
ComfyUI Extension: YALLM-LlamaVision
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
A set of nodes for basic Llama 3.2 Vision support in ComfyUI. Give it an image and query and it will output a text response.
Looking for a different extension?
Custom Nodes (3)
README
(Yet Another) Llama Vision Node for ComfyUI
A set of nodes for basic Llama 3.2 Vision support in ComfyUI. Give it an image and query and it will output a text response.
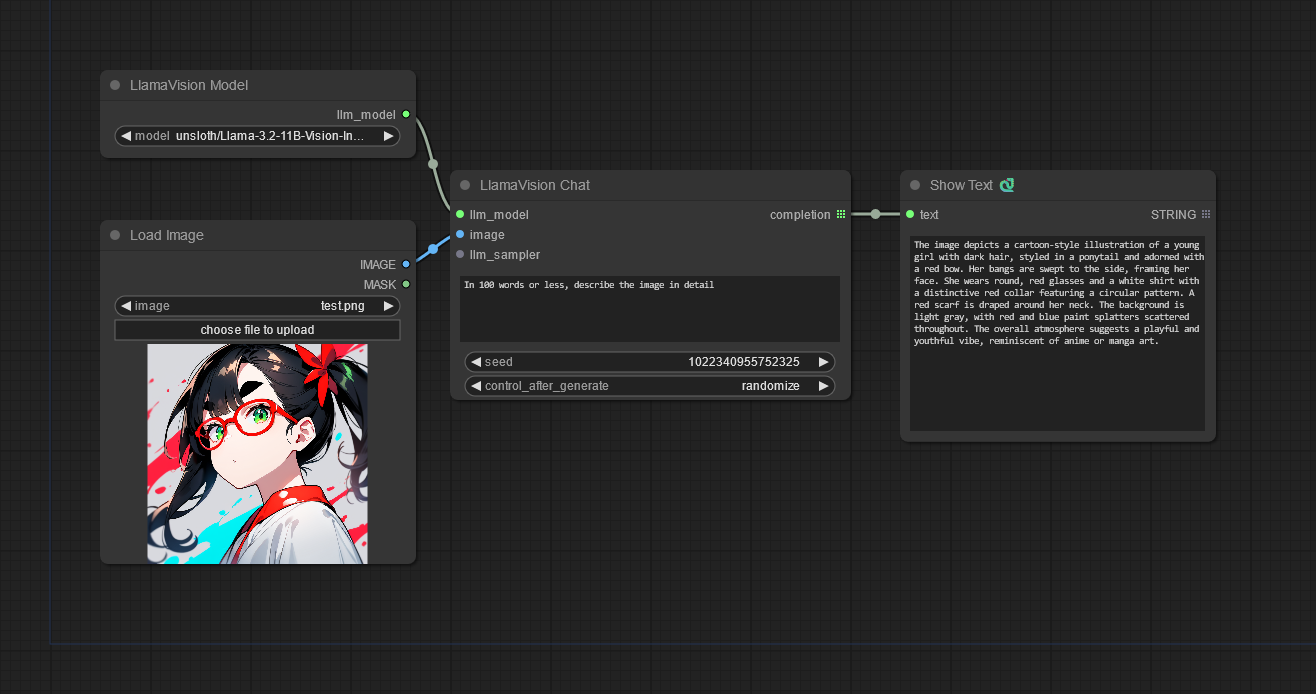
(The "Show Text" node is from https://github.com/pythongosssss/ComfyUI-Custom-Scripts/)
You can adjust the LLM sampler settings with the included "LLM Sampler Settings" node. However, this is completely optional and without it, the model's default settings will be used, which is usually: temperature 0.6, top-p 0.9. (See generation_config.json in the model's repo.)
Installation
Clone into your custom_nodes directory and install the dependencies:
path/to/ComfyUI/pip install -r YALLM-LlamaVision/requirements.txt
This will upgrade your Huggingface transformers module to 4.45 or later, which is needed for Llama 3.2 Vision. It will also install the HF bitsandbytes package for running quantized (e.g. "nf4") models.
Models
Out of the box, it uses the "nf4" quantized model at https://huggingface.co/unsloth/Llama-3.2-11B-Vision-Instruct-bnb-4bit (for best results, you should probably have at least 10GB of VRAM).
Other options are available, including the original unquantized (BF16) version.
See models.yaml.default for details. By default, models are downloaded into the models/LLM directory within ComfyUI. I know some people (including myself) like having them download into their Huggingface cache (~/.cache/huggingface) instead, where they can be easily shared with other projects/notebooks. This can be enabled on a per-model basis.
You can customize the model list by:
cp models.yaml.default models.yaml
and then editing models.yaml to taste.
Also, no, I haven't tested it with 90B!
Quantization
If you select the original model (meta-llama/Llama-3.2-11B-Vision-Instruct), can you also choose to quantize it on-the-fly. However, I don't really recommend this because you'll be loading in a 20GB model every time. If you're going to use "nf4", just use one of the pre-quantized models.
Using "int8" quantization requires around 15 - 15.5GB of VRAM in my experience. But I also don't recommend using "int8" whether pre-quantized or quantized on-the-fly since, unlike "nf4" quantization, the model cannot be offloaded after usage. So you'll need a lot more than 16GB (like in the 24GB range) if you want to do more with your workflow. This is a limitation of transformers & bitsandbytes, and if there's a way around it, I haven't learned it yet. 😜
My Related Projects
- https://github.com/asaddi/ComfyUI-YALLM-node LLM ComfyUI nodes for local & remote LLMs served via OpenAI-like API. Multimodal support too, so you can talk to local or remote instances of vision LLMs.
- https://github.com/asaddi/lv-serve Simple OpenAI-like API server for Llama 3.2 Vision. Pretty similar to this project, but hosts the model outside of ComfyUI. Combine with ComfyUI-YALLM-node and your workflow is then free to swap between local & remote APIs very easily.
License
Licensed under BSD-2-Clause-Patent.
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.