
ComfyUI Extension: comfyui_overly_complicated_sampling
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
Experimental and mathematically unsound (but fun!) sampling for ComfyUI. Feel free create a question in Discussions for usage help: OCS Q&A Discussion[w/Status: In flux, may be useful but likely to change/break workflows frequently. Mainly for advanced users.]
Looking for a different extension?
Custom Nodes (16)
- OCS ApplyFilterImage
- OCS ApplyFilterLatent
- OCS Group
- OCS ModelSetMaxSigma
- OCS MultiParam
- OCSNoise Conditioning
- OCSNoise ExpressionFilteredNoise
- OCSNoise ImmiscibleReference
- OCSNoise OverrideSamplerNoise
- OCSNoise PerlinAdvanced
- OCSNoise PerlinSimple
- OCSNoise to SONAR_CUSTOM_NOISE
- OCS Param
- OCS Sampler
- OCS SimpleRestartSchedule
- OCS Substeps
README
Overly Complicated Sampling
Experimental and mathematically unsound (but fun!) sampling for ComfyUI.
Status: In flux, may be useful but likely to change/break workflows frequently. Mainly for advanced users.
Feel free create a question in Discussions for usage help: OCS Q&A Discussion
Note for Flux users: Set cfg1_uncond_optimization: true in the model block for the main OCS Sampler as Flux does not use CFG. CFG++ and alt CFG++ features do not work with Flux.
Features
- Many different samplers.
- Allows scheduling samplers (i.e. run
eulerfor steps 1-4, then switch todpmpp_sde). - CFG++ support (for some samplers).
- Native support for Restart sigmas. (Restarts do not currently work with RF models like Flux.)
- Supports custom noise types.
- Immiscible noise for sampling and Restart. See https://arxiv.org/abs/2406.12303 (note that it was designed for training not inference).
- Allows splitting/combining steps in various ways for (potentially) more accurate sampling.
- Supports Diffrax, torchdiffeq, torchode and torchsde solver backends. (SDE mode not recommended currently.)
- Many tuneable parameters to play with.
- Supports ancestral sampling (in a janky way) for rectified flow models like Flux, works for most basic samplers: does not work for SDE samplers currently.
- Built in safe expression language that allows filtering and manipulating nearly all parameters during sampling.
Credits
I can move code around but sampling math and creating samplers generally beyond my ability. I didn't write any of the original samplers:
- Euler, Heun++2, DPMPP SDE, DPMPP 2S, gradient estimation, RES multistep, DPM++ 2m, 2m SDE and 3m SDE samplers based on ComfyUI's implementation.
- Reversible Heun, Reversible Heun 1s, RES, Trapezoidal, Bogacki, Reversible Bogacki, RK4, RKF45, dynamic RK(4), SENS and Euler Dancing samplers based on implementation from https://github.com/Clybius/ComfyUI-Extra-Samplers.
- TTM JVP sampler based on implementation written by Katherine Crowson (but yoinked from the Extra-Samplers repo mentioned above).
- Distance sampler based on implementation from https://github.com/Extraltodeus/DistanceSampler
- IPNDM, IPNDM_V and DEIS adapted from https://github.com/zju-pi/diff-sampler/blob/main/diff-solvers-main/solvers.py (I used the Comfy version as a reference).
- PingPong sampler idea from https://github.com/ace-step/ACE-Step/ (implementation also referenced from that source).
- Normal substep merge strategy based on implementation from https://github.com/Clybius/ComfyUI-Extra-Samplers
- Immiscible noise processing based on implementation from https://github.com/kohya-ss/sd-scripts/pull/1395 and https://github.com/yhli123/Immiscible-Diffusion - idea for sampling with it and implementation help from https://github.com/Clybius
- Precedence climbing (Pratt) expression parser based on implementation from https://github.com/andychu/pratt-parsing-demo
Please notify me if I somehow missed appropriately crediting any code used here, any such ommissions are unintentional.
This repo wouldn't be possible without building on the work of others. Thanks!
Usage
First, a note on the basic structure:
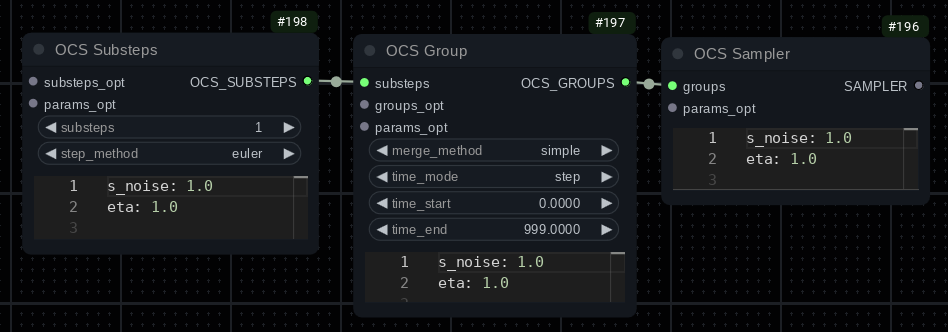
The sampler node connects to a group node. You can chain group nodes, however only one can match per step. Checking for a match starts at the group furthest from the sampler node. So if you have Group1 -> Group2 -> Group3 -> Sampler, the groups will be tried starting from Group1. Currently matching groups is only time based.
You will then connect a substeps node to the group. These can also be chained and like groups, execution starts with the node furthest from the group. I.E.: Substeps1 -> Substeps2 -> Substeps3 -> Group will start with Substeps1.
Most of these nodes have a text parameter input (YAML format - JSON is also valid YAML so you can use that instead if you prefer) and a parameter input. The parameter input can be used to specify stuff like custom noise types.
You may use filters and expressions in the text parameter input. See:
Integration
- ComfyUI-bleh - allows access to many more blend and scaling modes as well as some extra features.
- ComfyUI-sonar - allows access to many more noise types as well as the Power Filter feature.
- ComfyUi_NNLatentUpscale - allows access to the
t_scale_nnlatentupscalefunction in expressions.
If you're going to use OCS, I strongly recommend also installing ComfyUI-bleh and ComfyUI-sonar as they increase the functionality a lot.
Nodes
OCS Sampler
The main sampler node, with an output suitable for connecting to a SamplerCustom. This node has builtin support for Restart sampling, if you are
using Restart don't use the RestartSampler node.
You can connect a chain of OCS Group nodes to it and it will choose one per step (based on conditions like time).
Input Parameters
restart_custom_noise: Value type:SONAR_CUSTOM_NOISE. Allows specifying a custom noise type when used with Restart sampling.
Text Parameters
Shown in YAML with default values.
<details> <summary>★★ Expand ★★</summary># Noise scale. May not do anything currently.
s_noise: 1.0
# ETA (basically ancestralness). May not do anything currently.
eta: 1.0
# Reversible ETA (used for reversible samplers). May not do anything currently.
reta: 1.0
# Parameters related to restart sampling.
restart:
# When enabled, out of order sigmas will be detected as restart.
# You can disable this if you want to use OCS for something like unsampling.
enabled: true
# Scales the noise added by restart sampling.
s_noise: 1.0
# Immiscible block same as described below.
immiscible:
size: 0
# The noise block allows defining global noise sampling parameters.
noise:
# You can disable this to allow GPU noise generation.
cpu_noise: true
# ComfyUI has a bug where if you disable add_noise in the sampler, no seed gets set. If you
# are manually noising a sample and have add_noise turned off then you should enable this if
# you want reproducible generations.
set_seed: true
# Only has an effect when set_seed is enabled. Will advance the RNG this many times to
# avoid the common mistake of using the same noise for sampling as the initial noise.
seed_offset: 1
# Global scale scale for generated noise
scale: 1.0
# Whether the generated noise should be normalized before use. Generally a good idea to leave enabled.
normalize_noise: true
# Dimensions to normalize over (when normalization is enabled). Negative values mean starting
# from the end (i.e. -1 means the last dimension, -2 means the penultimate dimension).
# Latents generally have these dimensions: batch, channels, height, width
# The default of [-3, -2, -1] normalizes noise over the batch. You can try something like
# [-2, -1] to normalize over the batch and channels. See: https://pytorch.org/docs/stable/generated/torch.std.html
normalize_dims: [-3, -2, -1]
# When caching, the batch size for chunks of noise to generate in advance. Generating a batch of noise
# can be more efficient than generating on demand when using a high number of substeps (>10) per step.
batch_size: 1
# Whether to cache noise.
caching: true
# Interval (in full steps) to reset the cache. Brownian noise takes time into account so
# if using Brownian with caching enabled you will generally want to reset each step.
cache_reset_interval: 9999
# Immiscible noise processing, see: https://arxiv.org/abs/2406.12303
immiscible:
# Batch size, 0 disables.
size: 0
# Reference mode, values can be one of:
# x: Uses the current latent as a reference.
# noise: Uses the current noise as a reference (x - denoised)
# denoised: Uses the model image prediction as a reference (factors in positive and negative prompts).
# uncond: The model unconditional prediction (negative prompt)
# cond: The model conditional prediction (positive prompt)
# Advanced feature: Additionally you may enter a string of operations in the format:
# "x - denoised * 2 + cond" (just an example, not a recommended setting)
# Possible operations: + - / * min max add sub div mul
# Note: Each value and operation must be space delimited (i.e. "x-1" will not work).
# Also normal operator precedence does not apply here.
ref: default
# Batching mode, one of:
# batch: Matches vs batches. Immiscible mode is disabled if size < 2
# channel: Splits the batch into a list of channels and matches against those.
# row: Splits the batch into a list of rows and matches against those.
# column: Splits the batch into a list of columns and matches against those.
# Note: Requires reshaping both the noise and x, may be slow and consume
# a lot of VRAM.
batching: channel
# Scale for reference latent. Can be negative.
scale_ref: 1.0
# Allows normalizing the reference. If this is a list, you can specify the dimensions to
# normalize. See normalize_dims above and https://pytorch.org/docs/stable/generated/torch.std.html
normalize_ref: false
# The proportion of immiscible-ized noise.
# You get (immiscible_noise * strength) + ((1.0 - strength) * normal_noise) - LERP.
strength: 1.0
# See: https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.linear_sum_assignment.html#scipy.optimize.linear_sum_assignment
maximize: false
# Can be set to enable immiscible v2 mode. 0.0 is disabled, 0.1 is a reasonable value.
distance_scale: 0.0
# If null will use the same value as distance_scale.
distance_scale_ref: null
filter: null
model:
# When enabled, skips generating uncond when you have CFG set to 1. Disabled by
# default as stuff like CFG++ won't work without uncond. Useful to enable for
# models like Flux that don't actually use CFG.
cfg1_uncond_optimization: false
filter:
# Input to the model
input: null
# Result after CFG calculation
denoised: null
# Result after CFG calculation for JVP
jdenoised: null
# Cond - positive prompt
cond: null
# Uncond - negative prompt
uncond: null
Any parameters you don't specify will use the defaults. For example if your text parameter block is:
noise:
cpu_noise: false
Then the rest of the parameters will use the defaults shown above.
OCS Group
Defines a group of substeps.
Merging
When running multiple substeps per step, the results will combined based on the merge strategy. Possible strategies (in order of least weird to most weird):
simple: Doesn't merge anything: only runs a single substep per step.divide: Creates a linear schedule between the current sigma and the next and runs the substeps in sequence. The model is called at least once per substep.supreme_avg: The model is called at least once per step (and possibly additional times for higher order samplers). Each substep shares the first model call result. The results are averaged together. Note: Since the first model call is shared and the initial input is the same for each substep, there is no point in running multiple identical substeps. Also note: This merge strategy doesn't work well with non-ancestral samplers (i.e. dpmpp_2m or any sampler witheta: 0).overshoot: The model is called at least once per step. It will sample steps equal to the number of substeps, starting from the current step. Then it will restart back to the expected step.lookahead: Similar toovershoot, it samples ahead based on the number of substeps. The last model prediction is used to do a Euler step to the expected step. Note: Very experimental, likely to change in the future.pingpong: Works similar toovershootandlookaheadmethods except it does a pingpong sampler style step to the expected sigma.dynamic: Allows specifying the group parameters as an expression to be evaluated. See below.
Dynamic Groups: When merge_method is set to dynamic you must specify a dynamic block in the text parameters. The dynamic block may be either a string with the expression or a list of objects with an (optional) when key and a (required) expression key. The expression should return a dictionary of parameters you can set in the node (including both keys/values from the text parameters and widgets in the node). The first matching item will be used. Example:
# Use the simple merge method when step < 3, otherwise use overshoot
dynamic:
- when: step < 3
expression: dict(merge_method :> 'simple)
- expression: dict(merge_method :> 'overshoot)
# You could also write it like this:
dynamic: |
dict(merge_method :> (step < 3 ? 'simple : 'overshoot)
Node Parameters
merge_method: One of the merge methods described above in the Merging section.time_mode(step): One ofstep,step_pct,sigma. Time matching mode. Matching based on steps generally will be simplest. Matches are inclusive and steps start at 0 (so step 0 is the first step).step_pctis the percentage of total steps (1.0=100%, 0.5=50%, etc).time_start(0): Match start time.time_end(999): Match end time.
Example:
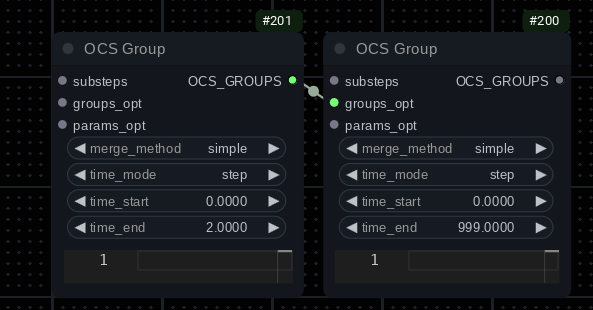
The left side group matches steps 0, 1, 2. The right side group matches all steps. This setup will use whatever substeps are connected to the first group for the first three steps and the second group will handle the rest.
Input Parameters
<!-- * `merge_sampler`: Value type: `OCS_SUBSTEPS`. Only used when `merge_method` is `sample` or `sample_uncached`. Allows defining the sampler used for merging substeps. -->restart_custom_noise: Currently only used by theovershootmerge method.custom_noise: Currently used by thelookaheadmerge method.
Text Parameters
Shown in YAML with default values.
<details> <summary>★★ Expand ★★</summary># Noise scale. May not do anything currently.
s_noise: 1.0
# ETA (basically ancestralness). May not do anything currently.
eta: 1.0
# Reversible ETA (used for reversible samplers). May not do anything currently.
reta: 1.0
# Sets the type of preview used for sampling in this group. One of:
# denoised: The default, shows the model prediction (takes positive and negative prompt into account).
# cond: Shows the model cond prediction (basically the positive prompt).
# uncond: Shows the model uncond prediction (basically the negative prompt).
# raw: Shows the raw noisy latent input.
# noisy: 10% of the noise + denoised.
# diff: Multiplies the difference between cond and uncond.
preview_mode: denoised
# Expression.
when: null
# Interpolate the schedule by the specified factor. Only used by the overshoot merge method.
#: Example if factor 2 and steps [0,1,2] you'd get [0, 0.5, 1.0, 1.5, 2]
overshoot_expand_steps: 1
# Only used by the overshoot merge method currently.
restart:
# Scales the noise added by restart sampling.
s_noise: 1.0
# Immiscible block same as described above.
immiscible:
size: 0
# Only used by the lookahead merge method currently.
lookahead:
# Works like normal samplers, essentially. Disabled by default.
eta: 0.0
# Scales the noise added by lookahead sampling.
s_noise: 1.0
# Controls how much noise to remove in the prediction phase. Higher values will remove more noise.
dt_factor: 1.0
# Immiscible block same as described above.
immiscible:
size: 0
# Only used by the pingpong merge method.
pingpong:
# Scales the noise added by lookahead sampling.
s_noise: 1.0
pre_filter: null
post_filter: null
OCS Substeps
Step Methods (Samplers)
In alphabetical order.
adapter: Wraps a normal ComfyUISAMPLER. Attach aSAMPLERparameter to the node. Note: Samplers that do unusual stuff like try to manipulate the model won't work. ComfyUI's built-in CFG++ samplers in particular do not work here.blep_bas: Batch Augmented Sampler. My own dumb experiment that expands the batch and averages the result. May be very slow/require a lot of VRAM. See parameters:basblep_euler_cycle: See parameters:cycle_pct.blep_weoon: Wavelet-based second order sampler. Another dumb experiment. See parameters:weoonbogacki: Bogacki-Shampine sampler. Also has a reversible variant.clybius_euler_dancing: Pretty broken currently, will probably require increaseds_noisevalues. See parameters:deta,leap,deta_mode.clybius_sens: Reversible dpmpp_3m_sde variant. Supports a separate set of reversible parameters intsde_reversible.deis: See parameters:history_limit. Does not work well with ETA, I don't recommending leaving ETA at the default 1.dpm2: Seteta: 0for non-ancestral variant.dpmpp_2m_sde: Also supports reversible parameters. See parameters:history_limit.dpmpp_2m:etaands_noiseparameters are ignored. See parameters:history_limit.dpmpp_2sdpmpp_3m_sde: See parameters:history_limit.dpmpp_sdedynamic: Advanced step method that allows using an expression to determine the sampler parameters at each substep. See below for a more detailed explanation.euler: If samplers came in vanilla.extraltodeus_distance: Adaptive-ish/configurable step variant of Heun. Referenced from https://github.com/Extraltodeus/DistanceSampler. See parameters:distance.gradient_estimationheun_1s: Alternate Heun one step implementation. Supports reversible parameters.heun: Alternate Heun implementation. Supports reversible parameters. See parameters:history_limit.heunpp: See parameters:max_order.ipndm_v: See parameters:history_limit.ipndm: See parameters:history_limit.pingpongres: Refined Exponential Solver. I believe this is a variant of Heun. Generally works very well.res_multistepreversible_bogacki: Reversible variant of Bockacki-Shampine.reversible_heun_1s: Reversible variant of Heun 1 step. See parameters:history_limit.reversible_heun: Reversible variant of Heun.rk_dynamic: Variant of RK4 that lets you setmax_order(you can also set it to0to choose an order dynamically, doesn't seem to work so well though).rk4: Runge-Kutta 4th order sampler.rkf45: 5 model call flavor of RK.solver_diffrax: Uses the Diffrax solver backend. Seede_*parameters below.solver_torchdiffeq: Uses the torchdiffeq backend. Seede_*parameters below.solver_torchode: Uses the torchode backend. Seede_*parameters below.solver_torchsde: Uses the torchsde backend. Seede_*parameters below.trapezoidal_cycle: See parameters:cycle_pct.trapezoidal:ttm_jvp: TTM is a weird sampler. If you're using model caching you must make sure the entries TTM uses are populated first (by having it run before any other samplers that call the model multiple times). It may also not work with some other model patches and upscale methods. See parameters:alternate_phi_2_calc
Sampler Feature Support
|Name|Cost|History|Order|Reversible|CFG++|
|-|-|-|-|-|-|
|adapter|?|?|?|?|?|
|blep_bas|variable|||||
|blep_euler_cycle|1||||X|
|blep_trapezoidal_cycle|2|||||
|blep_weoon|2|||||
|bogacki|2|||||
|clybius_euler_dancing|1|||||
|clybius_sens|1|1||||
|deis|1|1-3 (1)||||
|dpmpp_2m_sde|1|1||||
|dpmpp_2m|1|1||||
|dpmpp_2s|2|||||
|dpmpp_3m_sde|1|1-2 (2)||||
|dpmpp_sde|2|||||
|dynamic|?|?|?|?|?|
|euler|1||||X|
|extraltodeus_distance|variable|||||
|gradient_estimation|1|1||||
|heun_1s|1|1||X||
|heun|2|||X||
|heunpp|1-3||X|||
|ipndm_v|1|1-3 (1)||||
|ipndm|1|1-3 (1)||||
|pingpong|1|||||
|res|2|||||
|res_multistep|1|1||||
|reversible_bogacki|2|||X||
|reversible_heun_1s|1|1||X||
|reversible_heun|2|||X||
|rk4|1-4|||||
|rk4|4|||||
|rkf45|5|||||
|solver_diffrax|variable|||||
|solver_torchdiffeq|variable|||||
|solver_torchode|variable|||||
|solver_torchsde|variable|||||
|trapezoidal|2|||||
|ttm_jvp|2|||||
deis, ipndm* and gradient_estimation do not seem to work well with ancestralness, I recommend eta: 0.25 or disable it completely.
Solver Backend Samplers:
You will need to have the relevant Python package installed in your venv to use these. TDE cannot handle batches and
each batch item will be evaluated separately. Using tode may be faster for batch sizes over 1.
ode_solver types for TDE: adaptive: dopri8, dopri5, bosh3, fehlberg2, adaptive_heun, fixed step: euler, midpoint, rk4, explicit_adams, implicit_adams
ode_solver types for TODE: adaptive only: dopri5, tsit5, heun. I haven't much luck with anything other than dopri5.
Note that adaptive solvers may be very slow. Think along the lines of 20-100 model calls per substep (or in other words, the equivalent for running that many euler steps). Tolerances only apply to adaptive solvers.
Cycle Samplers (euler_cycle, trapezoidal_cycle)
Basically a different approach to ancestral sampling. First a crash course on how sampling works:
Each step has an expected noise level, with the first step generally being pure noise and the end of the last step aiming to end with no noise remaining. Let's say the image on the current step is called x, calling the model with x gives us a prediction of what the image looks like with all noise removed (denoised), however the model is not capable of just removing all the noise in a single step: its prediction will be imprecise. x - denoised leaves us with just the noise (we subtract the prediction which theoretically has no noise from the noisy sample). This is a very simplified, but the idea is basically to add the noise back into denoised, but scaled so that it matches the amount of noise expected on the next step. denoised + noise * expected_noise_at_next_step.
When doing ancestral sampling, we actually overshoot expected noise for the next step and add less than that amount back to denoised. Then we generate some of our own noise and add it, scaled so that the result matches expected_noise_at_next_step. eta controls how the scale of the overshoot.
The difference with cycle is that instead of adding noise * expected_noise_at_next_step, we instead first add noise * (expected_noise_at_next_step * (1.0 - cycle_pct)) and then we generate noise and scale it to cycle_pct and add it too. Just for example, suppose cycle_pct is 0.2: we'll add 80% of the expected noise at the next step (1.0 - 0.2 == 0.8) and then generate the remaining 20% and add it in to meet the expected amount. I don't recommend setting cycle_pct to values over 0.5, especially if using "weird" noise types.
Dynamic Step Method: When step_method is set to dynamic you must specify a dynamic block in the text parameters. The dynamic block may be either a string with the expression or a list of objects with an (optional) when key and a (required) expression key. The first matching item will be used. The expression should return a dictionary of parameters you can set in the node (including both keys/values from the text parameters and widgets in the node). Example:
# Use the rk4 merge method when step < 3, otherwise use euler
dynamic:
- when: step < 3
expression: dict(step_method :> 'rk4)
- expression: dict(step_method :> 'euler)
# You could also write it like this:
dynamic: |
dict(step_method :> (step < 3 ? 'rk4 : 'euler)
Note: You can set all sampler parameters except substeps this way. Sampling will use the substeps value from the OCS Substeps node.
Node Parameters
substeps(1): Number of substeps. Generally involves a model call per substep, so for example setting this to 4 would approximately quadruple sampling time.step_method(euler): Method used for sampling the substeps. May include a parenthesized number (i.e.rk4 (3)) which denotes the number of extra model calls required per sample. At least one is always required. Soeulerrequires 1 in total,rk4requires 4 in total. RK4 is about 4 times slower thaneuler.
Input Parameters
custom_noise: Value type:SONAR_CUSTOM_NOISE. Allows specifying a custom noise type for samplers that generate noise (most of them).
Text Parameters
Shown in YAML with default values.
<details> <summary>★★ Expand ★★</summary># Scale for added noise.
s_noise: 1.0
# ETA (basically ancestralness).
eta: 1.0
# If the ETA calculation fails, it will retry with eta - eta_retry_increment until it either
# succeeds or eta becomes <= 0 (in which case ancestralness just gets disabled).
# In other words, you can set ETA as high as you want, set eta_retry_increment to something like 0.1 and
# it will just do whatever it takes to find an ETA that works.
eta_retry_increment: 0
# No effect unless both start and end are set. Will scale the eta value based on the
# percentage of sampling. In other words, eta*dyn_eta_start at the beginning,
# eta*dyn_eta_end at the end.
dyn_eta_start: null
dyn_eta_end: null
# alt CFG++ scale (see https://cfgpp-diffusion.github.io/)
# Based on the initial incorrect ComfyUI implementation, but it seems to
# produce decent results sometimes.
# Can also be set to a negative value (I don't recommend going lower than -0.5).
alt_cfgpp_scale: 0
# CFG++ (see https://cfgpp-diffusion.github.io/)
cfgpp: false
### Reversible Settings ###
reversible:
# 0-indexed step where reversible sampling will start.
start_step: 0
# 0-indexed last step where reversible sampling will be used.
end_step: 9999
# Scale of the reversible correction. Can also be set to a negative value.
scale: 1.0
# Reversible ETA.
eta: 1.0
# No effect unless both start and end are set. Will scale the eta value based on the
# percentage of sampling. In other words, reta*dyn_reta_start at the beginning,
# reta*dyn_reta_end at the end.
dyn_eta_start: null
dyn_eta_end: null
eta_retry_increment: 0.0
# Might not do anything currently.
use_cfgpp: false
pre_filter: null
post_filter: null
### ODE Sampler Settings ###
# Solver type.
de_solver: dopri5 # Example - varies based on solver sampler.
# Relative tolerance (log 10)
de_rtol: -1.5
# Absolute tolerance (log 10)
de_atol: -3.5
# Max model calls allowed to compute the solution. If the limit is exceeded, it is an error.
de_max_nfe: 1000
# Min sigma to sample to. If the current step start <= min sigma, then the sampler will run
# a Euler step. If the current step end <= min sigma then the slover will sample to the min
# sigma and then to a Euler step from min sigma for the rest.
de_min_sigma: 0.0292
# Hack that seems to help results by stretching the down sigma a bit. Set to 0 to disable.
de_fixup_hack: 0.025
# Used to split the step into sections. Useful for fixed step methods.
# Applies to: solver_torchode, solver_diffrax
de_split: 1
# Initial step size (as a percentage).
# Applies to: solver_torchode, solver_diffrax
de_initial_step: 0.25
# Coefficients for the step size PID controller.
# See https://en.wikipedia.org/wiki/Proportional%E2%80%93integral%E2%80%93derivative_controller
# These values seem okay with dopri5.
# Applies to: solver_tode, solver_diffrax
de_ctl_pcoeff: 0.3
de_ctl_icoeff: 0.9
de_ctl_dcoeff: 0.2
# Controls whether to compile the solver. May or may not work,
# also may or may not be a speed increase as the compiled solver is
# not cached between substeps.
# Applies to: solver_torchode
tode_compile: false
### torchsde solver specific parameters.
tsde_noise_type: "scalar"
tsde_sde_type: "stratonovich"
tsde_levy_area_approx: "none"
tsde_noise_channels: 1
tsde_g_multiplier: 0.05
tsde_g_reverse_time: true
tsde_g_derp_mode: false
tsde_batch_channels: true
### diffrax solver specific parameters.
# Turns on adaptive stepping. When enabled, de_split is not used.
# When disabled, it may be desirable to set de_split.
diffrax_adaptive: false
# Hack to make some solver methods work. May not be safe.
diffrax_fake_pure_callback: true
# Some diffrax methods don't allow adaptive stepping, enabling this
# makes them usable although it's less efficient (3x cost, 2x accuracy).
diffrax_half_solver: false
diffrax_batch_channels: false
# Some solvers require specific types of Levy area approximation.
# See: https://docs.kidger.site/diffrax/api/brownian/#levy-areas
diffrax_levy_area_approx: "brownian_increment"
# Some solvers may require manually specifying the error order.
diffrax_error_order: null
# Enables SDE mode (and SDE-specific solvers). May not be worth using.
diffrax_sde_mode: false
# Noise multiplier when SDE mode is enabled.
diffrax_g_multiplier: 0.0
# Only applies when time scaling is enabled. Reverses time.
diffrax_g_reverse_time: false
# Scales the g multiplier based on the current time.
diffrax_g_time_scaling: false
# Experimental option to flip the sign on the g multiplier when time >= half the step.
# i.e. if you'd get 1,2,3,4 as g values for the step, with this it would be 1,2,-3,-4.
diffrax_g_split_time_mode: false
# blep_bas sampler-specific parameters
bas:
# Batch expansion factor. Whatever your original batch size was will be multiplied
# by this. If it's 0 then you just get normal Euler.
batch_multiplier: 2
# First 0-indexed step when BAS sampling will apply.
start_step: 0
# Last 0-index step when BAS sampling will apply.
end_step: 3
s_noise: 1.0
eta: 0.0
eta_retry_increment: 0.0
# List of weights for the denoised batches, with 0 being the original denoised.
# If the list is smaller than the batch size, the list will be padded with the
# last item.
# If set to null it will be calculated automatically.
# Example: [0.5, 1.0]
# Will use weight 0.5 for the original denoised and 1.0 for any other items.
denoised_factors: null
# If set to something other than 0 the supplied denoised_factors will be rebalanced
# to add up to this number.
denoised_factors_scale: 1.0
# Global multiplier on denoised for BAS steps.
denoised_multiplier: 1.0
# One of: restart, restart_noneta, simple
renoise_mode: restart
# Multiplier on the start sigma for BAS steps.
# Note that taking the multipliers into account sigma_next must be less than sigma.
fromstep_factor: 1.0
# Multiplier on the end sigma for BAS steps.
tostep_factor: 1.0
# Source for the downstep. Can be one of dt, sigma or sigma_next.
# dt means you get bsigma + (sigma_next - bsigma) * tostep_factor
# where bsigma = sigma * fromstep_factor
tostep_source: dt
# blep_weoon sampler-specific options.
# Parameters with "inv" in the name apply to the inverse wavelet operation.
# When set to null, they will use the normal setting.
weoon:
start_step: 0
end_step: 9999
eta: 0.0
eta_retry_increment: 0.0
s_noise: 1.0
# One of dwt, dwt1d, dtcwt
wavelet_mode: dwt
# Padding scheme used for wavelets
padding: periodization
# Padding scheme used for the inverse wavelet operation
inv_padding: null
# Wavelet type. Does not apply if wavelet_mode is dtcwt.
wave: db4
# Wavelet type used for the inverse wavelet operation. Does not apply if wavelet_mode is dtcwt.
inv_wave: null
# dtcwt qshift parameter. Only applies if the wavelet mode is dtcwt.
dtcwt_qshift: qshift_a
# dtcwt biort parameter. Only applies if the wavelet mode is dtcwt.
dtcwt_biort: near_sym_a
# dtcwt qshift parameter used for the inverse wavelet operation. Only applies if the wavelet mode is dtcwt.
dtcwt_inv_qshift: null
# dtcwt biort parameter used for the inverse wavelet operation. Only applies if the wavelet mode is dtcwt.
dtcwt_inv_biort: null
# Can be used to stretch the step down. I.E. 1.0 would be sigma -> sigma_next
# while 2.0 would be twice the distance between sigma and sigma_next.
downstep_scale: 1.0
# Blend scale for the downstep denoised lowpass wavelets
yl_strength: 1.0
# Blend scale for the downstep denoised highpass wavelets
yh_strength: 0.5
# Mode used for blending wavelets.
wavelet_blend_mode: lerp
# Blend mode for wavelet highpass, uses wavelet_blend_mode if null.
wavelet_blend_mode_yh: null
# Extra multipliers that can be applied to the low/highpass wavelets for the normal
# denoised or downstep denoised.
denoised_yl_multiplier: 1.0
denoised_yh_multiplier: 1.0
denoised_down_yl_multiplier: 1.0
denoised_down_yh_multiplier: 1.0
# Only applies when wavelet_mode is dwt1d. Can be:
# 2: Flatten starting at spatial dimensions
# 1: Flatten starting at channels dimension
# 0: Smash everything together!
flatten_start_dim: 2
### Other Sampler Specific Parameters ###
# Used for some samplers that use history from previous steps.
# List of samplers and default value below:
# dpmpp_2m: 1
# dpmpp_2m_sde: 1
# dpmpp_3m_sde: 2
# reversible_heun_1s: 1
# ipndm: 1 (max 3)
# ipndm_v: 1 (max 3)
# deis: 1 (max 3)
# clybius_sens: 2
history_limit: 999 # Varies based on sampler.
# Used for some samplers with variable order. List of samplers and default value below:
# heunpp2: 3
# rk_dynamic: 4 - Can also be set to 0 to try to dynamically adjust the order based on calculated
# error from the last step (but that may not work well).
max_order: 999 # Varies based on sampler.
# Used for dpmpp_2m. One of midpoint, heun
solver_type: "midpoint"
# Coefficients mode for DEIS. One of tab or rhoab.
deis_mode: "tab"
# Used for samplers with cycle in the name. Controls how much noise is cycled per step.
cycle_pct: 0.25
# Used for ttm_jvp. Supposed works better when ETA > 0
alternate_phi_2_calc: true
# Parameters for dancing samplers:
# Number of steps to leap ahead.
leap: 2
# ETA for dance steps
deta: 1.0
# dyn_deta works the same as dyn_eta/reta. See above.
dyn_deta_start: null
dyn_deta_end: null
# One of lerp, lerp_alt, deta
dyn_deta_mode: "lerp"
OCS Param and OCS MultiParam
Allows specifying parameter inputs that can't be expressed with YAML, such as custom noise.
Node Parameters
key: Determines the parameter input type.
Input Parameters
value: Input for the actual parameter - must match the specified input type or you will get an error when you evaluate the workflow.params_opt: Allows connecting anotherOCS ParamorOCS MultiParamnode to specify multiple parameters.
Text Parameters
Allows specifying extra parameters. You may use this block to rename a key, for example if your key type was custom_noise you could enter:
rename: test
in the OCS Param node and:
custom_noise: test
in the node that was connected to the params to have it use the custom noise specifically named test.
OCS MultiParam
MultiParam is the same as Param except it has multiple optional inputs like key_1, key_2, etc.
Text Parameters
Same as OCS Param (see above), however if set you should use an object with a key corresponding to the index of the param. For example, if you wanted to rename key_1 and key_2 you would do something like:
1:
rename: test1
2:
rename: test2
OCS SimpleRestartSchedule
Generates a restart schedule.
Node Parameters
start_step: 0-based first step for the restart schedule to apply.
Input Parameters
sigmas: Sigmas to restartify. Output from any normal schedule node.
Text Parameters
JSON or YAML schedule in list form.
- [4, -3]
- [2, -1]
- 1
Each item should be one of:
- A pair
[interval, jump]- afterintervalsteps, make a relative jump ofjumpsteps. - A single integer
schedule_index: resume the schedule at the specified 0-based index.
The example above means:
- After 4 steps, jump back 3 steps.
- After 2 steps, jump back one step.
- Go to the second item (after 2 steps, jump back one step).
The node start_step parameter is effectively the same as [start_step, 0] as a schedule item.
OCSNoise to SONAR_CUSTOM_NOISE
Adapter that enables using OCS noise generators with nodes that accept SONAR_CUSTOM_NOISE.
Most built-in OCS nodes will accept either type currently.
OCSNoise PerlinSimple
Generates 2D or 3D Perlin noise with many tuneable parameters. Can be plugged in to samplers for ancestral or SDE sampling. For initial noise or img2img workflows, use the NoisyLatentLike node from ComfyUI-sonar (see Integration).
3D Perlin noise works by taking a slice in the depth dimension each time the noise sampler is called.
For more tuneable parameters, see the OCSNoise PerlinAdvanced node.
Note: The shape of the latent must be a multiple of lacunarity ** (octaves - 1) * res (** indicates raising something to a power). Most latent types will have one latent pixel equaling eight normal pixels - i.e. if your image is 512x512, the latent would be 64x64.
Node Parameters
depth: When non-zero, 3D perlin noise will be generated.detail_level: Controls the detail level of the noise whenbreak_patternis non-zero. No effect when using 100% raw Perlin noise.octaves: Generally controls the detail level of the noise. Each octave involves generating a layer of noise so there is a performance cost to increasing octaves.persistence: Controls how rough the generated noise is. Lower values will result in smoother noise, higher values will look more like Gaussian noise. Comma-separated list, multiple items will apply to octaves in sequence.lacunarity: Lacunarity controls the frequency multiplier between successive octaves. Only has an effect when octaves is greater than one. Comma-separated list, multiple items will apply to octaves in sequence.res_height: Number of periods of noise to generate along an axis. Comma-separated list, multiple items will apply to octaves in sequence.break_pattern: Applies a function to break the Perlin pattern, making it more like normal noise. The value is the blend strength, where 1.0 indicates 100% pattern broken noise and 0.5 indicates 50% raw noise and 50% pattern broken noise. Generally should be at least 0.9 unless you want to generate colorful blobs.
OCSNoise PerlinAdvanced
Generates 2D or 3D Perlin noise with many tuneable parameters. Can be plugged in to samplers for ancestral or SDE sampling. For initial noise or img2img workflows, use the NoisyLatentLike node from ComfyUI-sonar (see Integration).
3D Perlin noise works by taking a slice in the depth dimension each time the noise sampler is called.
Note: The shape of the latent in the relevant dimension including padding must be a multiple of lacunarity ** (octaves - 1) * res. Most latent types will have one latent pixel equaling eight normal pixels - i.e. if your image is 512x512, the latent would be 64x64.
Node Parameters
depth: When non-zero, 3D perlin noise will be generated.detail_level: Controls the detail level of the noise whenbreak_patternis non-zero. No effect when using 100% raw Perlin noise.octaves: Generally controls the detail level of the noise. Each octave involves generating a layer of noise so there is a performance cost to increasing octaves.persistence: Controls how rough the generated noise is. Lower values will result in smoother noise, higher values will look more like Gaussian noise. Comma-separated list, multiple items will apply to octaves in sequence.lacunarity_height: Lacunarity controls the frequency multiplier between successive octaves. Only has an effect when octaves is greater than one. Comma-separated list, multiple items will apply to octaves in sequence.lacunarity_width: " "lacunarity_depth: " "res_height: Number of periods of noise to generate along an axis. Comma-separated list, multiple items will apply to octaves in sequence.res_width: " "res_depth: " "break_pattern: Applies a function to break the Perlin pattern, making it more like normal noise. The value is the blend strength, where 1.0 indicates 100% pattern broken noise and 0.5 indicates 50% raw noise and 50% pattern broken noise. Generally should be at least 0.9 unless you want to generate colorful blobs.initial_depth: First zero-based depth index the noise generator will return. Only has an effect when depth is non-zero.wrap_depth: If non-zero, instead of generating a new chunk of noise when the last slice is used will instead jump back to the specified zero-based depth index. Only has an effect when depth is non-zero. Since this is repeating the same noise, you may need to reduces_noisein samplers especially if yourdepthvalue is low.max_depth: Basically crops the depth dimension to the specified value (inclusive). Negative values start from the end, the default of -1 does no cropping. Only has an effect when depth is non-zero. The reason you might want to use this is changingdepthwill also effectively change the seed.tileable_height: Makes the specified dimension tileable. (May or may not work correctly.)tileable_width: " "tileable_depth: " "blend: Blending function used when generating Perlin noise. When set to values other than LERP may not work at all or may not actually generate Perlin noise. If you haveComfyUI-blehthere will be many more blending options (see Integration).pattern_break_blend: Blending function used to blend pattern broken noise with raw noise. If you haveComfyUI-blehthere will be many more blending options (see Integration).depth_over_channels: When disabled, each channel will have its own separate 3D noise pattern. When enabled, depth is multiplied by the number of channels and each channel is a slice of depth. Only has an effect when depth is non-zero.pad_height: Pads the specified dimension by the size. Equal padding will be added on both sides and cropped out after generation.pad_width: " "pad_depth: " "initial_amplitude: Controls the amplitude for the first octave. The amplitude gets multiplied bypersistenceafter each octave.initial_frequency_height: Controls the frequency for the first octave for the this axis. The frequency gets multiplied bylacunarityafter each octave.initial_frequency_width: " "initial_frequency_depth: " "normalize: Controls whether the output noise is normalized after generation.device: Controls what device is used to generate the noise. GPU noise may be slightly faster but you will get different results on different GPUs.
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.