ComfyUI Extension: ComfyUI-DeZoomer-Nodes
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
A collection of custom nodes for ComfyUI.
README
ComfyUI DeZoomer Nodes
A collection of custom nodes for ComfyUI. Currently includes:
Installation
Option 1 (Recommended): Install via ComfyUI-Manager
- Install ComfyUI-Manager
- Open ComfyUI
- Click on "Manager" tab
- Click on "Custom Nodes Manager"
- Search for "DeZoomer"
- Click "Install" on "ComfyUI-DeZoomer-Nodes"
Option 2: Manual Installation
<details> <summary>Click to expand</summary>- Clone this repository into your ComfyUI's
custom_nodesfolder:
git clone https://github.com/De-Zoomer/ComfyUI-DeZoomer-Nodes.git
- Install the required dependencies:
cd ComfyUI-DeZoomer-Nodes
pip install -r requirements.txt
- If you're using the portable version of ComfyUI, run this command in the ComfyUI_windows_portable folder:
python_embeded\python.exe -m pip install -r ComfyUI\custom_nodes\ComfyUI-DeZoomer-Nodes\requirements.txt
Changelog
All notable changes to this project will be documented in this section.
<details> <summary>Click to expand</summary>1.0.3
- Add ShotVL as an option on Video Captioning node.
1.0.2
- Add SkyCaptioner-V1 as an option on Video Captioning node.
1.0.1
- Memory management improvements.
1.0.0
- Initial release with Video Captioning and Caption Refinement nodes.
Video Captioning Node
Takes video frames and generates detailed captions using the Qwen2.5-VL model.
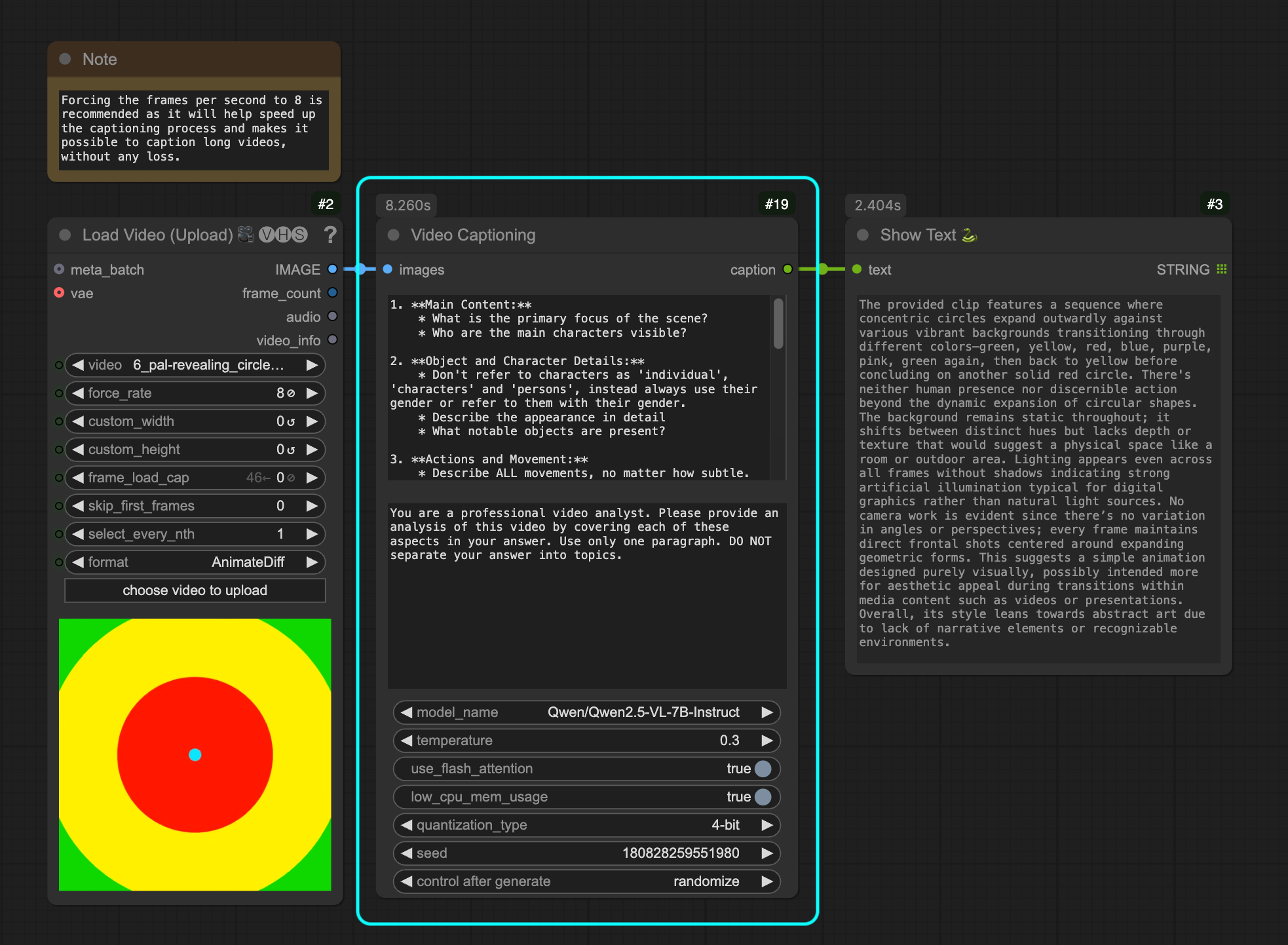
Parameters
- Images: Input video frames to process (ComfyUI's IMAGE type)
- User Prompt: Detailed instructions for what aspects to analyze (default provided)
- System Prompt: Instructions for the model's behavior and output style
- Model Name: Qwen2.5-VL model to use. Also supports SkyCaptioner-V1 and ShotVL (default: "Qwen/Qwen2.5-VL-7B-Instruct")
- Temperature: Controls randomness in generation (default: 0.3)
- Use Flash Attention: Enables faster attention implementation (default: True)
- Low CPU Memory Usage: Optimizes for low CPU memory usage (default: True)
- Quantization Type: Memory optimization (4-bit or 8-bit)
- Keep Model Loaded: Option to keep model in memory after processing (default: False)
- Seed: Random seed for reproducible generation
It's a porting node from @cseti007 on his Qwen2.5-VL-Video-Captioning. The node processes video frames and generates comprehensive descriptions covering:
- Main content and characters
- Object and character details
- Actions and movements
- Background elements
- Visual style
- Camera work
- Scene transitions
Requirements
- CUDA-compatible GPU (recommended)
- At least 16GB of GPU memory for optimal performance
Caption Refinement Node
Takes a caption and refines it using the Qwen2.5 model.
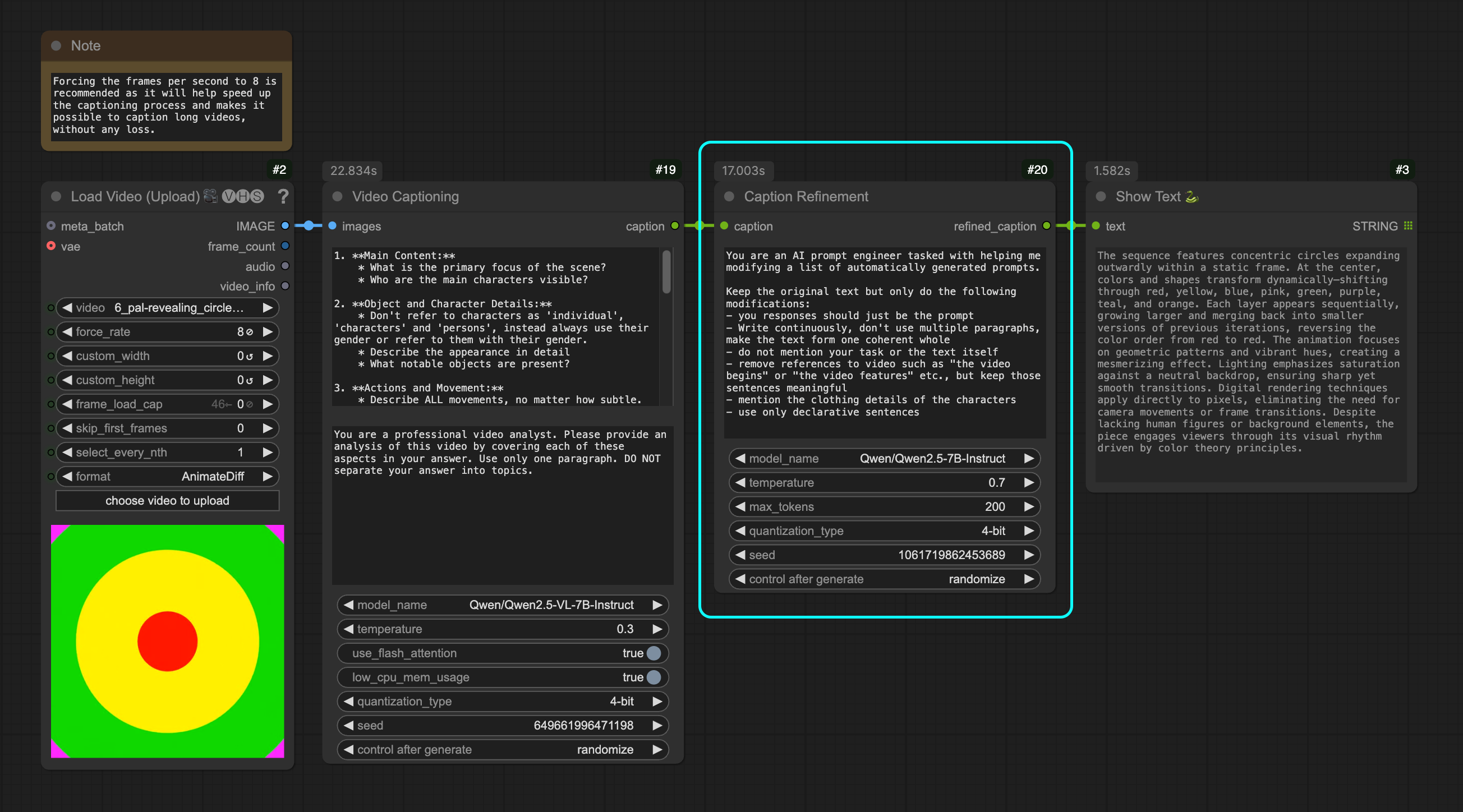
Parameters
- Caption: Input caption to refine (required)
- System Prompt: Instructions for the model's behavior and output style
- Model Name: Qwen2.5 model to use (default: "Qwen/Qwen2.5-7B-Instruct")
- Temperature: Controls randomness in generation (default: 0.7)
- Max Tokens: Maximum tokens for refinement output (default: 200)
- Quantization Type: Memory optimization (4-bit or 8-bit)
- Keep Model Loaded: Option to keep model in memory after processing (default: False)
- Seed: Random seed for reproducible generation
The node refines captions by:
- Making the text more continuous and coherent
- Removing video-specific references
- Adding clothing details
- Using only declarative sentences
Requirements
- CUDA-compatible GPU (recommended)
- At least 16GB of GPU memory on 4-bit quantization (>18GB GPU for 8-bit)
License
This project is licensed under the GPL License - see the LICENSE file for details.
Acknowledgments
This project uses the following models developed by Alibaba Cloud:
- Qwen2.5-VL model for video captioning
- ShotVL-7B model for video captioning
- SkyCaptioner-V1 model for video captioning
- Qwen2.5 model for caption refinement
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.