
ComfyUI Extension: ComfyUI-FirstOrderMM
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
ComfyUI-native nodes to run First Order Motion Model for Image Animation and its non-diffusion-based successors. a/https://github.com/AliaksandrSiarohin/first-order-model
Looking for a different extension?
Custom Nodes (9)
README
ComfyUI-FirstOrderMM
ComfyUI-native nodes to run First Order Motion Model for Image Animation and its non-diffusion-based successors.
https://github.com/AliaksandrSiarohin/first-order-model
Now supports:
- Face Swapping using Motion Supervised co-part Segmentation:
- Motion Representations for Articulated Animation
- Thin-Plate Spline Motion Model for Image Animation
- Learning Motion Refinement for Unsupervised Face Animation
- Facial Scene Representation Transformer for Face Reenactment
https://github.com/user-attachments/assets/b090061d-8f12-42c4-b046-d8b0e0a69685
Workflow:
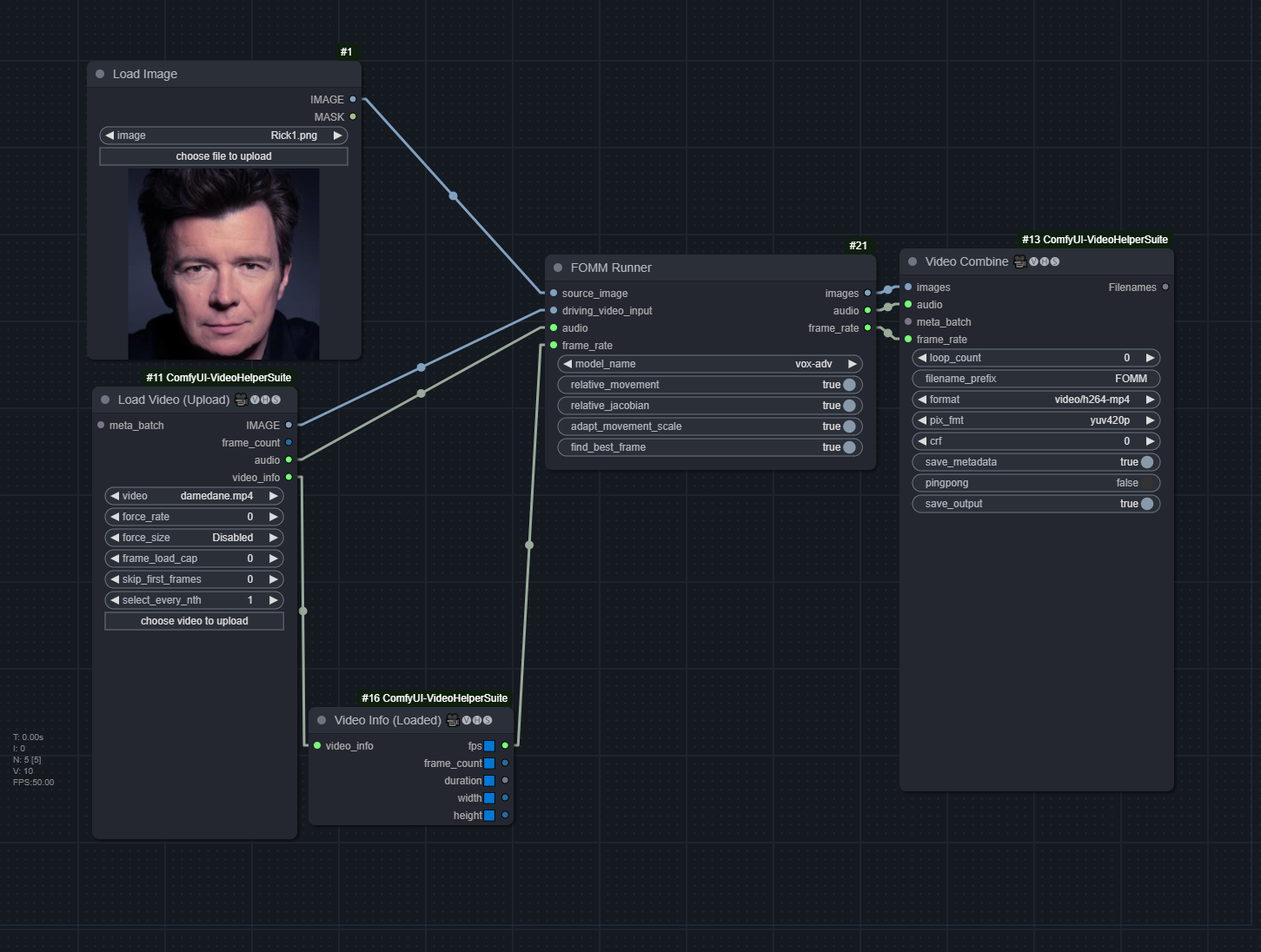
FOMM
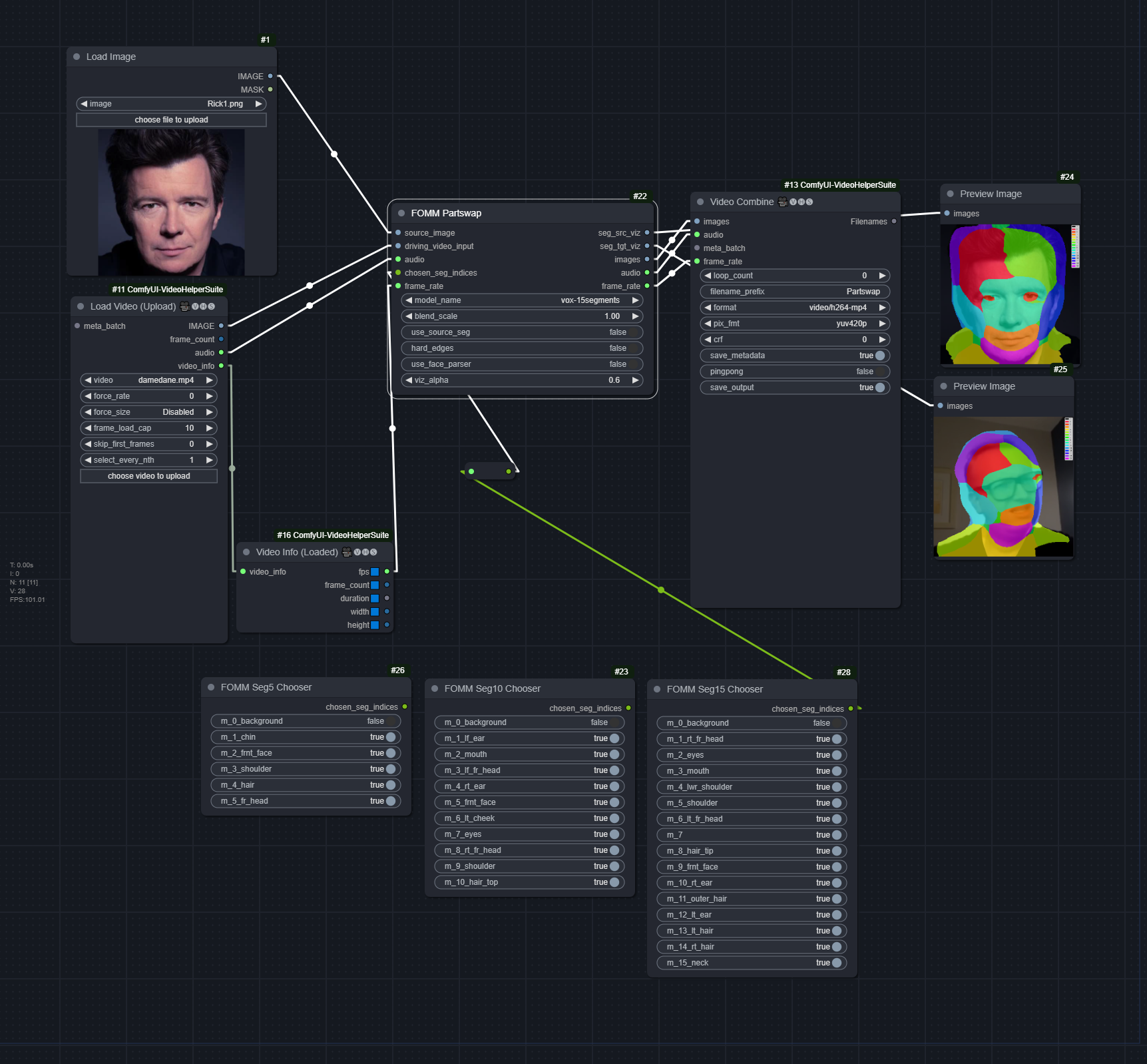
Part Swap
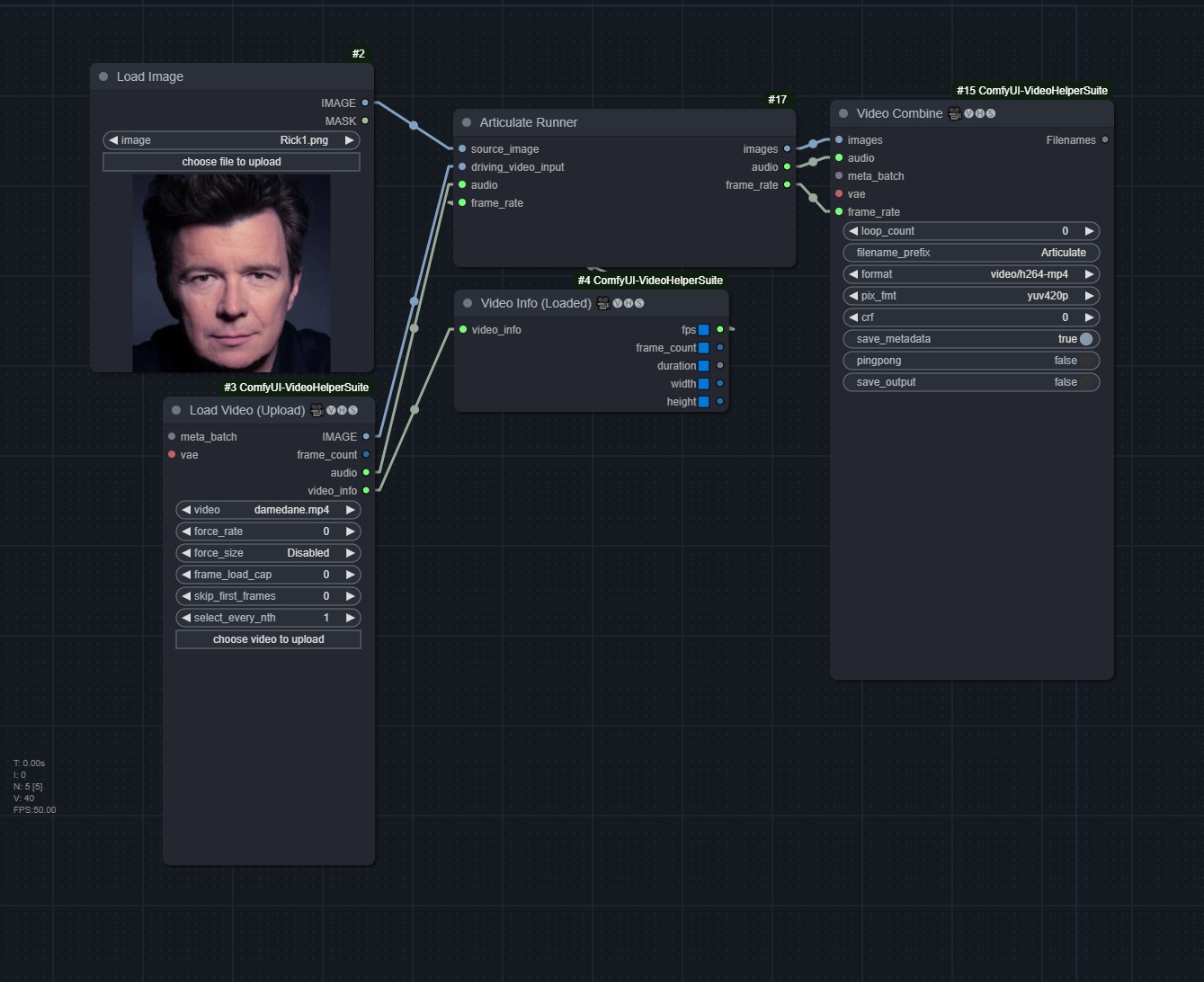
Articulate
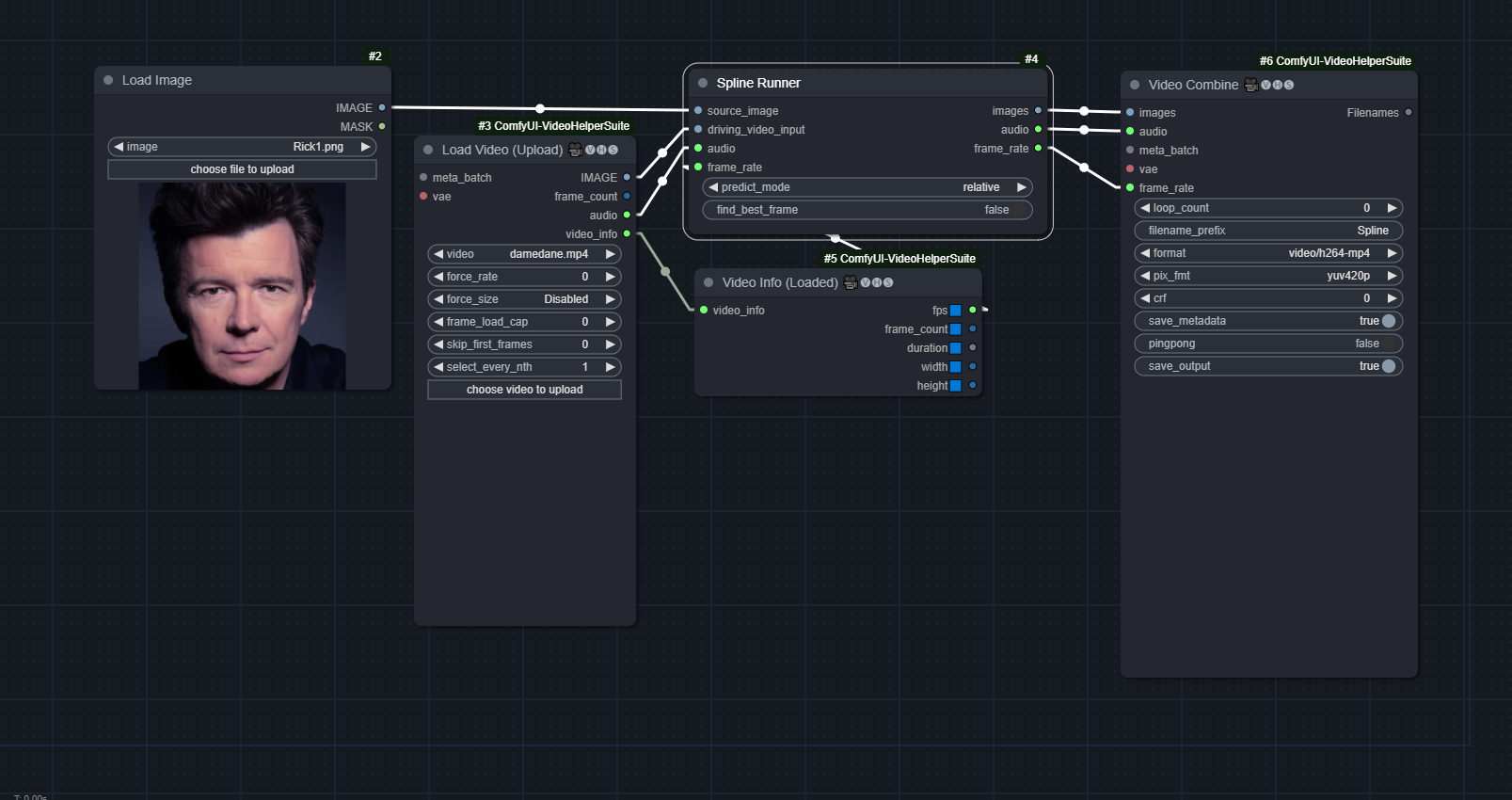
Spline
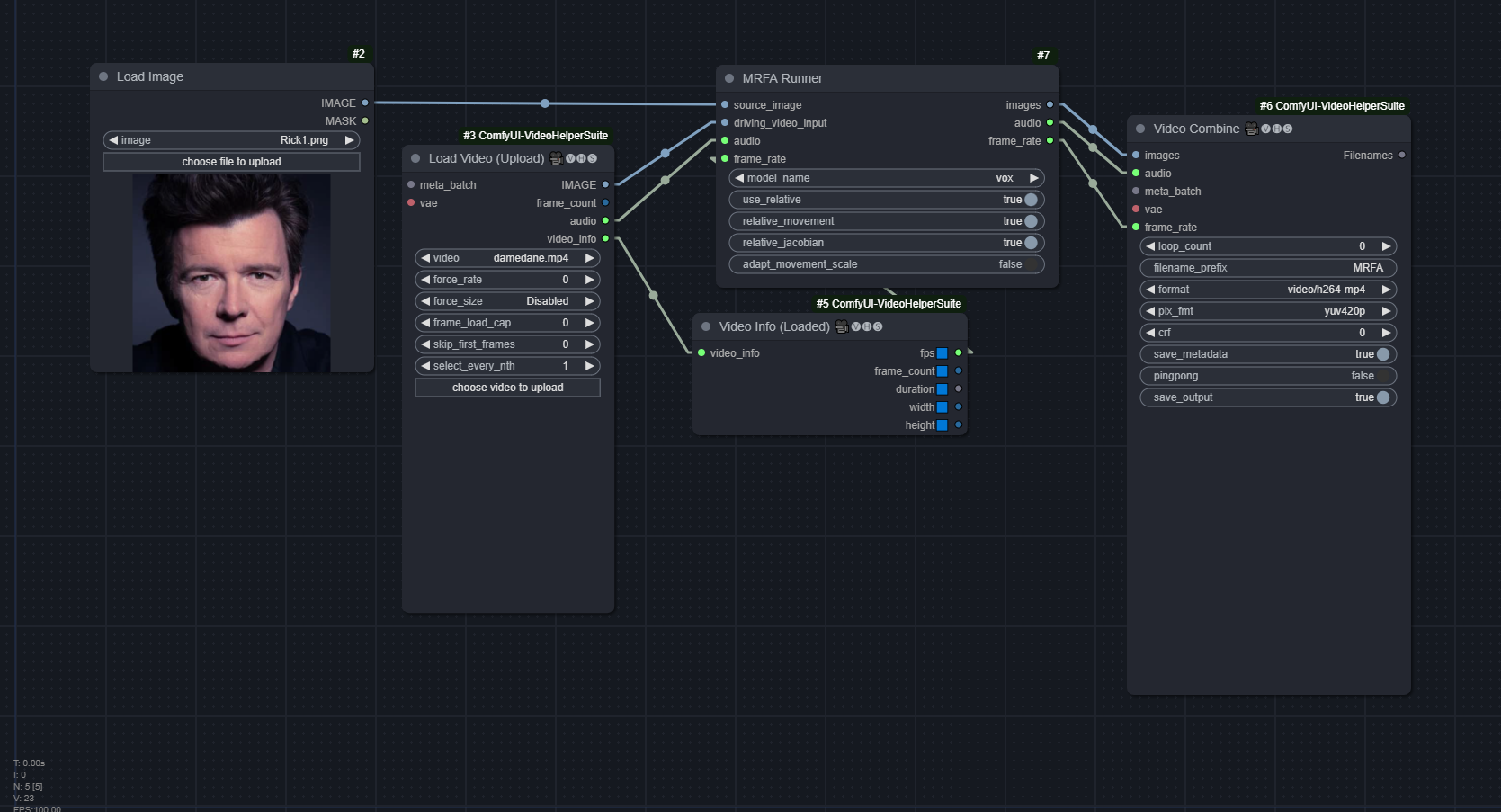
MRFA
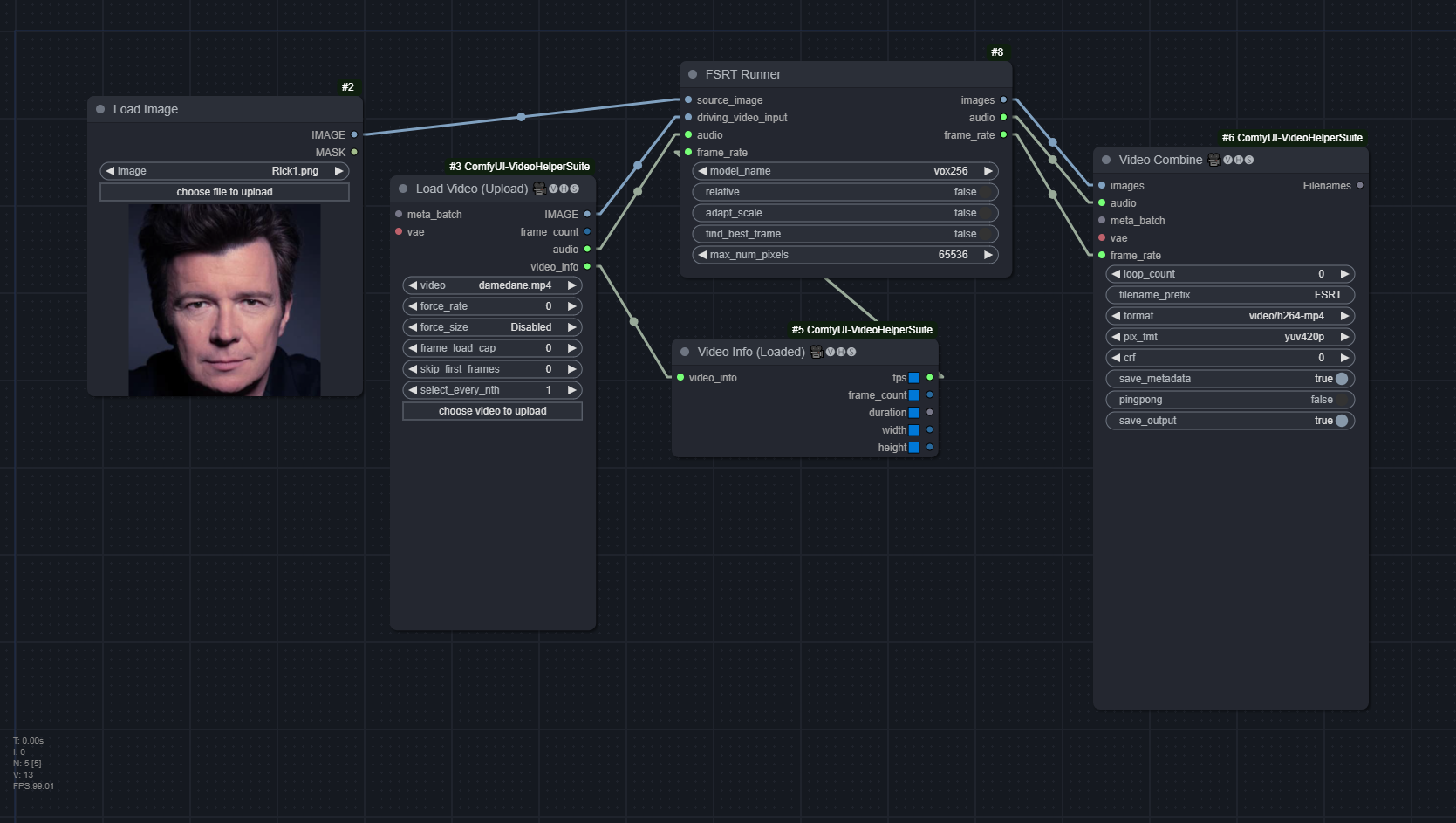
FSRT
Arguments
FOMM
relative_movement: Relative keypoint displacement (Inherit object proporions from the video)relative_jacobian: Only taken into effect whenrelative_movementis on, must also be on to avoid heavy deformation of the face (in a freaky way)adapt_movement_scale: If disabled, will heavily distort the source face to match the driving facefind_best_frame: Find driving frame that best match the source. Split the batch into two halves, with the first half reversed. Gives mixed results. Needs to installface-alignmentlibrary.
Part Swap
blend_scale: No idea, keeping at default = 1.0 seems to be fineuse_source_seg: Whether to use the source's segmentation or the target's. May help if some of the target's segmentation regions are missinghard_edges: Whether to make the edges hard, instead of featheringuse_face_parser: For Seg-based models, may help with cleaning up residual background (should only use15segwith this). TODO: Additional cleanup face_parser masks. Should definitely be used for FOMM modelsviz_alpha: Opacity of the segments in the visualization
Articulate
Doesn't need any
Spline
predict_mode: Can berelative: Similar to FOMM'srelative_movementandadapt_movement_scaleset to Truestandard: Similar to FOMM'sadapt_movement_scaleset to Falseavd: similar torelative, may yield better but more "jittery/jumpy" result
find_best_frame: Same as FOMM
MRFA
model_name:voxorcelebvhq, which is trained on (presumably) thevox256andcelebhqdatasets respectively.use_relative: Whether to use relative mode or not (absolute mode). Absolute mode is similar to FOMM'sadapt_movement_scaleset to Falserelative_movement,relative_jacobian,adapt_movement_scale: Same as FOMM
FSRT
This model takes the longest to run. The full Damedane example takes ~6 minutes
model_name:vox256orvox256_2Source, which is trained on (presumably) thevox256andvox256+celebhqdatasets respectively.use_relative: Use relative or absolute keypoint coordinatesadapt_scale: Adapt movement scale based on convex hull of keypointsfind_best_frame: Same as FOMMmax_num_pixels: Number of parallel processed pixels. Reduce this value if you run out of GPU memory
Installation
- Clone the repo to
ComfyUI/custom_nodes/
git clone https://github.com/FuouM/ComfyUI-FirstOrderMM.git
- Install required dependencies
pip install -r requirements.txt
Optional: Install face-alignment to use the find_best_frame feature:
pip install face-alignment
Models
FOMM and Part Swap
FOMM: vox and vox-adv from
Part Swap
vox-5segmentsvox-10segmentsvox-15segmentsvox-first-order (partswap)
These models can be found in the original repository Motion Supervised co-part Segmentation
Place them in the checkpoints folder. It should look like this:
place_checkpoints_here.txt
vox-adv-cpk.pth.tar
vox-cpk.pth.tar
vox-5segments.pth.tar
vox-10segments.pth.tar
vox-15segments.pth.tar
vox-first-order.pth.tar
For Part Swap, Face-Parsing is also supported (Optional) (especially when using the FOMM or vox-first-order models)
- resnet18
resnet18-5c106cde: https://download.pytorch.org/models/resnet18-5c106cde.pth - face_parsing
79999_iter.pth: https://github.com/zllrunning/face-makeup.PyTorch/tree/master/cp
Place them in face_parsing folder:
face_parsing_model.py
...
resnet18-5c106cde.pth
79999_iter.pth
Other
| Model Arch | File Path | Source |
|------------|-----------|--------|
| Articulate | module_articulate/models/vox256.pth | Articulated Animation (Pre-trained checkpoints) |
| Spline | module_articulate/models/vox.pth.tar | Thin Plate Spline Motion Model (Pre-trained models) |
| MRFA (celebvhq) | module_mrfa/models/celebvhq.pth | MRFA (Pre-trained checkpoints) |
| MRFA (vox) | module_mrfa/models/vox.pth | MRFA (Pre-trained checkpoints) |
| FSRT (kp_detector) | module_fsrt/models/kp_detector.pt | FSRT (Pretrained Checkpoints) |
| FSRT (vox256) | module_fsrt/models/vox256.pt | FSRT (Pretrained Checkpoints) |
| FSRT (vox256_2Source) | module_fsrt/models/vox256_2Source.pt | FSRT (Pretrained Checkpoints) |
Notes:
- For Spline and FSRT, to use
find_best_frame, follow above instructions to installface-alignmentwith its models. - For FSRT, you must download
kp_detector
Credits
@InProceedings{Siarohin_2019_NeurIPS,
author={Siarohin, Aliaksandr and Lathuilière, Stéphane and Tulyakov, Sergey and Ricci, Elisa and Sebe, Nicu},
title={First Order Motion Model for Image Animation},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
month = {December},
year = {2019}
}
@InProceedings{Siarohin_2019_NeurIPS,
author={Siarohin, Aliaksandr and Lathuilière, Stéphane and Tulyakov, Sergey and Ricci, Elisa and Sebe, Nicu},
title={First Order Motion Model for Image Animation},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
month = {December},
year = {2019}
}
@inproceedings{siarohin2021motion,
author={Siarohin, Aliaksandr and Woodford, Oliver and Ren, Jian and Chai, Menglei and Tulyakov, Sergey},
title={Motion Representations for Articulated Animation},
booktitle = {CVPR},
year = {2021}
}
@inproceedings{
tao2023learning,
title={Learning Motion Refinement for Unsupervised Face Animation},
author={Jiale Tao and Shuhang Gu and Wen Li and Lixin Duan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=m9uHv1Pxq7}
}
@inproceedings{rochow2024fsrt,
title={{FSRT}: Facial Scene Representation Transformer for Face Reenactment from Factorized Appearance, Head-pose, and Facial Expression Features},
author={Rochow, Andre and Schwarz, Max and Behnke, Sven},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.