ComfyUI Extension: prompt-generator
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
Custom AI prompt generator node for ComfyUI.
README
prompt-generator-comfyui
Custom AI prompt generator node for ComfyUI. With this node, you can use text generation models to generate prompts. Before using, text generation model has to be trained with prompt dataset or you can use the pretrained models.
Table Of Contents
- prompt-generator-comfyui
- Table Of Contents
- Setup
- Features
- Example Workflow
- Pretrained Prompt Models
- Variables
- Troubleshooting
- Contributing
- Example Outputs
Setup
For Portable Installation of the ComfyUI
- Clone the repository with
git clone https://github.com/alpertunga-bile/prompt-generator-comfyui.gitcommand undercustom_nodesfolder - Go to the
ComfyUI_windows_portablefolder and install the required packages with.\python_embeded\Scripts\python.exe -s -m pip install -r .\ComfyUI\custom_nodes\prompt-generator-comfyui\requirements.txtcommand - Put your generator under the
models/prompt_generatorsfolder. You have to put generator as folder. Do not just putpytorch_model.binfile for example. - Go to the
ComfyUI_windows_portablefolder and run the run_nvidia_gpu.bat file - Open the
hires.fixWithPromptGenerator.jsonorbasicWorkflowWithPromptGenerator.jsonworkflow
For Manual Installation of the ComfyUI
- Clone the repository with
git clone https://github.com/alpertunga-bile/prompt-generator-comfyui.gitcommand undercustom_nodesfolder. - Activate the virtual environment if there is one and install the required
packages with
pip install -r requirements.txtcommand - Put your generator under the
models/prompt_generatorsfolder. You have to put generator as folder. Do not just putpytorch_model.binfile for example. - Open the
hires.fixWithPromptGenerator.jsonorbasicWorkflowWithPromptGenerator.jsonworkflow
For ComfyUI Manager Users
- Download the node with
ComfyUI Manager
- [x] The required packages are installed automatically when installing the node.
- Put your generator under the
models/prompt_generatorsfolder. You have to put generator as folder. Do not just putpytorch_model.binfile for example. - Open the
hires.fixWithPromptGenerator.jsonorbasicWorkflowWithPromptGenerator.jsonworkflow
Features
- Multiple output generation is added. You can choose from 5 outputs with the index value. You can check the generated prompts from the log file and terminal. The prompts are logged and printed in order.
- Randomness is added. See this section.
- Quantization is added with Quanto and Bitsandbytes packages. See this section.
- Lora adapter model loading is added with Peft package. (The feature is not full tested in this repository because of my low VRAM but I am using the same implementation in Google Colab for training and inference and it is working there)
- Optimizations are done with Optimum package.
- ONNX and transformers models are supported.
- Preprocessing outputs. See this section.
- Recursive generation is supported. See this section.
- Print generated text to terminal and log the node's state under the
generated_promptsfolder with current date as filename.
Example Workflow
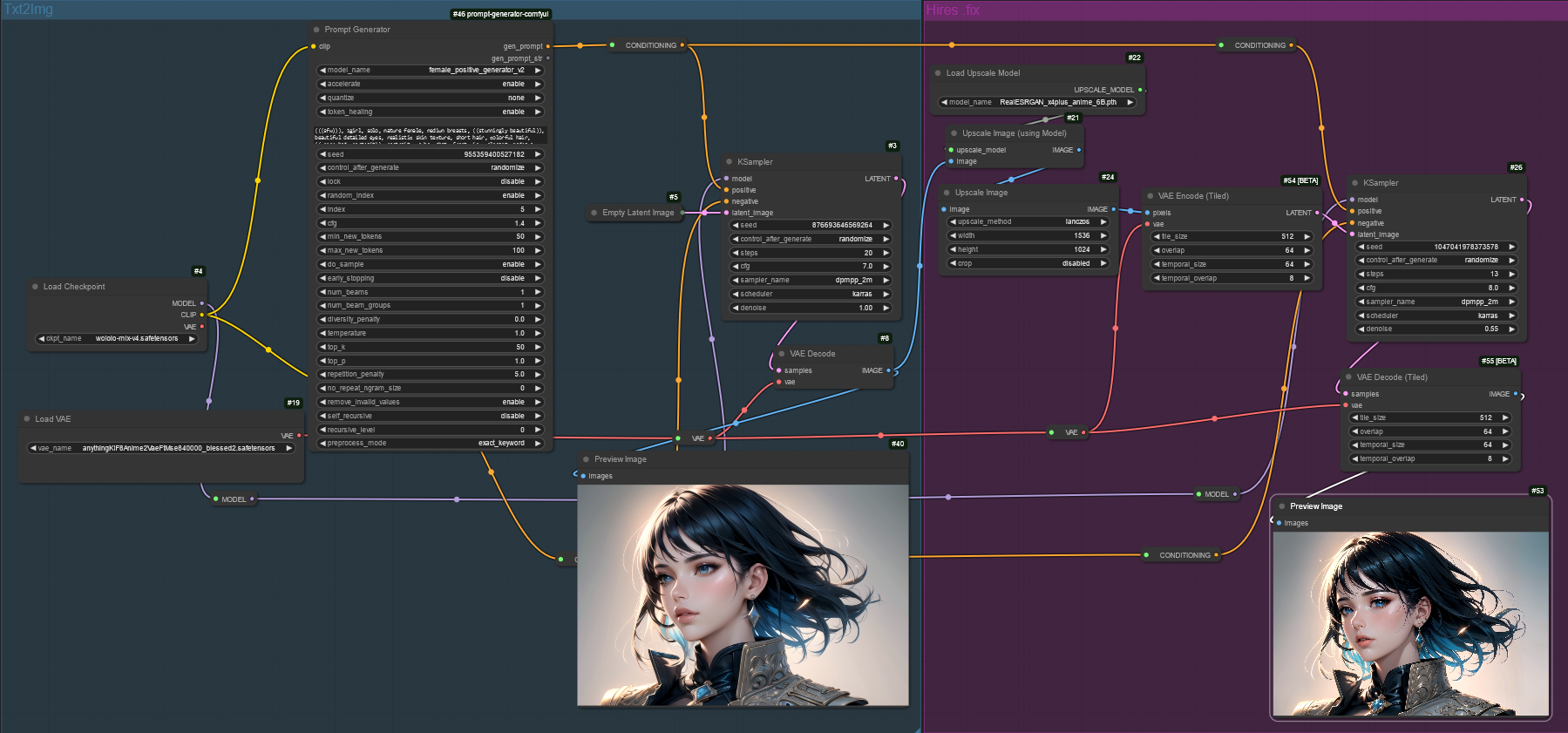
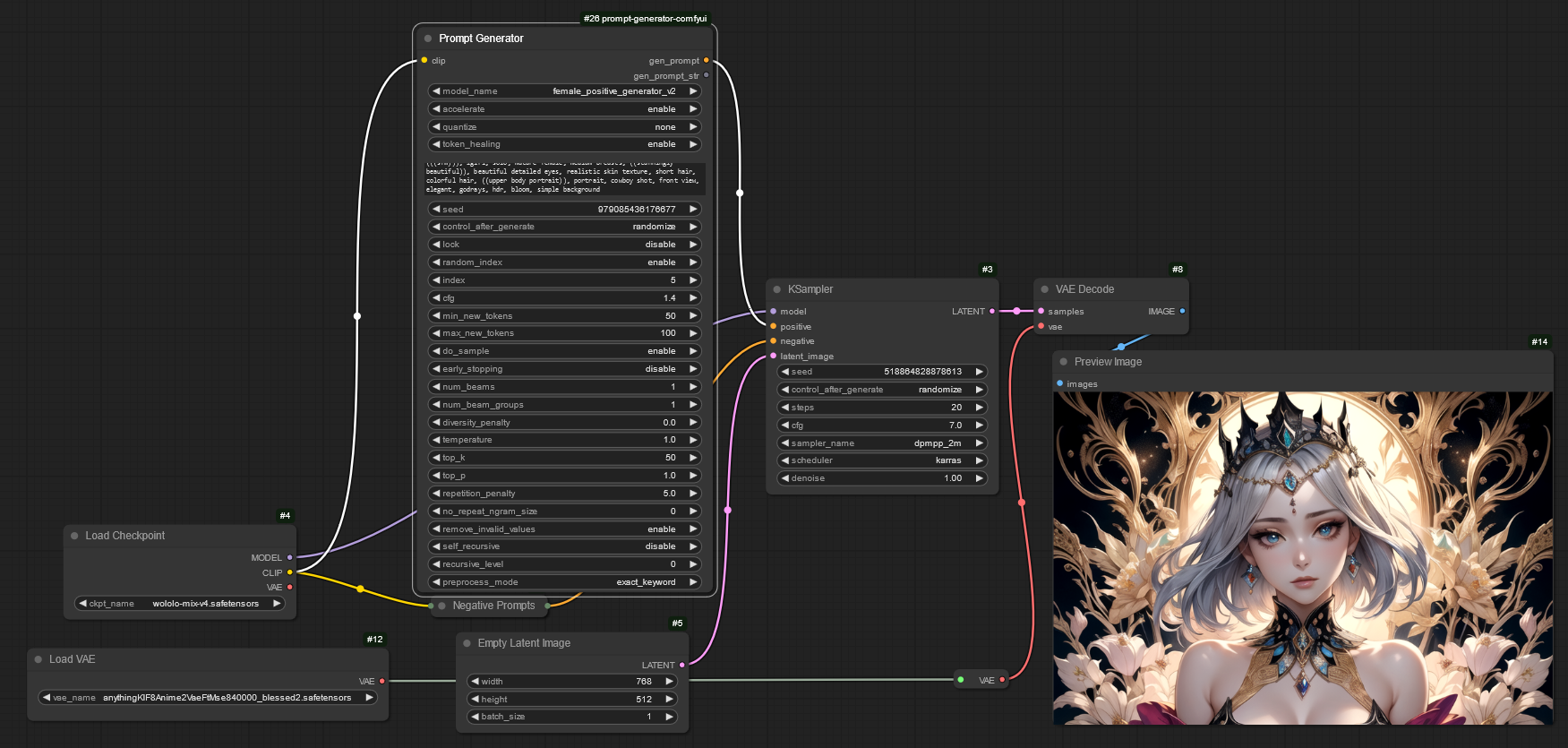
- Prompt Generator Node may look different with final version but workflow in ComfyUI is not going to change
Pretrained Prompt Models
-
You can find the models in this link
-
For to use the pretrained model follow these steps:
- Download the model and unzip to
models/prompt_generatorsfolder. - Refresh or restart the ComfyUI
- Then select the generator with the node's
model_namevariable (If you can't see the generator, restart the ComfyUI).
- Download the model and unzip to
Dataset
- Huggingface Dataset
- Process of data cleaning and gathering can be found here
Models
-
The model versions are used to differentiate models rather than showing which one is better.
-
The v2 version is the latest trained model and the v4 and v5 models are experimental models.
-
female_positive_generator_v2 | (Training In Process)
- Base model
- using distilgpt2 model
- ~500 MB
-
female_positive_generator_v3 | (Training In Process)
- Base model
- using bigscience/bloom-560m model
- ~1.3 GB
-
female_positive_generator_v4 | Experimental
- Lora adapter model
- using senseable/WestLake-7B-v2 model as the base model
- Base model is ~14 GB
Variables
| Variable Names | Definitions |
| :-----------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| model_name | Folder name that contains the model |
| accelerate | Open optimizations. Some of the models are not supported by BetterTransformer (Check your model). If it is not supported switch this option to disable or convert your model to ONNX |
| quantize | Quantize the model. The quantize type is changed based on your OS and torch version. none value disables the quantization. Check this section for more information |
| token_healing | Enable token healing algorithm which is used for fixing unintended bias. Read more from this blog post. To use it, the transformers package version has to be newer from or equal to 4.6 version |
| prompt | Input prompt for the generator |
| seed | Seed value for the model |
| lock | Lock the generation and select from the last generated prompts with index value |
| random_index | Random index value in [1, 5]. If the value is enable, the index value is not used |
| index | User specified index value for selecting prompt from the generated prompts. random_index variable must be disable |
| cfg | CFG is enabled by setting guidance_scale > 1. Higher guidance scale encourages the model to generate samples that are more closely linked to the input prompt, usually at the expense of poorer quality |
| min_new_tokens | The minimum numbers of tokens to generate, ignoring the number of tokens in the prompt. |
| max_new_tokens | The maximum numbers of tokens to generate, ignoring the number of tokens in the prompt. |
| do_sample | Whether or not to use sampling; use greedy decoding otherwise |
| early_stopping | Controls the stopping condition for beam-based methods, like beam-search |
| num_beams | Number of steps for each search path |
| num_beam_groups | Number of groups to divide num_beams into in order to ensure diversity among different groups of beams |
| diversity_penalty | This value is subtracted from a beam’s score if it generates a token same as any beam from other group at a particular time. Note that diversity_penalty is only effective if group beam search is enabled. |
| temperature | How sensitive the algorithm is to selecting low probability options |
| top_k | The number of highest probability vocabulary tokens to keep for top-k-filtering |
| top_p | If set to float < 1, only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation |
| repetition_penalty | The parameter for repetition penalty. 1.0 means no penalty |
| no_repeat_ngram_size | The size of an n-gram that cannot occur more than once. (0=infinity) |
| remove_invalid_values | Whether to remove possible nan and inf outputs of the model to prevent the generation method to crash. Note that using remove_invalid_values can slow down generation. |
| self_recursive | See this section |
| recursive_level | See this section |
| preprocess_mode | See this section |
Quantization
- Quantization is added with Quanto and Bitsandbytes packages.
- The Quanto package requires
torch >= 2.4and Bitsandbytes package works out-of-box with Linux OS. So the node is checking which package to use:- If requirements are not specified for this packages, you can not use the
quantizevariable and it has onlynonevalue. - If the Quanto requirements are filled then you can choose between
none, int8, float8, int4values. - If the Bitsandbytes requirements are filled then you can choose between
none, int8, int4values.
- If requirements are not specified for this packages, you can not use the
- If your environment can use the Quanto and Bitsandbytes packages, the node selects the Bitsandbytes package.
Random Generation
-
For random generation:
- Enable do_sample
-
You can find this text generation strategy from the this link. The strategy is called Multinomial sampling.
-
Changing variable of do_sample to disable gives deterministic generation.
-
For more randomness, you can:
- Set num_beams to 1
- Enable random_index variable
- Increase recursive_level
- Enable self_recursive
Lock The Generation
- Enabling the lock variable skip the generation and let you choose from the last generated prompts.
- You can choose from the index value or use the random_index.
- If random_index is enabled, the index value is ignored.
How Recursive Works?
- Let's say we give
a,as seed and recursive level is 1. I am going to use the same outputs for this example to explain the functionality more understandable. - With self recursive, let's say generator's output is
b. So next seed is going to beband generator's output isc. Final output isa, c. It can be used for generating random outputs. - Without self recursive, let's say generator's output is
b. So next seed is going to bea, band generator's output isc. Final output isa, b, c. It can be used for more accurate prompts.
How Preprocess Mode Works?
- exact_keyword =>
(masterpiece), ((masterpiece))is not allowed. Checking the pure keyword without parantheses and weights. The algorithm is adding the prompts from the beginning of the generated text, so add important prompts to prompt variable. - exact_prompt =>
(masterpiece), ((masterpiece))is allowed but(masterpiece), (masterpiece)is not. Checking the exact match of the prompt. - none => Everything is allowed even the repeated prompts.
Example
# ---------------------------------------------------------------------- Original ---------------------------------------------------------------------- #
((masterpiece)), ((masterpiece:1.2)), (masterpiece), blahblah, blah, blah, ((blahblah)), (((((blah))))), ((same prompt)), same prompt, (masterpiece)
# ------------------------------------------------------------- Preprocess (Exact Keyword) ------------------------------------------------------------- #
((masterpiece)), blahblah, blah, ((same prompt))
# ------------------------------------------------------------- Preprocess (Exact Prompt) -------------------------------------------------------------- #
((masterpiece)), ((masterpiece:1.2)), (masterpiece), blahblah, blah, ((blahblah)), (((((blah))))), ((same prompt)), same prompt
Troubleshooting
- If the below solutions are not fixed your issue please create an issue with
buglabel
Package Version
- The node is based on transformers and optimum packages. So most of the problems may be caused from these packages. For overcome these problems you can try to update these packages:
For Manual Installation of the ComfyUI
- Activate the virtual environment if there is one.
- Run the
pip install --upgrade -r requirements.txtcommand.
For Portable Installation of the ComfyUI
- Go to the
ComfyUI_windows_portablefolder. - Open the command prompt in this folder.
- Run the
.\python_embeded\Scripts\python.exe -s -m pip install --upgrade -r .\ComfyUI\custom_nodes\prompt-generator-comfyui\requirements.txtcommand.
New Updates On The Node
- Sometimes the variables are changed with updates, so it may broke the workflow. But don't worry, you have to just delete the node in the workflow and add it again.
Quantize Values Are Not Updated
- The provided workflows are saved with Quanto configuration.
- To update the
quantizevalues for your environment, delete the node and add it again in your workflow.
Contributing
-
Contributions are welcome. If you have an idea and want to implement it by yourself please follow these steps:
- Create a fork
- Pull request the fork with the description that explaining the new feature
-
If you have an idea but don't know how to implement it, please create an issue with
enhancementlabel. -
[x] The contributing can be done in several ways. You can contribute to code or to README file.
Example Outputs



Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.