
ComfyUI Extension: ComfyUI-InferenceTimeScaling
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
Inference-time techniques to enhance diffusion-based image generation quality through random search and zero-order optimization algorithms
Looking for a different extension?
Custom Nodes (4)
README
ComfyUI-InferenceTimeScaling
![]()
A ComfyUI extension implementing "Inference-time scaling for diffusion models beyond scaling denoising steps" (Ma et al., 2025). This extension provides inference-time optimization techniques to enhance diffusion-based image generation quality through random search and zero-order optimization algorithms, along with an ensemble verification system.

Prompt: "Photo of an athlete cat explaining it's latest scandal at a press conference to journalists."
Features
- Implementation of two search algorithms from the paper:
- Random search optimization
- Zero-order optimization
- Ensemble verification system using three verifiers:
- CLIP Score verification
- ImageReward verification
- VLM grading using Qwen2.5-VL-7B
- Automated model downloading and management
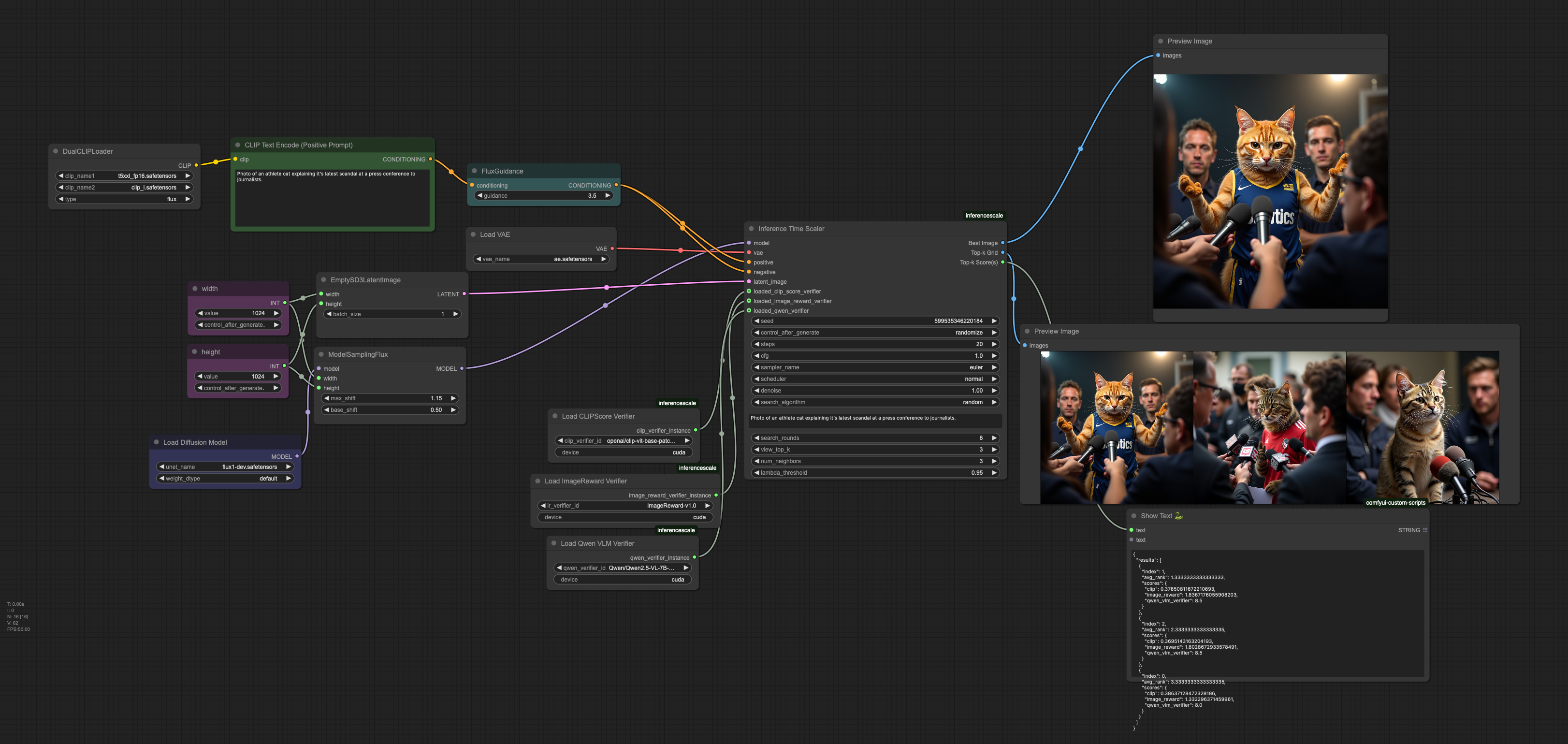
Simple example using FLUX-1 Dev with random search for 6 rounds
How It Works
This extension implements two different search algorithms to find the best possible image for your prompt:
-
Random Search: The simplest approach - generates multiple images with different random noises and evaluates them to explore the noise space.
-
Zero-Order Search: A more sophisticated approach that performs local optimization. It starts with a random noise, generates nearby variations by perturbing noise, and iteratively moves toward better results based on evaluation.
To explore the noise space, the quality of generated images is evaluated using an ensemble of three verifiers:
- CLIP Score: Measures how well the image matches the text prompt using OpenAI's CLIP model
- ImageReward: Evaluates image quality and prompt alignment using a specialized reward model
- Qwen VLM: Uses a large vision-language model to provide detailed scoring across multiple aspects (visual quality, creativity, prompt accuracy, etc.)
By exploring the noise space and using these verifiers to guide the search, it can produce images of higher quality and better prompt alignment than simply increasing denoising steps, with the tradeoff being increased time and compute during inference.
For more detailed information about the algorithms and methodology, please refer to the original paper from Google DeepMind: "Inference-time scaling for diffusion models beyond scaling denoising steps".
Installation
Prerequisites
- Install ComfyUI
- Install ComfyUI-Manager
Hardware Requirements
This was developed and tested on a system with:
- Single NVIDIA L40S GPU (48GB VRAM)
- 62GB System RAM
Installation Methods
Using ComfyUI-Manager (Recommended)
- Open ComfyUI
- Open the Manager panel
- Search for "ComfyUI-InferenceTimeScaling"
- Click "Install"
- Restart ComfyUI
Manual Installation
cd ComfyUI/custom_nodes
git clone https://github.com/YRIKKA/ComfyUI-InferenceTimeScaling
cd ComfyUI-InferenceTimeScaling
pip install -e .
Usage
The extension adds the following nodes to ComfyUI:
InferenceTimeScaler Node
This is the main node implementing the random search and zero-order optimization algorithms from the paper.
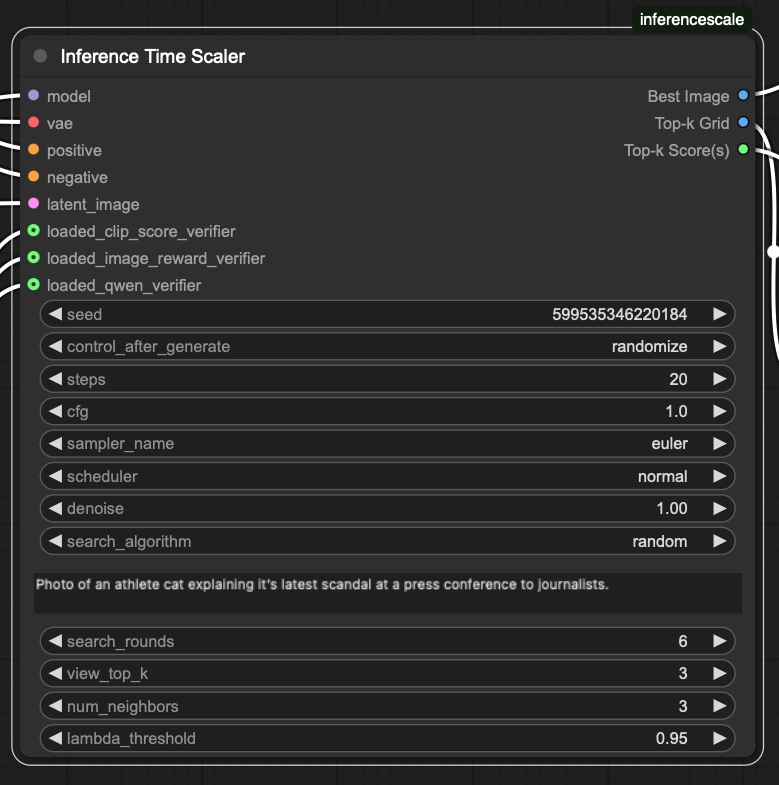
Inputs:
model: (MODEL) Denoising modelseed: (INT) Random seed for reproducibilitysteps: (INT) Number of denoising stepscfg: (FLOAT) Classifier-Free Guidance scalesampler_name: (SAMPLER) Sampling algorithmscheduler: (SCHEDULER) Noise schedulerpositive: (CONDITIONING) Positive prompt conditioningnegative: (CONDITIONING) Negative prompt conditioninglatent_image: (LATENT) Input latent imagedenoise: (FLOAT) Amount of denoising to applytext_prompt_to_compare: (STRING) Text prompt for verifierssearch_rounds: (INT) Number of search rounds (random seeds for random search, or iterations for zero-order search)vae: (VAE) VAE model for decoding latentsview_top_k: (INT) Number of top images to show in gridsearch_algorithm: Choice between "random" and "zero-order"
[!IMPORTANT] The following parameters are only used for zero-order search and have no effect when using random search:
num_neighbors: (INT) Number of neighbors per iteration in zero-order searchlambda_threshold: (FLOAT) Perturbation step size for zero-order search
Optional Inputs:
loaded_clip_score_verifier: (CS_VERIFIER) CLIP model for scoringloaded_image_reward_verifier: (IR_VERIFIER) ImageReward modelloaded_qwen_verifier: (QWN_VERIFIER) Qwen VLM model
[!NOTE] The verifiers are optional - you can choose which ones to use by connecting them to the node. However, at least one verifier must be connected for the node to function!
Outputs:
Best Image: The highest-scoring generated imageTop-k Grid: Grid view of the top-k scoring imagesTop-k Score(s): JSON string containing detailed scores
LoadQwenVLMVerifier Node
Loads the Qwen VLM verifier model for image evaluation.
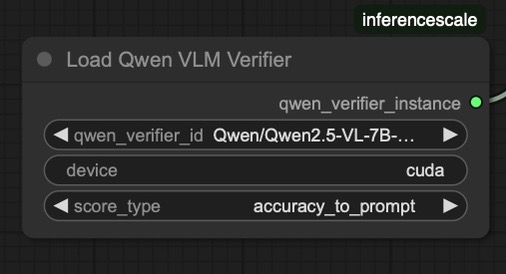
Inputs:
qwen_verifier_id: Model identifier (default: "Qwen/Qwen2.5-VL-7B-Instruct")device: Device to load model on ("cuda" or "cpu")score_type: Type of score to return from the evaluation (default: "overall_score"). Options:overall_score: Weighted average of all aspectsaccuracy_to_prompt: How well the image matches the text descriptioncreativity_and_originality: Uniqueness and creative interpretationvisual_quality_and_realism: Overall visual quality, detail, and realismconsistency_and_cohesion: Internal consistency and natural compositionemotional_or_thematic_resonance: How well the image captures the intended mood/theme
Outputs:
qwen_verifier_instance: Loaded Qwen verifier instance
The model will be downloaded automatically on first use (you do not need to have these weights locally beforehand).
LoadCLIPScoreVerifier Node
Loads the CLIP model for computing text-image similarity scores.
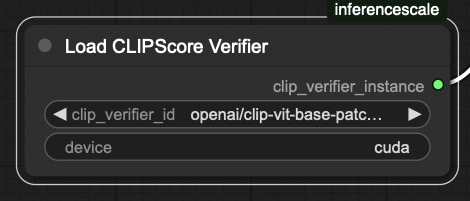
Inputs:
clip_verifier_id: Model identifier (default: "openai/clip-vit-base-patch32")device: Device to load model on ("cuda" or "cpu")
Outputs:
clip_verifier_instance: Loaded CLIP verifier instance
The model will be downloaded automatically on first use (you do not need to have these weights locally beforehand).
LoadImageRewardVerifier Node
Loads the ImageReward model for image quality assessment.
Inputs:
ir_verifier_id: Model identifier (default: "ImageReward-v1.0")device: Device to load model on ("cuda" or "cpu")
Outputs:
image_reward_verifier_instance: Loaded ImageReward verifier instance
The model will be downloaded automatically on first use (you do not need to have these weights locally beforehand).
Example Workflow
- Load your model using the standard ComfyUI checkpoint loader
- Load the verifier models using their respective loader nodes
- Connect everything to the InferenceTimeScaler node
- Set your desired search algorithm and parameters
- Generate optimized images with improved quality
Current Limitations
- Single latent processing only (batch size = 1) - performance limitation
- Sequential verification (one image-text pair at a time) - speed bottleneck
Future Work
- [x] Enable configurable scoring criteria for Qwen VLM verifier
- Allow users to select specific aspects like visual quality, creativity, etc.
- Support individual aspect scoring
- [ ] Add batch processing support for image generation (performance optimization)
- [ ] Implement batched verification for multiple image-text pairs (speed optimization)
- [ ] Add support for image-to-image and image+text conditioning to image models (currently only supports text-to-image models)
License
Acknowledgments
- Thanks to the authors of the original paper for their research
- ComfyUI team for the excellent framework
- tt-scale-flux repository for the
generate_neighborsfunction - Qwen team for their powerful VLM model
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.