ComfyUI Extension: SeargeSDXL
SeargeSDXL is ready to run
It's one of 95 extensions already installed on ComfyICU — nothing to clone, nothing to reconcile. Bring a workflow and you're billed for GPU seconds, not idle time.
Custom nodes for easier use of SDXL in ComfyUI including an img2img workflow that utilizes both the base and refiner checkpoints.
Looking for a different extension?
Custom Nodes (72)
- Advanced Parameters v2
- Checkpoint Loader (Searge)
- 2-Way Muxer for Conditioning
- 5-Way Muxer for Conditioning
- Conditioning Parameters v2
- Condition Mixing v2
- Controlnet Adapter v2
- Controlnet Models Selector v2
- After Upscaling
- After VAE Decode
- Custom Prompt Mode v2
- Debug Printer
- Enable / Disable
- Float Constant
- Float Math
- Float Pair
- FreeU v2
- Flow Control Parameters
- Generation Parameters v2
- High Resolution v2
- Image to Image and Inpainting v2
- Image Adapter v2
- Save Image (Searge)
- Image Saving v2
- Prompts
- Generation Parameters
- Advanced Parameters
- Model Names
- Prompt Processing
- HiResFix Parameters
- Misc Parameters
- Integer Constant
- Integer Math
- Integer Pair
- Integer Scaler
- 3-Way Muxer for Latents
- Lora Loader (Searge)
- Lora Selector v2
- Searge's Magic Box for SDXL
- Model Selector v2
- Operating Mode v2
- Prompts
- Generation Parameters
- Advanced Parameters
- Model Names
- Prompt Processing
- HiResFix Parameters
- Misc Parameters
- Parameter Processor
- Magic Box Pipeline Start
- Magic Box Pipeline Terminator
- SeargePreviewImage
- Prompt Adapter v2
- Prompt combiner
- Prompt Styles v2
- Prompt text input
- Sampler Settings
- Save Folder
- SDXL Base Prompt Encoder (Searge)
- Image2Image Sampler v1 (Searge)
- Image2Image Sampler v2 (Searge)
- SDXL Prompt Encoder (Searge)
- SDXL Refiner Prompt Encoder (Searge)
- SDXL Sampler v1 (Searge)
- SDXL Sampler v2 (Searge)
- SDXL Sampler v3 (Searge)
- Separator
- Style Preprocessor (wip)
- Text Input v2
- Upscale Model Loader (Searge)
- Upscale Models Selector v2
- VAE Loader (Searge)
README
Searge-SDXL: EVOLVED v4.x for ComfyUI
Custom nodes extension for ComfyUI, including a workflow to use SDXL 1.0 with both the base and refiner checkpoints.
Table of Content
<!-- TOC -->- Searge-SDXL: EVOLVED v4.x for ComfyUI
- Table of Content
- Version 4.3
- Installing and Updating
- Updates
- The Workflow File
- Workflow Details
- More Example Images
Version 4.3
Instead of having separate workflows for different tasks, everything is integrated in one workflow file.
Always use the latest version of the workflow json file with the latest version of the custom nodes!
<img src="docs/img/main_readme/banner.png" width="768">Installing and Updating
New and Recommended Installation (Windows)
- For this to work properly, it needs to be used with the portable version of ComfyUI for Windows, read more about it in the ComfyUI readme file
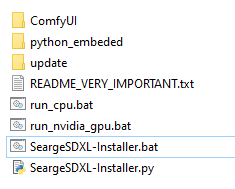
- Download this new install script
and unpack it into the
ComfyUI_windows_portabledirectory - You should now have
SeargeSDXL-Installer.batandSeargeSDXL-Installer.pyin the same directory as the ComfyUIrun_cpu.batandrun_nvidia_gpu.bat - To verify that you are using the portable version, check if the directory
python_embededalso exists in the same directory that you unpacked these install scripts to - Run the
SeargeSDXL-Installer.batscript and follow the instructions on screen
Manual Installation
- If you are not using the install script, you have to run the command
python -m pip install opencv-pythonin the python environment for ComfyUI at least once, to install a required dependency - Navigate to your
ComfyUI/custom_nodes/directory - Open a command line window in the custom_nodes directory
- Run
git clone https://github.com/SeargeDP/SeargeSDXL.git - Restart ComfyUI
Alternative Installation (not recommended)
- Download and unpack the latest release from the Searge SDXL CivitAI page
- Drop the
SeargeSDXLfolder into theComfyUI/custom_nodesdirectory and restart ComfyUI.
Updating an Existing Installation
- Navigate to your
ComfyUI/custom_nodes/directory - If you installed via
git clonebefore- Open a command line window in the custom_nodes directory
- Run
git pull
- If you installed from a zip file
- Unpack the
SeargeSDXLfolder from the latest release intoComfyUI/custom_nodes, overwrite existing files
- Unpack the
- Restart ComfyUI
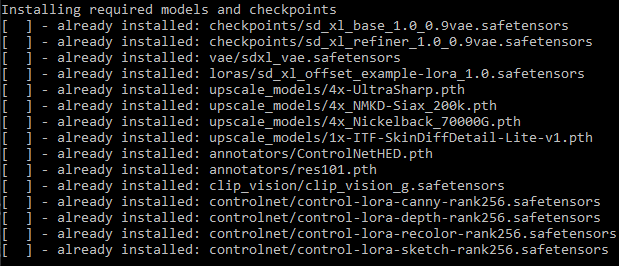
Checkpoints and Models for these Workflows
These can now also be installed with the new install script (on Windows) instead of manually downloading them.
Description
This workflow depends on certain checkpoint files to be installed in ComfyUI, here is a list of the necessary files that the workflow expects to be available.
If any of the mentioned folders does not exist in ComfyUI/models, create the missing folder and put the
downloaded file into it.
I recommend to download and copy all these files (the required, recommended, and optional ones) to make full use of all features included in the workflow!
Direct Downloads
(from Huggingface)
-
(required) download SDXL 1.0 Base with 0.9 VAE (7 GB) and copy it into
ComfyUI/models/checkpoints- (this should be pre-selected as the base model on the workflow already)
-
(recommended) download SDXL 1.0 Refiner with 0.9 VAE (6 GB) and copy it into
ComfyUI/models/checkpoints- (you should select this as the refiner model on the workflow)
-
(optional) download Fixed SDXL 0.9 vae (335 MB) and copy it into
ComfyUI/models/vae- (instead of using the VAE that's embedded in SDXL 1.0, this one has been fixed to work in fp16 and should fix the issue with generating black images)
-
(optional) download SDXL Offset Noise LoRA (50 MB) and copy it into
ComfyUI/models/loras- (the example lora that was released alongside SDXL 1.0, it can add more contrast through offset-noise)
-
(recommended) download 4x-UltraSharp (67 MB) and copy it into
ComfyUI/models/upscale_models- (you should select this as the primary upscaler on the workflow)
-
(recommended) download 4x_NMKD-Siax_200k (67 MB) and copy it into
ComfyUI/models/upscale_models- (you should select this as the secondary upscaler on the workflow)
-
(recommended) download 4x_Nickelback_70000G (67 MB) and copy it into
ComfyUI/models/upscale_models- (you should select this as the high-res upscaler on the workflow)
-
(optional) download 1x-ITF-SkinDiffDetail-Lite-v1 (20 MB) and copy it into
ComfyUI/models/upscale_models- (you can select this as the detail processor on the workflow)
-
(required) download ControlNetHED (30 MB) and copy it into
ComfyUI/models/annotators- (this will be used by the controlnet nodes)
-
(required) download res101 (531 MB) and copy it into
ComfyUI/models/annotators- (this will be used by the controlnet nodes)
-
(recommended) download clip_vision_g (3.7 GB) and copy it into
ComfyUI/models/clip_vision- (you should select this as the clip vision model on the workflow)
-
(recommended) download control-lora-canny-rank256 (774 MB) and copy it into
ComfyUI/models/controlnet- (you should select this as the canny checkpoint on the workflow)
-
(recommended) download control-lora-depth-rank256 (774 MB) and copy it into
ComfyUI/models/controlnet- (you should select this as the depth checkpoint on the workflow)
-
(recommended) download control-lora-recolor-rank256 (774 MB) and copy it into
ComfyUI/models/controlnet- (you should select this as the recolor checkpoint on the workflow)
-
(recommended) download control-lora-sketch-rank256 (774 MB) and copy it into
ComfyUI/models/controlnet- (you should select this as the sketch checkpoint on the workflow)
Now everything should be prepared, but you may to have to adjust some file names in the different model selector boxes on the workflow. Do so by clicking on the filename in the workflow UI and selecting the correct file from the list.
<img src="docs/img/main_readme/full_graph.png" width="768">Updates
Find information about the latest changes here.
What's new in v4.3.2?
This is a minor update to make the workflow and custom node extension compatible with the latest changes in ComfyUI.
What's new in v4.3.1?
This is a minor update to make the workflow and custom node extension compatible with the latest changes in ComfyUI.
What's new in v4.3?
This update added support for FreeU v2 in addition to FreeU v1.
New Features
- Support for FreeU v2 has been added and is included in the v4.3 workflow
- Added more presets for FreeU and a selector to switch between v1 and v2
- Updated the example images to embed the v4.3 workflow
What's new in v4.2?
This update contains bug fixes that address issues found after v4.0 was released.
Bug Fixes
- A recent change in ComfyUI conflicted with my implementation of inpainting, this is now fixed and inpainting should work again
New Features
- Support for FreeU has been added and is included in the v4.2 workflow
- Note: the images in the example folder are still embedding v4.1 of the workflow, to use FreeU load the new
workflow from the
.jsonfile in theworkflowfolder
What's new in v4.1?
This update contains bug fixes that address issues found after v4.0 was released.
Bug Fixes
- The high resolution latent detailer was not properly set up in the processing pipeline and did nothing
- The debug printer node was broken - I didn't notice that because it was not connected in any of the v4.0 workflows
- A bug related to generating with batch sizes larger than 1 has been fixed, it's now working properly
Other Changes
- The images in the
examplesfolder have been updated to embed the v4.1 workflow
What's new in v4.0?
This is the first release with the v4.x architecture of the custom node extension.
Major Highlights
- A complete re-write of the custom node extension and the SDXL workflow
- Highly optimized processing pipeline, now up to 20% faster than in older workflow versions
- Support for Controlnet and Revision, up to 5 can be applied together
- Multi-LoRA support with up to 5 LoRA's at once
- Better Image Quality in many cases, some improvements to the SDXL sampler were made that can produce images with higher quality
- Improved High Resolution modes that replace the old "Hi-Res Fix" and should generate better images
Smaller Changes and Additions
- Workflows created with this extension and metadata embeddings in generated images are forward-compatible with future updates of this project
- The custom node extension included in this project is backward-compatible with every workflow since version v3.3
- A text file can be saved next to generated images that contains all the settings used to generate the images
What is missing in v4.0?
Some features that were originally in v3.4 or planned for v4.x were not included in the v4.0 release, they are now planned for a future version. This was decided to get this new version released earlier and the missing features should not be important for 99% of users.
So, what is actually missing?
- Prompt Styling - (new) the ability to load styles from a template file and apply them to prompts
- Prompting Modes - (from v3.4) More advanced prompting modes, the modes from v3.4 will be re-implemented and a more flexible system to create custom prompting modes will be added on top of it
- Condition Mixing - (new) This was part of the prompting modes in v3.4 but in v4.x it will be exposed in a more flexible way as a separate module
<br><img src="docs/img/main_readme/ui-3.png" width="768">
(5 multi-purpose image inputs for revision and controlnet)
The Workflow File
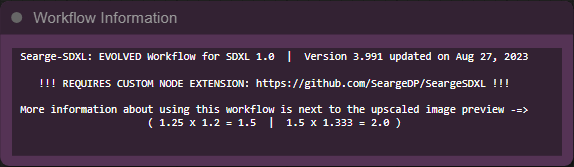
The workflow is included as a .json file in the workflow folder.
After updating Searge SDXL, always make sure to load the latest version of the json file if you want to benefit from the latest features, updates, and bugfixes.
(you can check the version of the workflow that you are using by looking at the workflow information box)
Documentation
Click this link to see the documentation
<img src="docs/img/main_readme/ui-1.png" width="768">(the main UI of the workflow)
Workflow Details
The EVOLVED v4.x workflow is a new workflow, created from scratch. It requires the latest additions to the SeargeSDXL custom node extension, because it makes use of some new node types.
The interface for using this new workflow is also designed in a different way, with all parameters that are usually tweaked to generate images tightly packed together. This should make it easier to have every important element on the screen at the same time without scrolling.
<img src="docs/img/main_readme/ui-2.png" width="768">(more advanced UI elements right next to the main UI)
Operating Modes
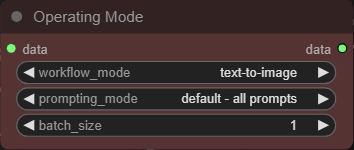
Text to Image Mode
In this mode you can generate images from text descriptions. The source image and the mask (next to the prompt inputs) are not used in this mode.
<img src="docs/img/main_readme/ui_txt2img.png" width="768">(example of using text-to-image in the workflow)
<br> <img src="docs/img/main_readme/result_txt2img.png" width="512">(result of the text-to-image example)
Image to Image Mode
In this mode you can generate images from text descriptions and a source image. The mask (next to the prompt inputs) is not used in this mode.
<img src="docs/img/main_readme/ui_img2img.png" width="768">(example of using image-to-image in the workflow)
<br> <img src="docs/img/main_readme/result_img2img.png" width="512">(result of the image-to-image example)
Inpainting Mode
In this mode you can generate images from text descriptions and a source image. Both, the source image and the mask (next to the prompt inputs) are used in this mode.
This is similar to the image to image mode, but it also lets you define a mask for selective changes of only parts of the image.
<img src="docs/img/main_readme/ui_inpainting.png" width="768">(example of using inpainting in the workflow)
<br> <img src="docs/img/main_readme/result_inpainting.png" width="512">(result of the inpainting example)
More Example Images
A small collection of example images (with embedded workflow) can be found in the examples folder. Here is an
overview of the included images.
SeargeSDXL is ready to run
It's one of 95 extensions already installed on ComfyICU — nothing to clone, nothing to reconcile. Bring a workflow and you're billed for GPU seconds, not idle time.