
ComfyUI Extension: ComfyUI_Qwen3-VL-Instruct
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
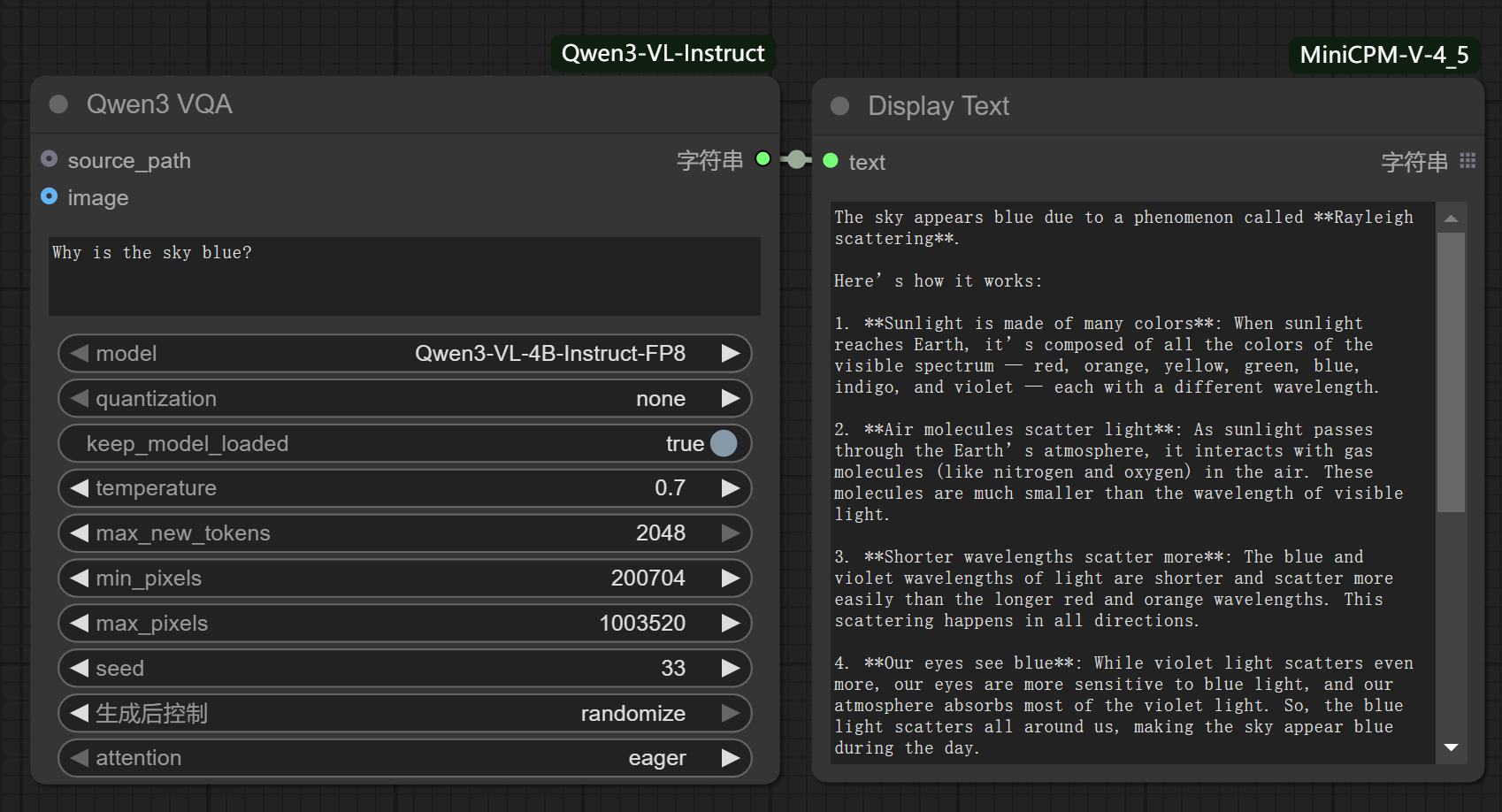
The successful integration of Qwen3-VL-Instruct series into the ComfyUI platform has enabled a smooth operation, supporting (but not limited to) text-based queries, video queries, single-image queries, and multi-image queries for generating captions or responses.
README
Comfyui_Qwen3-VL-Instruct
This is an implementation of Qwen3-VL-Instruct by ComfyUI, which includes, but is not limited to, support for text-based queries, video queries, single-image queries, and multi-image queries to generate captions or responses.
Basic Workflow
- Text-based Query: Users can submit textual queries to request information or generate descriptions. For instance, a user might input a description like "What is the meaning of life?"
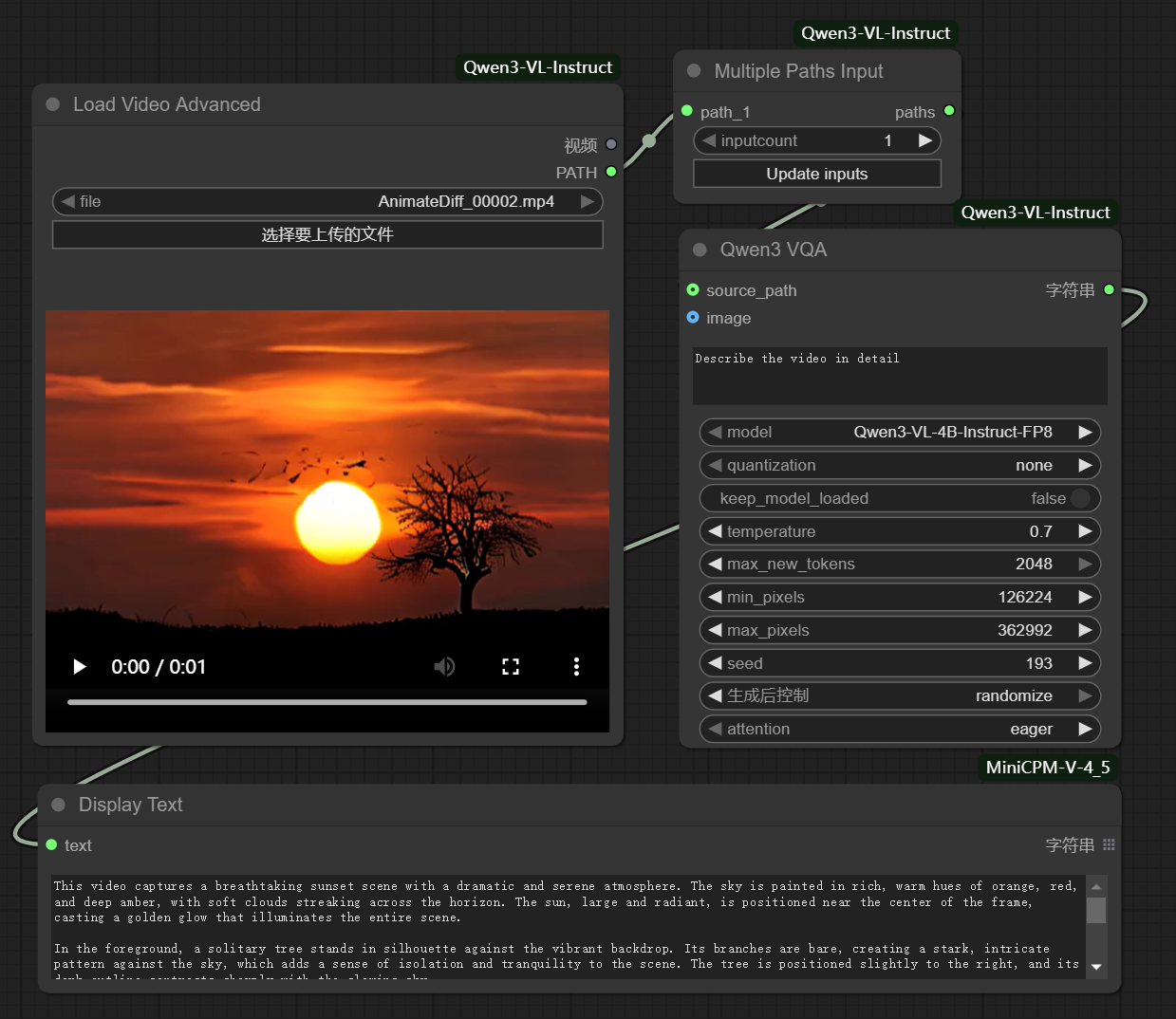
- Video Query: When a user uploads a video, the system can analyze the content and generate a detailed caption for each frame or a summary of the entire video. For example, "Generate a caption for the given video."
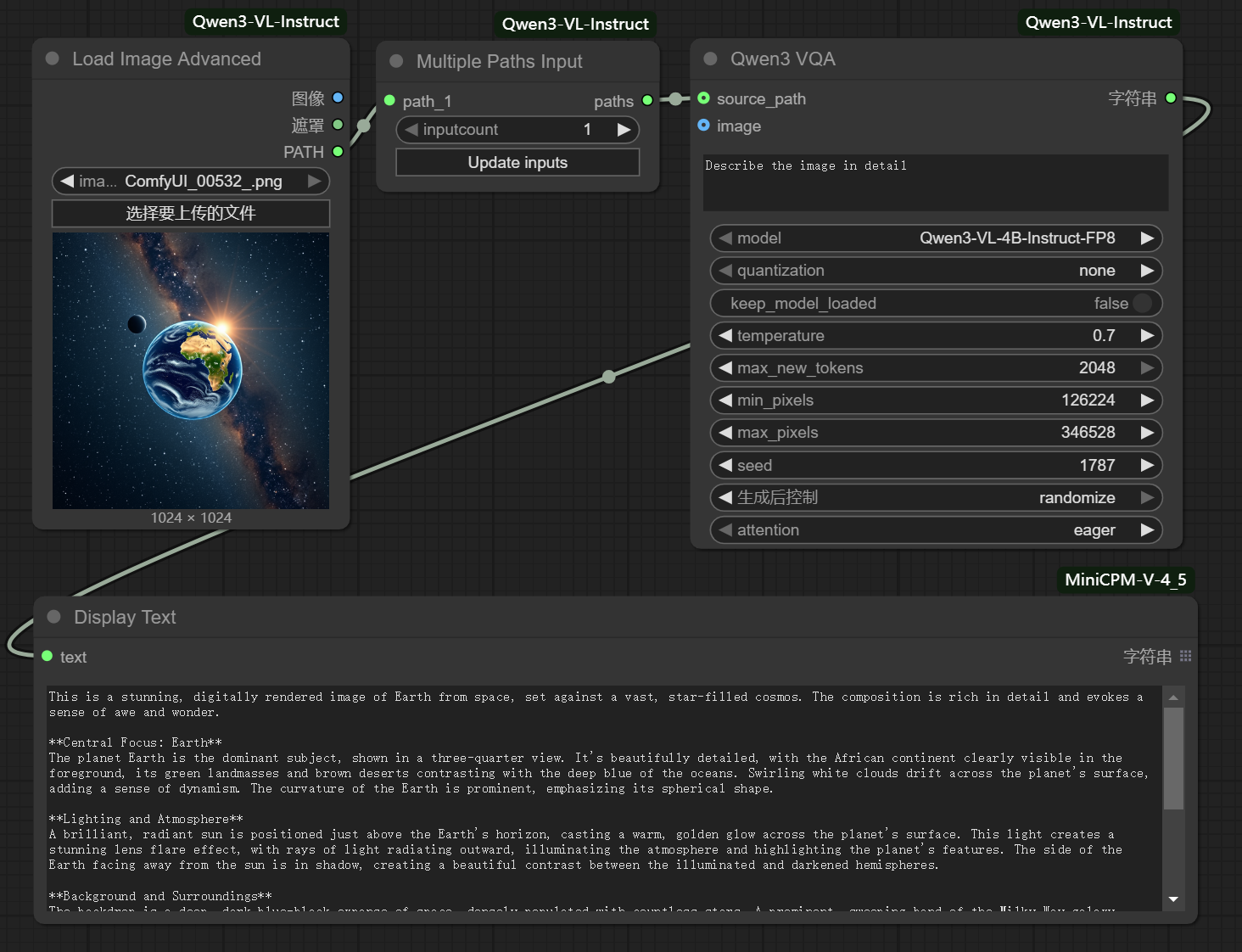
- Single-Image Query: This workflow supports generating a caption for an individual image. A user could upload a photo and ask, "What does this image show?" resulting in a caption such as "A majestic lion pride relaxing on the savannah."
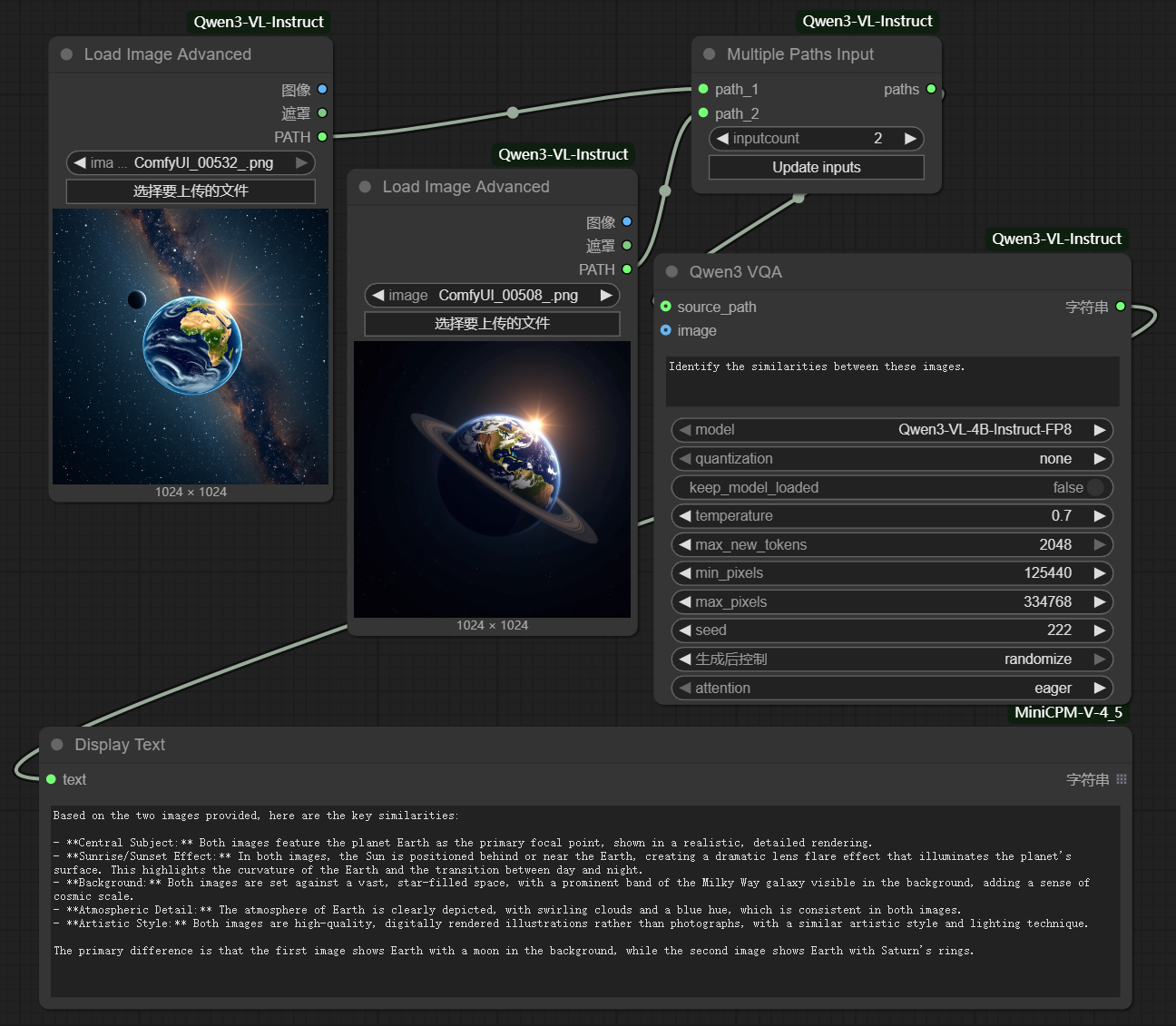
- Multi-Image Query: For multiple images, the system can provide a collective description or a narrative that ties the images together. For example, "Create a story from the following series of images: one of a couple at a beach, another at a wedding ceremony, and the last one at a baby's christening."
[!IMPORTANT] Important Notes for Using the Workflow
- Please ensure that you have the "Display Text node" available in your ComfyUI setup. If you encounter any issues with this node being missing, you can find it in the ComfyUI_MiniCPM-V-4_5 repository. Installing this additional addon will make the "Display Text node" available for use.
Installation
-
Install from ComfyUI Manager (search for
Qwen3) -
Download or git clone this repository into the
ComfyUI\custom_nodes\directory and run:
pip install -r requirements.txt
Download Models
All the models will be downloaded automatically when running the workflow if they are not found in the ComfyUI\models\prompt_generator\ directory.
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.