
ComfyUI Extension: LM Studio Image to Text Node for ComfyUI
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
A custom node for ComfyUI that integrates LM Studio's vision models to generate text descriptions of images. It provides a flexible and customizable way to add image-to-text capabilities to your ComfyUI workflows, working with LM Studio's local API.
Looking for a different extension?
Custom Nodes (5)
README
LM Studio Nodes for ComfyUI
Author: Matt John Powell
This extension provides a suite of custom nodes for ComfyUI that deeply integrate LM Studio's capabilities using the official lmstudio Python SDK. It allows you to leverage locally run models for various generative tasks directly within your ComfyUI workflows.
The nodes offer functionalities including:
- Unified Generation: Generate text from text prompts, image prompts, or both combined.
- Image to Text: Generate detailed text descriptions of images using vision models.
- Text Generation: Generate text based on a given prompt using language models, with streaming support.
- Model Management: List available models, load models into memory with a TTL, and unload them.
- Model Selection: Dynamically select models based on type (LLM/Vision) and text filters.
- Setup Assistance: Helper node for SDK installation check, model listing, and download guidance.
- Random List Picker: Paste any newline-separated list of items and randomly select one or many each run — great for injecting random genres, styles, moods, subjects, or any variable into your prompts.
Workflow Example
Here's an example of how the LM Studio nodes can be used in a ComfyUI workflow:
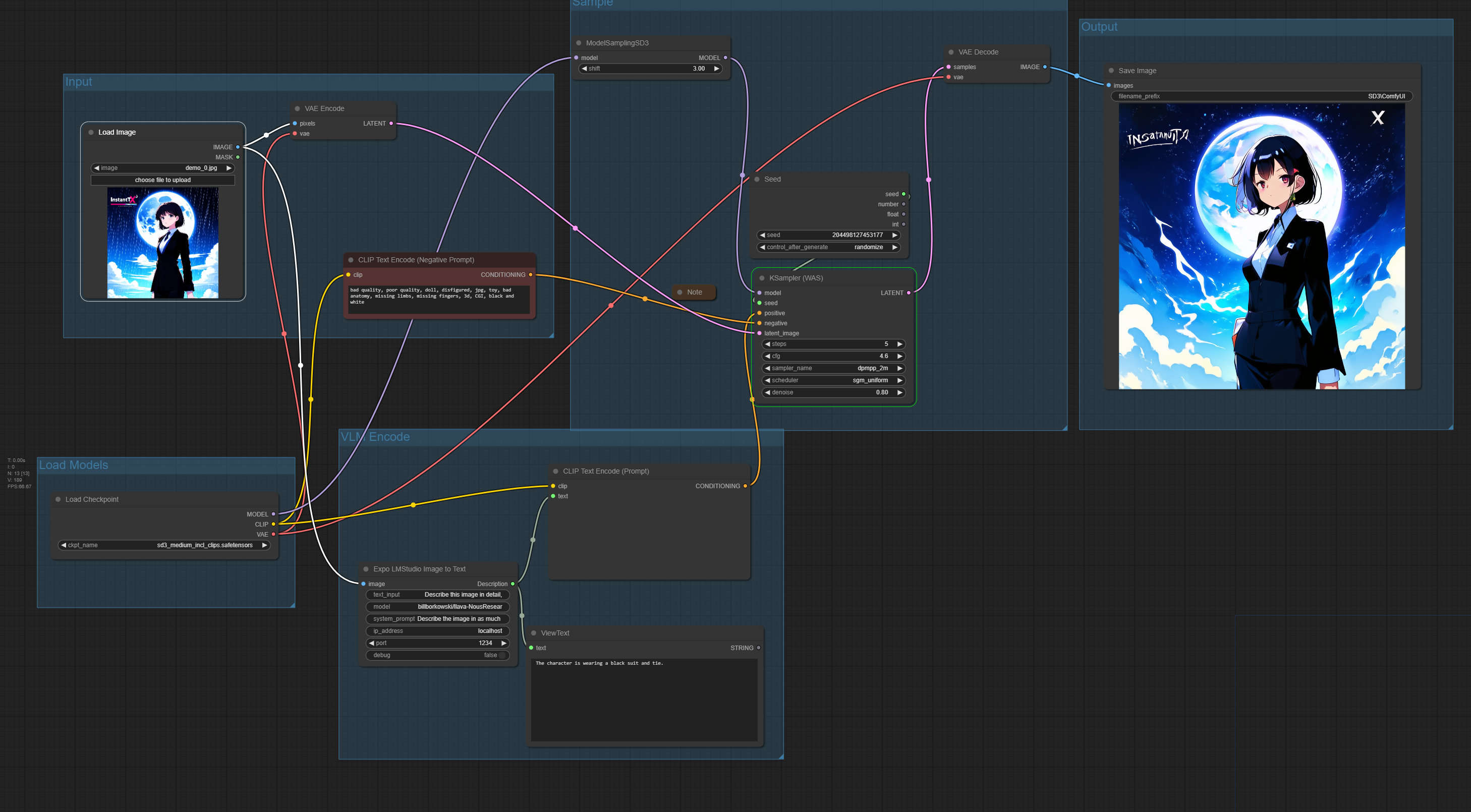 (Ensure this image accurately reflects a workflow using the new nodes)
(Ensure this image accurately reflects a workflow using the new nodes)
Features
- Utilizes the official
lmstudioPython SDK for robust connection and interaction. - Supports text-only, image-only (vision), and combined text+image inputs.
- Identifies models using
model_keystrings (e.g.,llama-3.2-1b-instruct). - Provides dedicated nodes for specific tasks (Image-to-Text, Text Generation).
- Includes nodes for managing model memory (Load/Unload/List).
- Offers a dynamic model selector node for easier workflow building.
- Setup node provides guidance for installing the SDK and getting models.
- Customizable system prompts for context setting.
- Control over generation parameters like
max_tokens,temperature, andseed. - Optional streaming output for the Text Generation node.
- Debug mode for detailed console logging.
- Automatic connection to the LM Studio server (no need to specify IP/Port in nodes).
- Random List Picker utility node for injecting randomness into prompts — supports weighted items, templates, multi-pick, shuffle, case control, exclusions, and reproducible seeds.
Installation
- Navigate to your ComfyUI
custom_nodesdirectory. - Clone this repository:
cd /path/to/ComfyUI/custom_nodes git clone [https://github.com/mattjohnpowell/comfyui-lmstudio-nodes.git](https://github.com/mattjohnpowell/comfyui-lmstudio-nodes.git) ComfyExpo-LMStudioNodes # Using 'ComfyExpo-LMStudioNodes' as the directory name to avoid potential conflicts - Install Dependencies: Ensure the
lmstudiopackage is installed in ComfyUI's Python environment:# Activate your ComfyUI Python environment (if using venv, conda, etc.) first! pip install lmstudio
Troubleshooting
LM Studio Version Compatibility
If you encounter errors like:
Error processing with LM Studio: Object missing required field 'bosToken' - at '$.promptTemplate.jinjaPromptTemplate'- Other SDK-related errors after upgrading LM Studio
This usually means your LM Studio SDK version is incompatible with your LM Studio version. Solution:
-
Quick Fix: Run the upgrade helper script:
python upgrade_lmstudio.py -
Manual Fix: Upgrade the LM Studio SDK:
pip install lmstudio --upgrade -
Restart ComfyUI completely after upgrading.
Backward Compatibility
The nodes now support backward compatibility with older workflow files that used:
modelparameter instead ofmodel_keyip_addressandportparameters for HTTP connections
When old parameters are detected, the nodes will:
- Show a deprecation warning
- Automatically use the legacy HTTP mode if
ip_addressandportare provided - Map
modelparameter tomodel_keyfor SDK mode
Recommendation: Update old workflows to use the new SDK-based parameters for better performance and reliability. (You might need to use a specific pip command depending on your ComfyUI setup, e.g., for portable builds) 4. Restart ComfyUI.
Usage
Add the nodes to your workflow by right-clicking the canvas and searching for their names (e.g., "LM Studio Unified (Expo)").
LM Studio Unified (Expo)
Handles text-only, image-only, or combined text+image generation.
Inputs:
model_key(STRING, required): The key of the LM Studio model to use (e.g.,llama-3.2-1b-instructor a vision model key). Default:llama-3.2-1b-instruct.system_prompt(STRING, required): System prompt for the AI. Default: "You are a helpful AI assistant."seed(INT, required): Seed for reproducibility (-1 for random). Default: -1.image(IMAGE, optional): Input image (requires a vision-capablemodel_key).text_input(STRING, optional): Text prompt. Default: "".max_tokens(INT, optional): Max tokens for the response. Default: 1000.temperature(FLOAT, optional): Generation temperature. Default: 0.7.debug(BOOLEAN, optional): Enable console logging. Default: False.
Output:
Generated Text(STRING): The model's response.
(Note: At least one of image or text_input must be provided for the node to run).
LM Studio I2T (Expo)
Generates text descriptions for images using vision models.
Inputs:
model_key(STRING, required): The key of the vision-capable LM Studio model. Default:qwen2-vl-2b-instruct.system_prompt(STRING, required): System prompt for the AI. Default: "This is a chat between a user and an assistant. The assistant is an expert in describing images, with detail and accuracy".seed(INT, required): Seed for reproducibility (-1 for random). Default: -1.image(IMAGE, required): The input image to be described.user_prompt(STRING, optional): The prompt asking about the image. Default: "Describe this image in detail".max_tokens(INT, optional): Max tokens for the response. Default: 1000.temperature(FLOAT, optional): Generation temperature. Default: 0.7.debug(BOOLEAN, optional): Enable console logging. Default: False.
Output:
Description(STRING): The generated text description.
LM Studio Text Gen (Expo)
Generates text based on a text prompt using language models.
Inputs:
model_key(STRING, required): The key of the LM Studio language model. Default:llama-3.2-1b-instruct.system_prompt(STRING, required): System prompt for the AI. Default: "You are a helpful AI assistant.".seed(INT, required): Seed for reproducibility (-1 for random). Default: -1.prompt(STRING, optional): The input prompt for text generation. Default: "Generate a creative story:".max_tokens(INT, optional): Max tokens for the response. Default: 1000.temperature(FLOAT, optional): Generation temperature. Default: 0.7.stream_output(BOOLEAN, optional): Stream response fragments (Note: final output in ComfyUI is still the complete text). Default: False.debug(BOOLEAN, optional): Enable console logging. Default: False.
Output:
Generated Text(STRING): The generated text.
(Note: Requires a non-empty prompt to run).
LM Studio Model Mgr (Expo)
Manages models loaded via the LM Studio SDK.
Inputs:
action(COMBO, required): Action to perform (LIST,LOAD,UNLOAD). Default:LIST.model_key(STRING, optional): The model key to load or unload. Required forLOAD/UNLOAD. Default: "".model_type(COMBO, optional): Filter models by type (ALL,LLM,EMBEDDING). Default:ALL.load_ttl(INT, optional): Time-to-live (seconds) for loaded models (how long to keep in memory after last use). Used withLOAD. Default: 3600.debug(BOOLEAN, optional): Enable console logging. Default: False.
Output:
Result(STRING): Confirmation message or list of models.
LM Studio Model Sel (Expo)
Dynamically provides a model key based on filters, useful for connecting to other nodes.
Inputs:
model_type(COMBO, required): Type of model to list (LLM,Vision). Default:LLM.filter_text(STRING, optional): Text to filter model names/keys by. Default: "".
Output:
Model Key(STRING): Themodel_keyof the first matching model (sorted alphabetically), or a default if none match.
(Note: This node attempts to list models available via the SDK at workflow load time. Ensure LM Studio server is running when building workflows).
LM Studio Setup (Expo)
Provides helper actions related to SDK setup and model discovery.
Inputs:
action(COMBO, required): Action to perform (INSTALL SDK,GET MODEL,LIST MODELS). Default:LIST MODELS.model_key(STRING, required): Model key relevant to the action (used forGET MODEL). Default:llama-3.2-1b-instruct.
Output:
Result(STRING): Status message, command guidance, or list of models.
(Note: INSTALL SDK attempts pip install lmstudio. GET MODEL provides instructions for using the lms CLI tool).
Random List Picker
A general-purpose utility node. Paste any newline-separated list of items and the node randomly selects one (or many) each time the workflow runs, then assembles a ready-to-use prompt string. No LM Studio connection required — works standalone.
Inputs:
| Input | Type | Default | Description |
|---|---|---|---|
| items | STRING (multiline) | sample genres | One item per line. Append ::weight for weighted probability (e.g. jazz::3 is 3× more likely than weight-1 items). |
| template | STRING (multiline) | (empty) | Prompt template using {item} as a placeholder, e.g. "Create a {item} track with heavy bass." Overrides prefix/suffix when non-empty. |
| prefix | STRING | (empty) | Text prepended before the chosen item(s). Used when template is empty. |
| suffix | STRING | (empty) | Text appended after the chosen item(s). Used when template is empty. |
| exclude | STRING (multiline) | (empty) | Items that must never be chosen, one per line (case-insensitive). |
| fallback | STRING | (empty) | Value returned when the list is empty after exclusions apply. |
| count | INT | 1 | Number of unique items to pick. Automatically capped at the list size. |
| separator | STRING | , | String used to join multiple picked items. |
| case | COMBO | original | Case transformation: original | uppercase | lowercase | title | sentence. |
| mode | COMBO | pick | pick — choose random item(s). shuffle — return the entire list in a random order. |
| seed | INT | -1 | Random seed. -1 = new random result every run; any other value = reproducible. |
Outputs:
| Output | Type | Description |
|---|---|---|
| selected_item | STRING | The chosen item(s), joined with separator. |
| prompt | STRING | Fully assembled prompt (template or prefix + item + suffix). Wire this directly into any text input. |
| item_count | INT | Total usable items after exclusions. |
| selected_index | INT | Zero-based index of the first chosen item (-1 in shuffle mode). |
Example — random music genre prompt:
items:
rock
pop
jazz::3
classical
hip-hop
template: Create a {item} song with a melancholic mood.
Each run the node draws a weighted-random genre and outputs something like:
Create a jazz song with a melancholic mood.
Example — pick 3 unique styles:
count: 3
separator: ", "
template: Generate artwork combining {item}.
Output prompt: Generate artwork combining watercolour, impressionist, cyberpunk.
LM Studio Setup
- Install and run LM Studio on your machine.
- Download desired models within LM Studio (ensure you have vision models for image tasks).
- Go to the "Server" tab (icon looks like
<->) in LM Studio. - Select a model to load and click Start Server.
- The LM Studio server must be running for these ComfyUI nodes to connect and function.
Notes
- These nodes use the official
lmstudioPython SDK, which handles the connection to your running LM Studio server automatically (typicallylocalhost:1234). There's no need to input IP/Port in the nodes themselves. - Use the
model_key(found in LM Studio, e.g.,Org/ModelName-Format) as the identifier in themodel_keyinputs. - The
seedinput allows for reproducible outputs. Set to -1 for a random seed on each run.
SDK Usage
These nodes leverage the official lmstudio Python SDK, replacing the previous method of interacting via the OpenAI-compatible API endpoint directly. This provides more robust integration and access to SDK-specific features.
Troubleshooting
If you encounter any issues:
- Enable the
debuginput (set to True) on the relevant node(s). - Check the ComfyUI console for error messages and detailed debug output from the nodes.
- Verify that the LM Studio application is running and the Server has been started with a model loaded.
- Ensure the
model_keyyou are providing exists in your LM Studio library and is compatible with the node's task (e.g., a vision model for the I2T node). - Confirm the
lmstudioPython package is correctly installed in your ComfyUI environment.
For further assistance, please open an issue on the GitHub repository: https://github.com/mattjohnpowell/comfyui-lmstudio-nodes
License
This project is licensed under the MIT License - see the LICENSE file for details.
Acknowledgments
- Built upon the ComfyUI framework.
- Utilizes the official LM Studio Python SDK.
- Inspired by LM Studio's capabilities and examples.
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.