ComfyUI Extension: ComfyUI-depth-fm
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
Fast and accurate monocular depth estimation.
README
ComfyUI node to use depth-fm monocular depth estimation model
Installing
Either use the ComfyUI-Manager, or clone this repo to custom_nodes and run:
pip install -r requirements.txt
or if you use portable (run this in ComfyUI_windows_portable -folder):
python_embeded\python.exe -m pip install -r ComfyUI\custom_nodes\ComfyUI-depth-fm\requirements.txt
Pruned models as safetensors are available in the ComfyUI-Manager, or from here:
https://huggingface.co/Kijai/depth-fm-pruned/tree/main
They go in the ComfyUI/models/checkpoints
Original model from https://ommer-lab.com/files/depthfm/depthfm-v1.ckpt
Any SD1.5/2.1 VAE should work with the node.
Original repository:
<p align="center"> <!-- <h2 align="center">📻 DepthFM: Fast Monocular Depth Estimation with Flow Matching</h2> --> <h2 align="center"><img src=assets/figures/radio.png width=28> DepthFM: Fast Monocular Depth Estimation with Flow Matching</h2> <p align="center"> Ming Gui<sup>*</sup> · Johannes S. Fischer<sup>*</sup> · Ulrich Prestel · Pingchuan Ma </p><p align="center"> Dmytro Kotovenko · Olga Grebenkova · Stefan A. Baumann · Vincent Tao Hu · Björn Ommer </p> <p align="center"> <b>CompVis Group @ LMU Munich</b> </p> <p align="center"> <sup>*</sup> <i>equal contribution</i> </p> </p> </p>![]()

📻 Overview
We present DepthFM, a state-of-the-art, versatile, and fast monocular depth estimation model. DepthFM is efficient and can synthesize realistic depth maps within a single inference step. Beyond conventional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting and depth conditional synthesis.
With our work we demonstrate the successful transfer of strong image priors from a foundation image synthesis diffusion model (Stable Diffusion v2-1) to a flow matching model. Instead of starting from noise, we directly map from input image to depth map.
🛠️ Setup
This setup was tested with Ubuntu 22.04.4 LTS, CUDA Version: 12.2, and Python 3.11.5.
First, clone the github repo...
git clone [email protected]:CompVis/depth-fm.git
cd dfm
Then download the weights via
wget https://ommer-lab.com/files/depthfm/depthfm-v1.ckpt -P checkpoints/
Now you have either the option to setup a virtual environment and install all required packages with pip
pip install -r requirements.txt
or if you prefer to use conda create the conda environment via
conda env create -f environment.yml
Now you should be able to listen to DepthFM! 📻 🎶
🚀 Usage
You can either use the notebook inference.ipynb or just run the python script inference.py as follows
python inference.py \
--num_steps 2 \
--ensemble_size 4 \
--img assets/dog.png \
--ckpt checkpoints/depthfm-v1.ckpt
The argument --num_steps allows you to set the number of function evaluations. We find that our model already gives very good results with as few as one or two steps. Ensembling also improves performance, so you can set it via the --ensemble_size argument. Currently, the inference code only supports a batch size of one for ensembling.
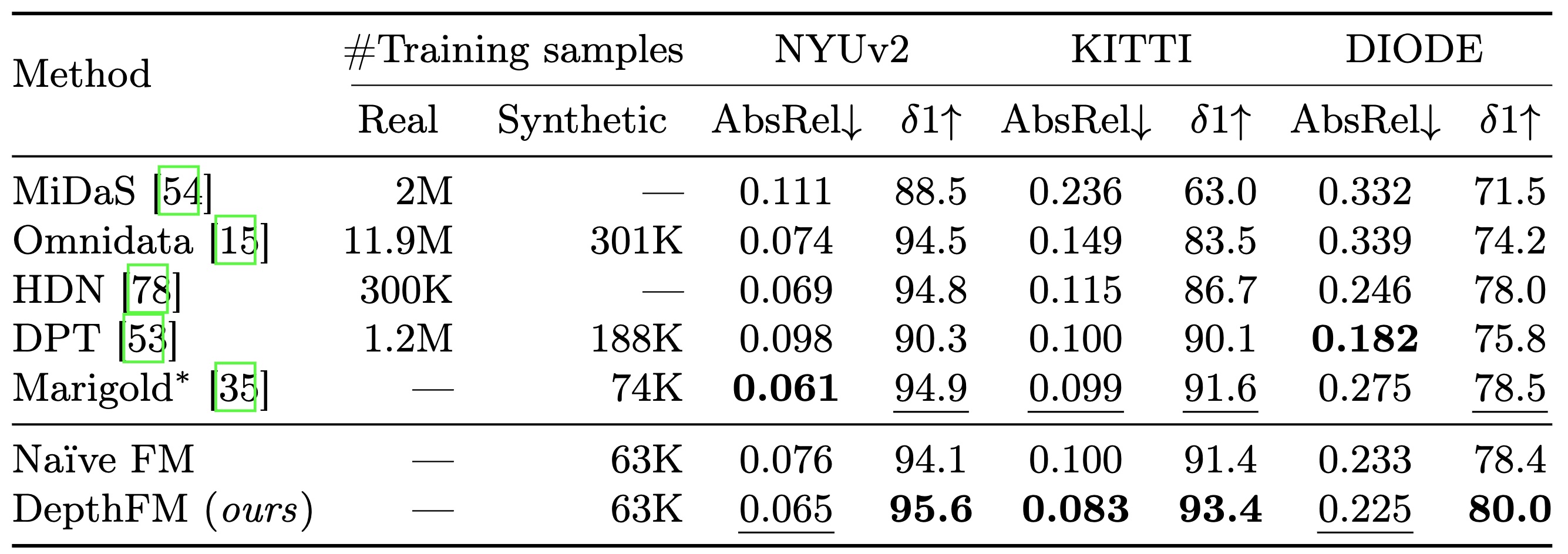
📈 Results
Our quantitative analysis shows that despite being substantially more efficient, our DepthFM outperforms the current state-of-the-art generative depth estimator Marigold zero-shot on a range of benchmark datasets. Below you can find a quantitative comparison of DepthFM against other affine-invariant depth estimators on several benchmarks.
🎓 Citation
Please cite our paper:
@misc{gui2024depthfm,
title={DepthFM: Fast Monocular Depth Estimation with Flow Matching},
author={Ming Gui, Johannes S. Fischer, Ulrich Prestel, Pingchuan Ma, Dmytro Kotovenko, Olga Grebenkova, Stefan Andreas Baumann, Vincent Tao Hu, Björn Ommer},
year={2024},
eprint={2403.13788},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.