
ComfyUI Extension: ComfyUI-ChatTTS
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
A ComfyUI integration for a/ChatTTS, enabling high-quality, controllable text-to-speech generation directly in your ComfyUI workflows.
Looking for a different extension?
Custom Nodes (7)
README
ComfyUI-ChatTTS
A ComfyUI integration for ChatTTS, enabling high-quality, controllable text-to-speech generation directly in your ComfyUI workflows.
Example Workflows
Basic Text-to-Speech
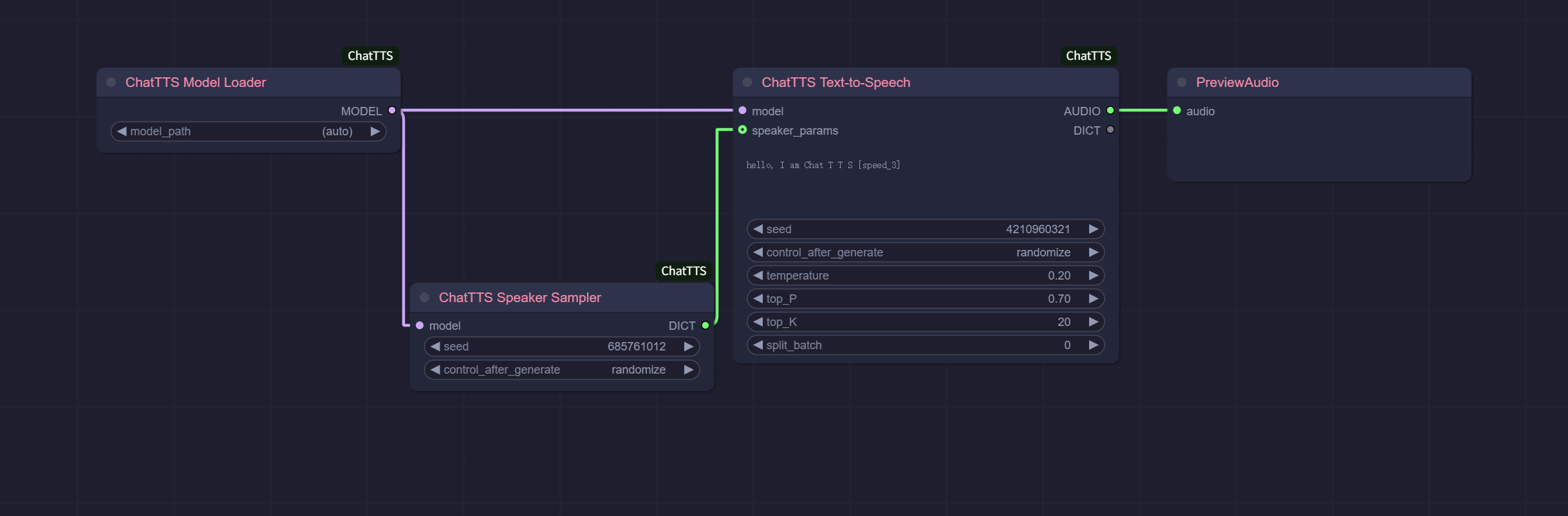
This simple workflow demonstrates basic text-to-speech conversion:
- Load the ChatTTS model
- Sample a random speaker voice
- Convert text to speech
- Preview the audio output
Features
- High-Quality Voice Synthesis - Generate natural-sounding speech from text input
- Voice Control - Sample random speakers or customize voice characteristics
- Parameter Adjustment - Fine-tune temperature, top-P, top-K and other generation parameters
- Batch Processing - Support for batch text processing through split_batch option
- Seamless Integration - Works directly with ComfyUI's audio nodes
Installation
Prerequisites
- A working installation of ComfyUI
- Python 3.8+ with PyTorch installed
Using ComfyUI Manager (Recommended)
- Install ComfyUI Manager
- Search for "ChatTTS" and install
Manual Installation
- Navigate to your ComfyUI's
custom_nodesdirectory - Clone this repository:
git clone https://github.com/neverbiasu/ComfyUI-ChatTTS - Install the requirements:
cd ComfyUI-ChatTTS pip install -r requirements.txt
Model Setup
ChatTTS models will be automatically downloaded when first used, or you can manually place them in:
ComfyUI/models/chattts/
The first time you run the ChatTTSLoader node, it will:
- Check for existing models in the models/chattts directory
- If none are found, download models from the official repository
- Load the model for use in your workflows
ChatTTS Control Tags
ChatTTS supports various special tags that can be inserted into your text to control the speech generation. These tags allow you to customize the speech output without changing the model parameters.
| Tag | Range | Description |
| ------------ | ----- | ------------------------------------------------------- |
| [speed_n] | 1-9 | Controls speech speed (higher numbers = faster) |
| [oral_n] | 0-9 | Controls oral expressiveness style |
| [laugh_n] | 0-2 | Controls laughter intensity |
| [break_n] | 0-7 | Controls pause duration (higher numbers = longer pause) |
| [uv_break] | - | Inserts a brief pause/break at the word level |
| [lbreak] | - | Inserts a longer pause/break (similar to line break) |
| [laugh] | - | Inserts laughter at the specified position |
Acknowledgements
License
This project is licensed under the MIT License - see the LICENSE file for details.
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.