ComfyUI Extension: ComfyUI-Fast-Style-Transfer
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
ComfyUI node for fast neural style transfer. This is a simple conversion based on this: a/https://github.com/rrmina/fast-neural-style-pytorch Only basic inference functionality is ported for now.
Looking for a different extension?
Custom Nodes (3)
README
ComfyUI-Fast-Style-Transfer
ComfyUI node for fast neural style transfer.
This is a simple conversion based on this: https://github.com/rrmina/fast-neural-style-pytorch
[Experimental] Also ported regular neural style transfer from here: https://github.com/gordicaleksa/pytorch-neural-style-transfer But it's much slower and not that useful but you can play with it if you want
Installation
Probably the usual. Just "git clone https://github.com/zeroxoxo/ComfyUI-Fast-Style-Transfer.git" into your custom_nodes folder. That should be it.
If it doesn't work then idk, ask stack exchange or something, how should I know what's wrong with your setup? I use portable setup of ComfyUI so if it doesn't work try it with portable version
Training
First you'll need to download some files:
VGG-16: https://github.com/jcjohnson/pytorch-vgg
Put it into vgg folder.
MS COCO train dataset.
Original repo suggests train-2014 dataset from here: https://cocodataset.org/#download
But be wary that it's 13Gb.
I used MS COCO train-2017 dataset downscaled to 256x256 from here: https://academictorrents.com/details/eea5a532dd69de7ff93d5d9c579eac55a41cb700
It's only 1.64Gb and original repo still used training with 256x256 size images but it manually downscaled it from the 13Gb dataset.
Put the train-2017 (or train-2014) folder into dataset folder.
That's it for downloads.
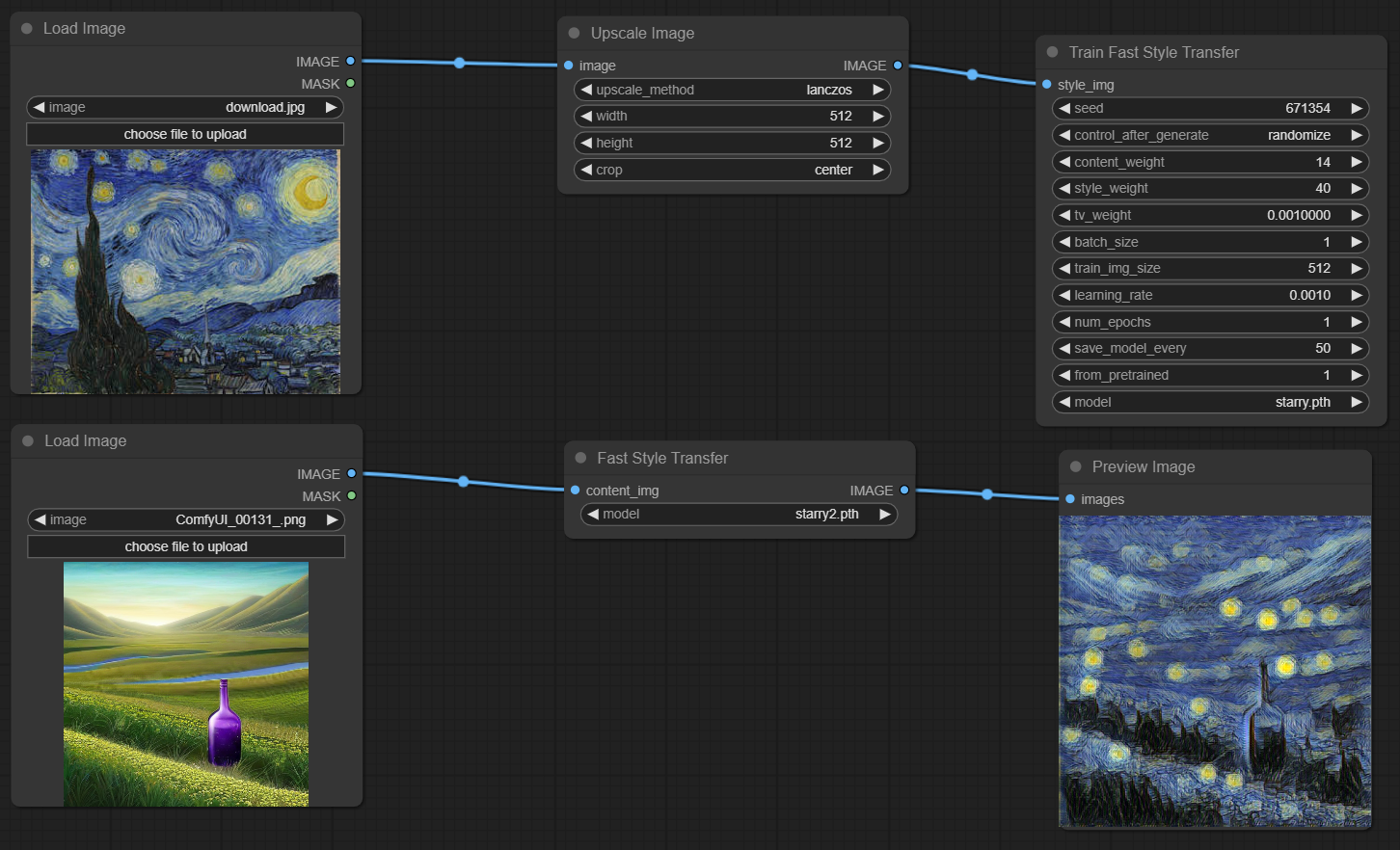
Now just use ComfyUI to load TrainFastStyleTransfer node.
To select style picture load "load_image" node and connect it with the TFST node.
Default content_weight, style_weight and tv_weight should be good starting points. Increase style_weight if you need more style, tv_weight affects sharpness of style features, needs experimenting but seems to be very useful in controlling how style applies to the image.
Adjusting batch_size as high as you can with your vram doesn't seem to do much. So just use default 4 with img_size of 256.
You probably won't need to wait for whole epoch either, just train until total loss stops getting reliably lower and just fluctuates around the same ballpark.
Use one of the pretrained models as a starting point, helps to reduce training time drastically.
save_model_every will save model and produce test picture every n-th step of training.
After setting all parameters just queue prompt and don't wait until training is done. Set save_model_every to a low value like 100 or 200 and look at pictures it produces (intermediate pictures saved in outputs folder). Starting with pretrained model should produce good enough model in less than 2000 training steps. As soon as you're fine with the result just close the training script.
All intermediate models will be saved in models folder, test them, delete redundant and rename the one you like.
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.