ComfyUI Extension: ComfyUI-FastVideo
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
A custom node suite for ComfyUI that provides accelerated video generation using a/FastVideo. See the a/blog post about FastVideo V1 to learn more.
Looking for a different extension?
Custom Nodes (0)
README
ComfyUI-FastVideo
A custom node suite for ComfyUI that provides accelerated video generation using FastVideo. See the blog post about FastVideo V1 to learn more.
Multi-GPU Parallel Inference
One of the key features ComfyUI-FastVideo brings to ComfyUI is its ability to distribute the generation workload across multiple GPUs, resulting in significantly faster inference times.
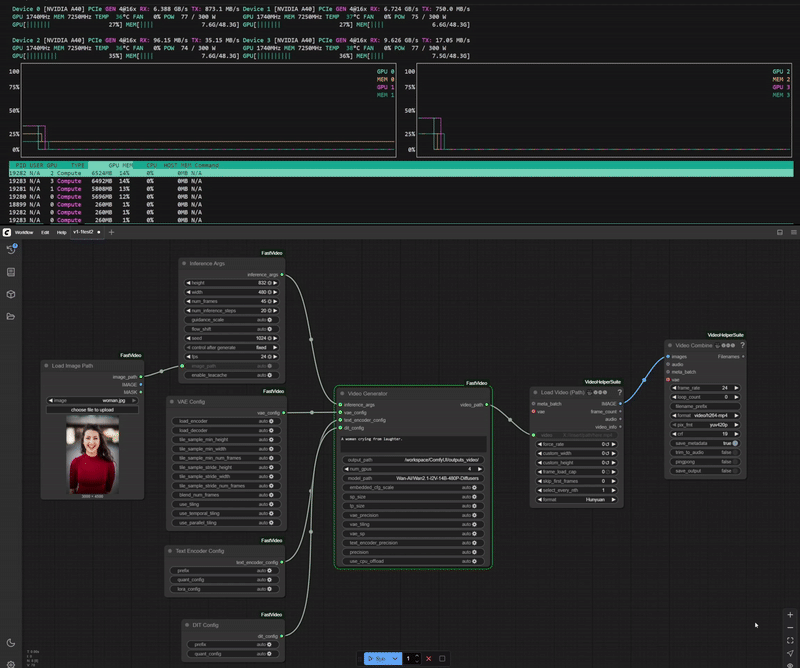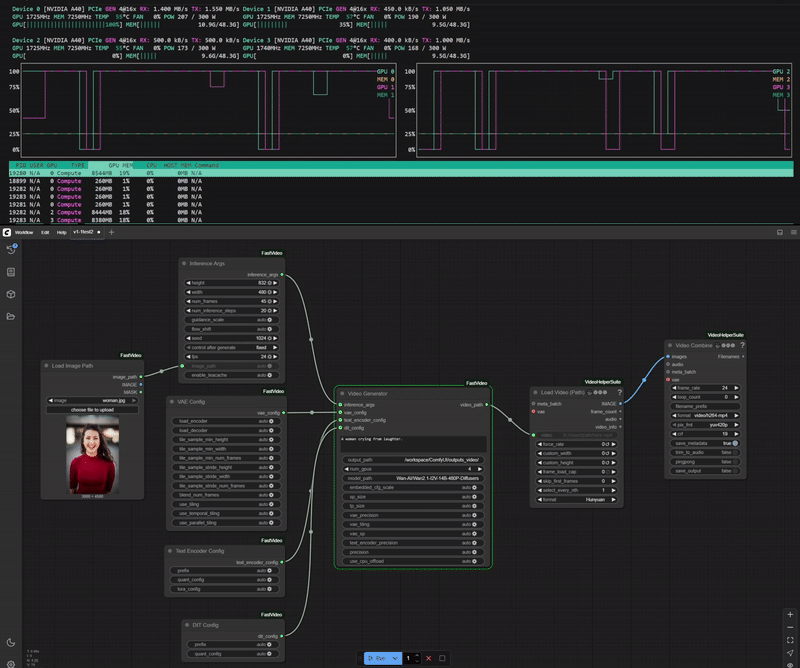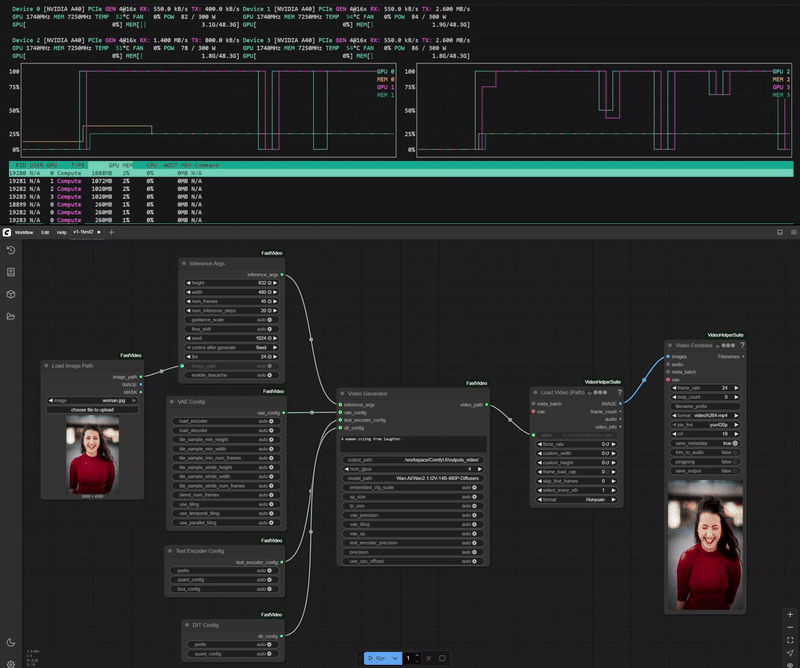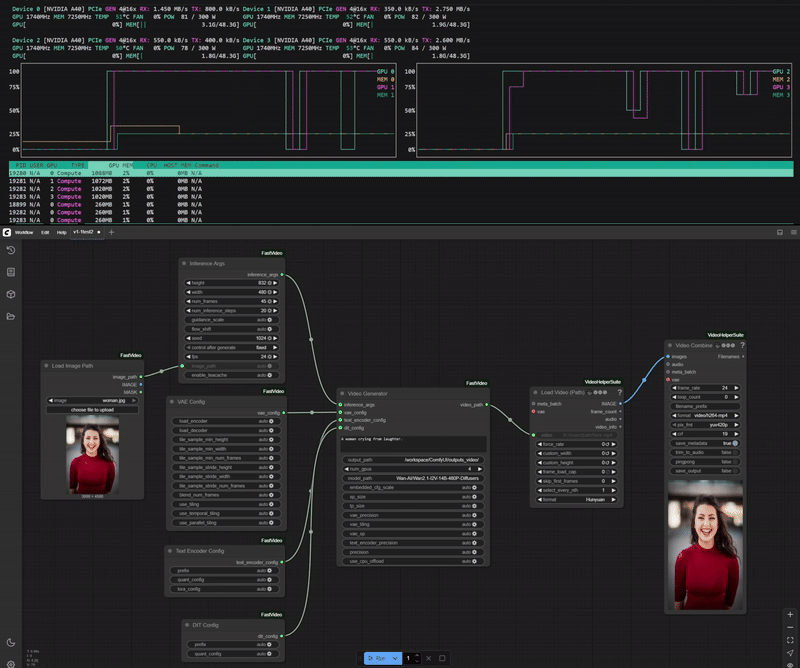
Example of Wan2.1-I2V-14B-480P-Diffusers model running on 4 GPUs.
Features
- Generate high-quality videos from text prompts and images
- Configurable video parameters (prompt, resolution, frame count, FPS)
- Support for multiple GPUs with tensor and sequence parallelism
- Advanced configuration options for VAE, Text Encoder, and DIT components
- Interruption/cancellation support for long-running generations
Installation
Requirements
- ComfyUI
- CUDA-capable GPU(s) with sufficient VRAM
Install using ComfyUI Manager
Coming soon!
Manual Installation
Clone this repository into your ComfyUI custom_nodes directory:
cd /path/to/ComfyUI/custom_nodes
git clone https://github.com/kevin314/ComfyUI-FastVideo
Install dependencies:
Currently, the only dependency is fastvideo, which can be installed using pip.
pip install fastvideo
Install missing custom nodes:
ComfyUI-VideoHelperSuite:
cd /path/to/ComfyUI/custom_nodes
git clone https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite.git
If you're seeing ImportError: libGL.so.1: cannot open shared object file: No such file or directory,
you may need to install ffmpeg
apt-get update && apt-get install ffmpeg
Usage
After installation, the following nodes will be available in the ComfyUI interface under the "fastvideo" category:
- Video Generator: The main node for generating videos from prompts
- Inference Args: Configure video generation parameters
- VAE Config
- Text Encoder Config
- DIT Config
- Load Image Path: Load images for potential conditioning
You may have noticed many arguments on the nodes have 'auto' as the default value. This is because FastVideo will automatically detect the best values for these parameters based on the model and the hardware. However, you can also manually configure these parameters to get the best performance for your specific use case. We plan on releasing more optimized workflow files for different models and hardware configurations in the future.
You can see what some of the default configurations are by looking at the FastVideo repo:
Node Configuration
Video Generator
- prompt: Text description of the video to generate
- output_path: Directory where generated videos will be saved
- num_gpus: Number of GPUs to use for generation
- model_path: Path to the FastVideo model
- embedded_cfg_scale: Classifier-free guidance scale
- sp_size: Sequence parallelism size (usually should match num_gpus)
- tp_size: Tensor parallelism size (usually should match num_gpus)
- precision: Model precision (fp16 or bf16)
model_path takes either a model id from huggingface or a local path to a model. Models by default will be downloaded to ~/.cache/huggingface/hub/ and cached for subseqent runs.
Inference Args
- height/width: Resolution of the output video
- num_frames: Number of frames to generate
- num_inference_steps: Number of diffusion steps per frame
- guidance_scale: Classifier-free guidance scale
- flow_shift: Frame flow shift parameter
- seed: Random seed for reproducible generation
- fps: Frames per second of the output video
- image_path: Optional path to input image for conditioning (for i2v models)
Example workflows
Text to Video
FastVideo-FastHunyuan-diffusers
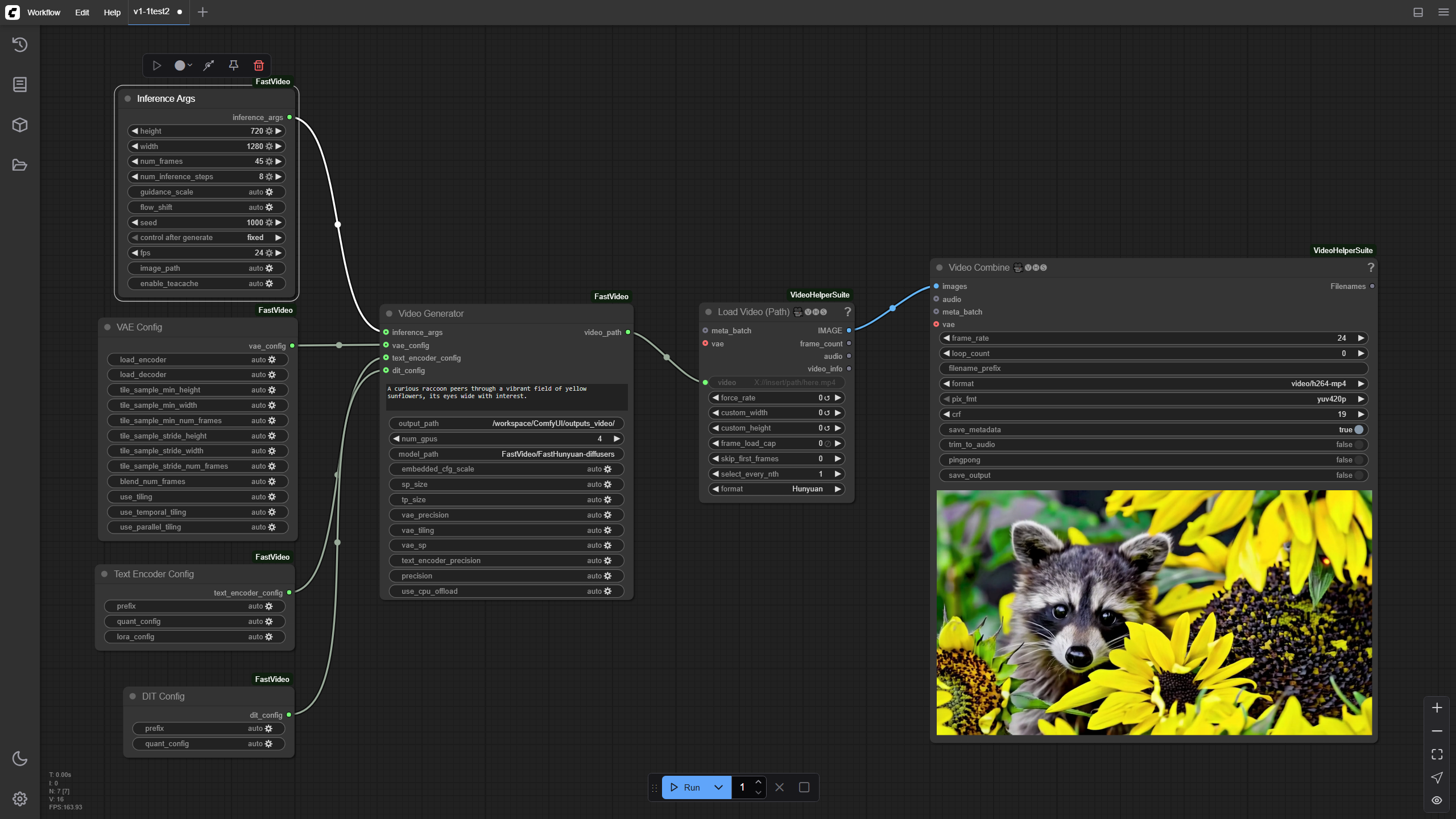
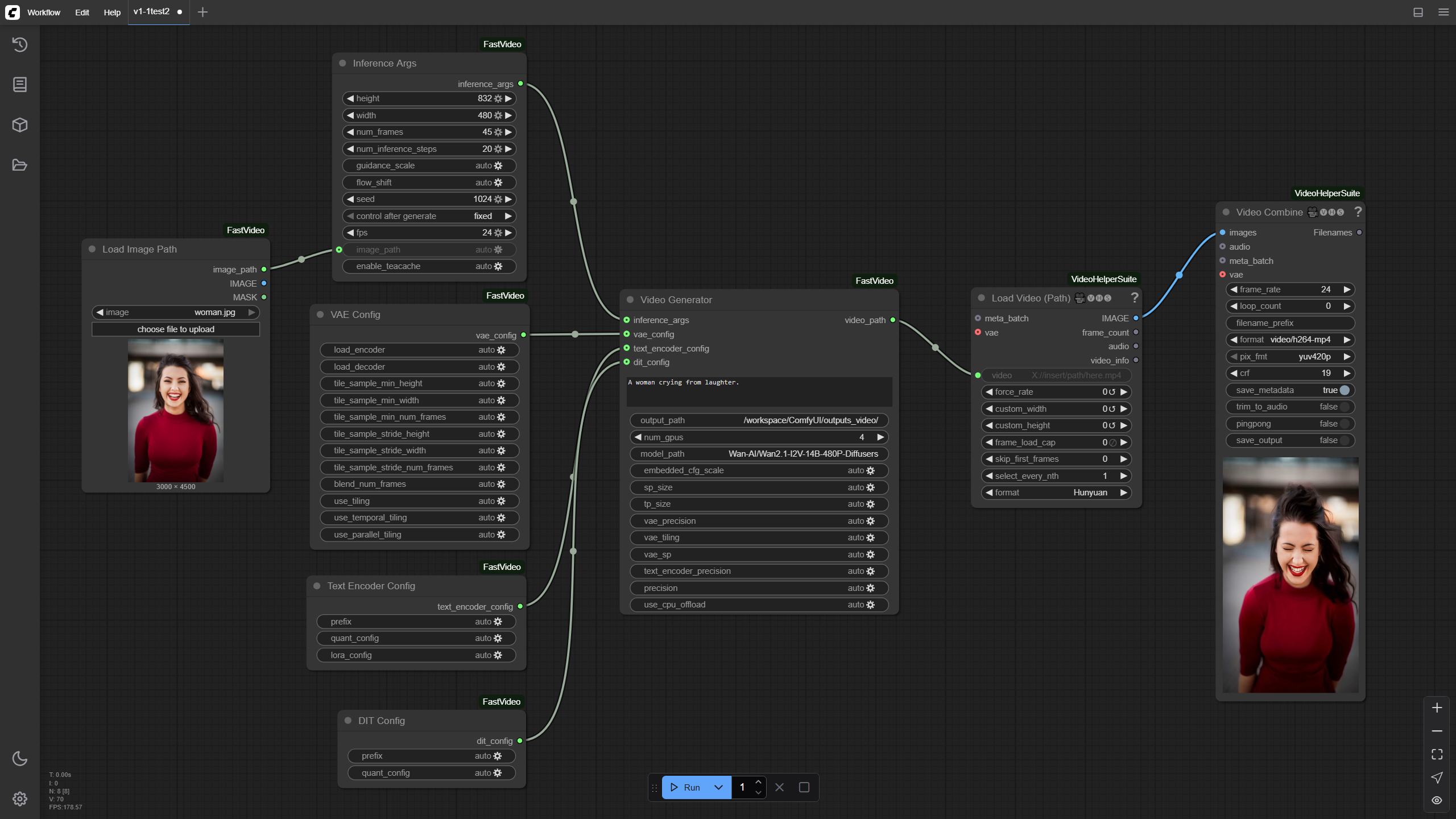
Image to Video
Wan2.1-I2V-14B-480P-Diffusers
License
This project is licensed under Apache 2.0.
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.