ComfyUI Extension: ComfyUI-speech-dataset-toolkit
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
Basic audio tools using torchaudio for ComfyUI. It is assumed to assist in the speech dataset creation for ASR, TTS, etc.
Looking for a different extension?
Custom Nodes (55)
- Audio Property
- Concat Audio
- Cut Audio
- Apply Demucs
- Load Demucs
- faster-whisper List Segments
- Load faster-whisper
- faster-whisper Segment Property
- faster-whisper Text From Segments
- Transcribe by faster-whisper
- GriffinLim
- Join Audio
- kotoba-whisper List Segments
- Load kotoba-whisper
- Load kotoba-whisper (Long-Form)
- Load kotoba-whisper (Short-Form)
- kotoba-whisper Segment Property
- Transcribe by kotoba-whisper
- Transcribe by kotoba-whisper (Long-Form)
- Transcribe by kotoba-whisper (Short-Form)
- LFCC
- Load Audio
- Load Audios
- Make Silence Audio
- MelSpectrogram
- MFCC
- nemo-asr List Segments
- nemo-asr List Subwords
- Load nemo-asr
- nemo-asr Segment Property
- nemo-asr Subword Property
- Transcribe by nemo-asr
- Load nue-asr
- Transcribe by nue-asr
- Play Audio
- Plot MelFilterBank
- Plot Pitch
- Plot Specgram
- Plot Spectrogram
- Plot WaveForm
- Resample Audio
- Save Audio
- Save Audio With Sequential Numbering
- Silence Audio
- Apply Silero VAD
- SileroVAD Collect Chunks
- SileroVAD List Timestamps
- Load Silero VAD
- SileroVAD Timestamp Property
- Spectrogram
- Load SpeechMOS
- SpeechMOS Score
- Split Audio
- Trim Audio
- Trim Audio By Sample
README
ComfyUI-speech-dataset-toolkit
Overview
Basic audio tools using torchaudio for ComfyUI. It is assumed to assist in the speech dataset creation for ASR, TTS, etc.
[!NOTE] The AUDIO type in this repository is compatible with the official implementation. (as of February 7, 2025).
Features
- Basic
- Load & Save audio
- Edit
- Cut and Trim
- Split and Join
- Silence
- Resample
- Visualization
- WaveForm
- Specgram
- Spectrogram
- MelFilterBank
- Pitch
- AI
Requirement
Install torchaudio according to your environment.
cd custom_nodes
git clone https://github.com/kale4eat/ComfyUI-speech-dataset-toolkit.git
cd ComfyUI-speech-dataset-toolkit
pip3 install torchaudio --index-url https://download.pytorch.org/whl/cu121
pip3 install -r requirements.txt
If you use silero-vad, install onnxruntime according to your environment.
pip install onnxruntime-gpu
Usage
At first startup, audio_input and audio_output folder is created.
ComfyUI
├── input
│ └── audio_input
├── output
│ └── audio_input
├── custom_nodes
│ └── ComfyUI-speech-dataset-toolkit
...
Fisrt of all, use a Load Audio node to load audio.
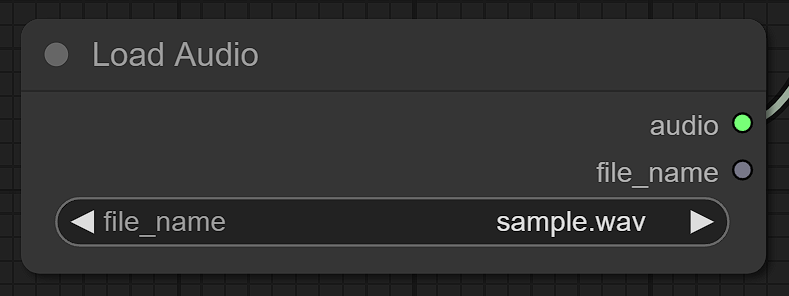
Please put the audio files you wish to process in a audio_input folder in advance.
If you've added files while the app is running, please reload the page (press F5).
You can use LoadAudio, which is official implementation of ComfyUI.
audio, the data type of ComfyUI flow, consists of waveform and sample rate.
Many nodes of this extension handle this data.
Note that waveform is torch.Tensor and has batch dim.
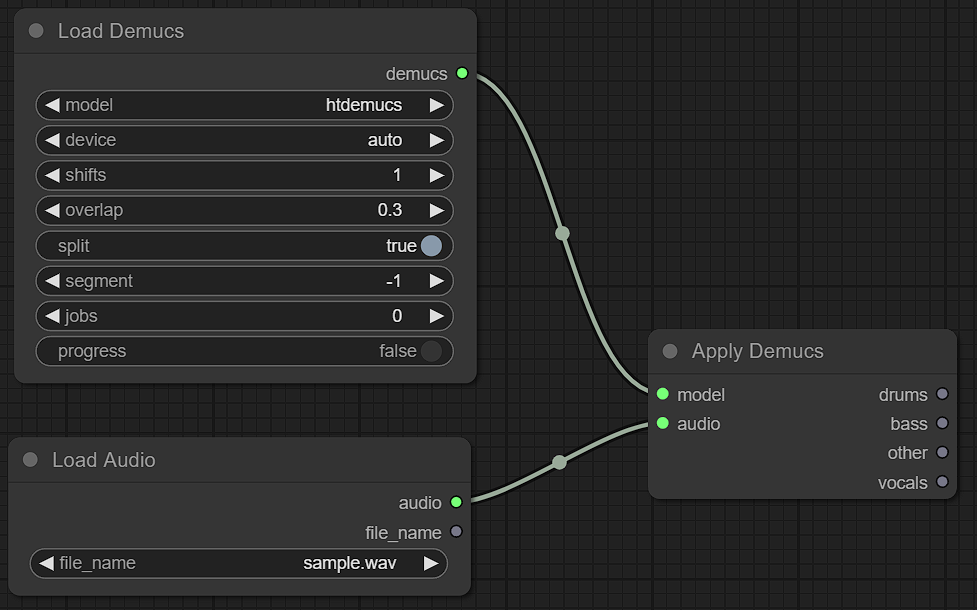
For example, Demucs separate drums, bass, vocals and other stems. Each of them is audio data.
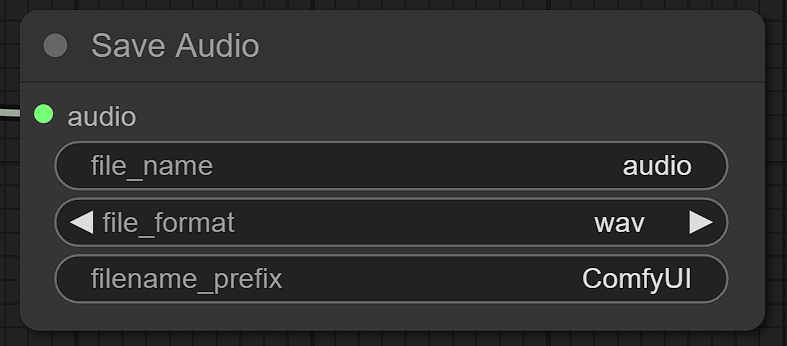
Finally, use a Save Audio node to save audio. The audio is saved to audio_output folder. You can also use SaveAudio implemented by ComfyUI.
Note
There are some unsettled policies, destructive changes may be made.
This repository does not contain the nodes such as numerical operations and string processing.
Inspiration
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.