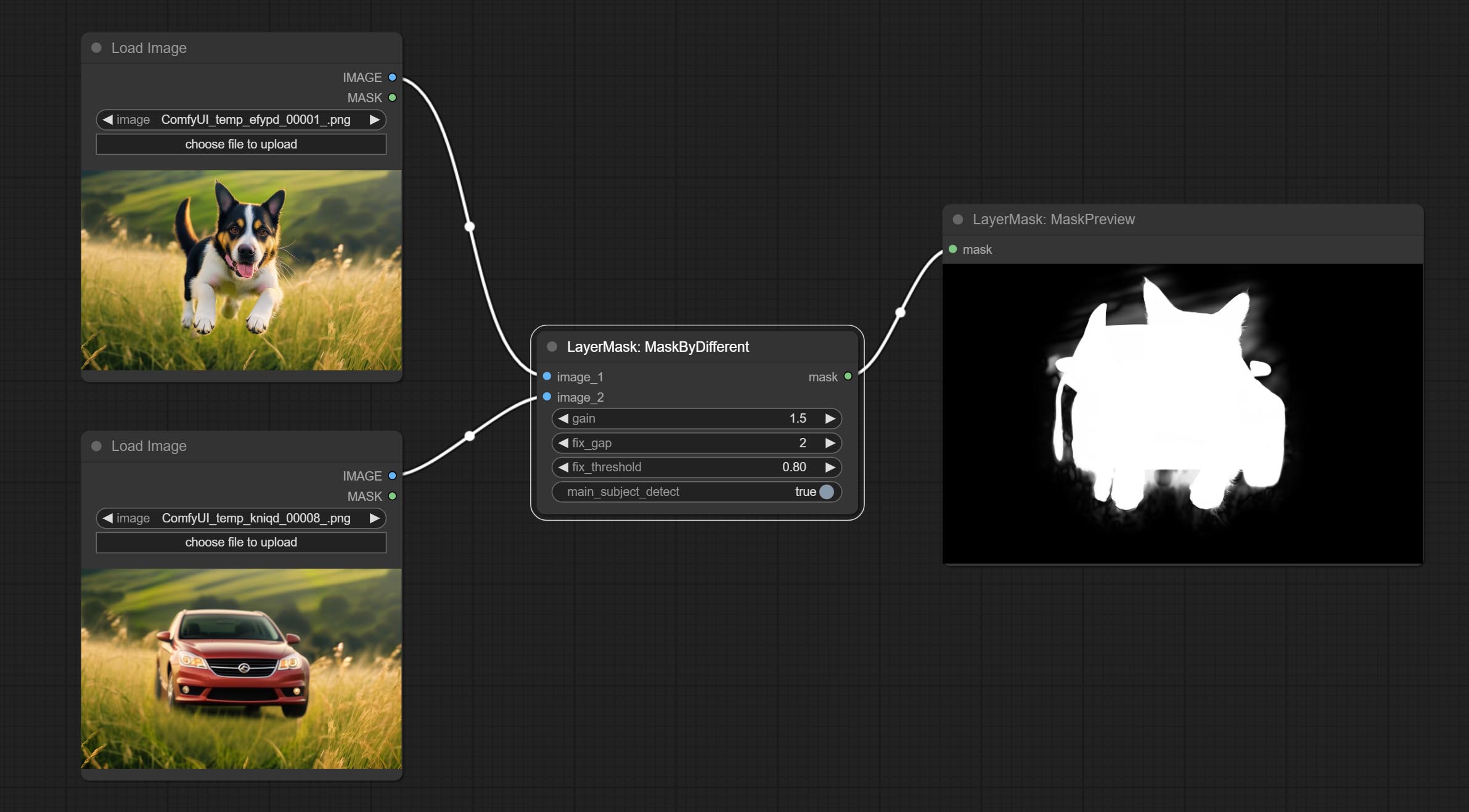
Node options:
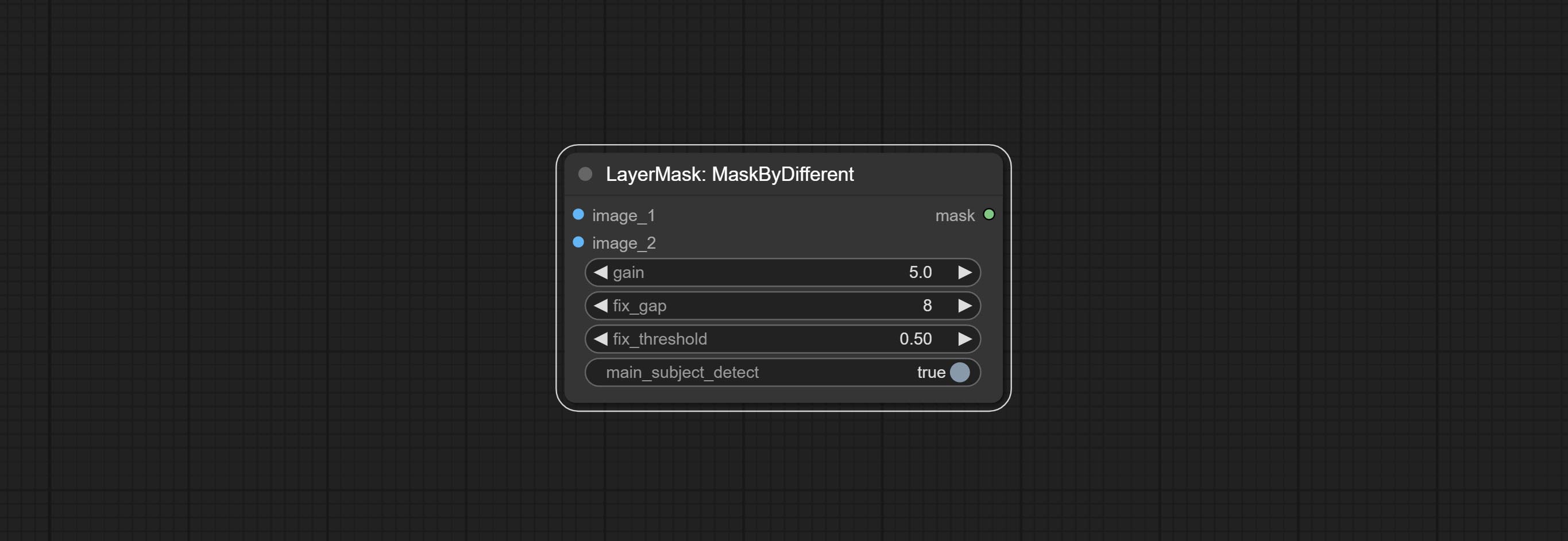
- gain: The gain of difference calculate. higher value will result in a more significant slight difference.
- fix_gap: Fix the internal gaps of the mask. higher value will repair larger gaps.
- fix_threshold: The threshold for fix_gap.
- main_subject_detect: Setting this to True will enable subject detection, ignoring differences outside of the subject.
Annotation for <a id="table1">notes</a>
<sup>1</sup> The layer_image, layer_mask and the background_image(if have input), These three items must be of the same size.
<sup>2</sup> The mask not a mandatory input item. the alpha channel of the image is used by default. If the image input does not include an alpha channel, the entire image's alpha channel will be automatically created. if have masks input simultaneously, the alpha channel will be overwrite by the mask.
<sup>3</sup> The <a id="table1">Blend</a> Mode include normal, multply, screen, add, subtract, difference, darker, color_burn, color_dodge, linear_burn, linear_dodge, overlay, soft_light, hard_light, vivid_light, pin_light, linear_light, and hard_mix. all of 19 blend modes in total.
<font size="1">*Preview of the blend mode </font><br />
<sup>3</sup> The <a id="table1">BlendModeV2</a> include normal, dissolve, darken, multiply, color burn, linear burn, darker color, lighten, screen, color dodge, linear dodge(add), lighter color, dodge, overlay, soft light, hard light, vivid light, linear light, pin light, hard mix, difference, exclusion, subtract, divide, hue, saturation, color, luminosity, grain extract, grain merge all of 30 blend modes in total.
Part of the code for BlendMode V2 is from Virtuoso Nodes for ComfyUI. Thanks to the original authors.

<font size="1">*Preview of the Blend Mode V2</font><br />
<sup>4</sup> The RGB color described by hexadecimal RGB format, like '#FA3D86'.
<sup>5</sup> The layer_image and layer_mask must be of the same size.
Stars
statement
LayerStyle Advance nodes follows the MIT license, Some of its functional code comes from other open-source projects. Thanks to the original author. If used for commercial purposes, please refer to the original project license to authorization agreement.
ComfyUI_LayerStyle_Advance is ready to run
It's one of 95 extensions already installed on ComfyICU — nothing to clone, nothing to reconcile. Bring a workflow and you're billed for GPU seconds, not idle time.