ComfyUI Extension: ComfyUI-Google-AI-Studio
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.
Google AI Studio by BuffMcBigHuge
Looking for a different extension?
Custom Nodes (0)
README
ComfyUI Google AI Studio Nodes
This custom node package provides integration with Google AI Studio's latest APIs for ComfyUI, including Text-to-Speech (TTS), Text Generation, and Image Generation (Nano Banana) using the google-genai Google Gen AI SDK (Google AI Studio).
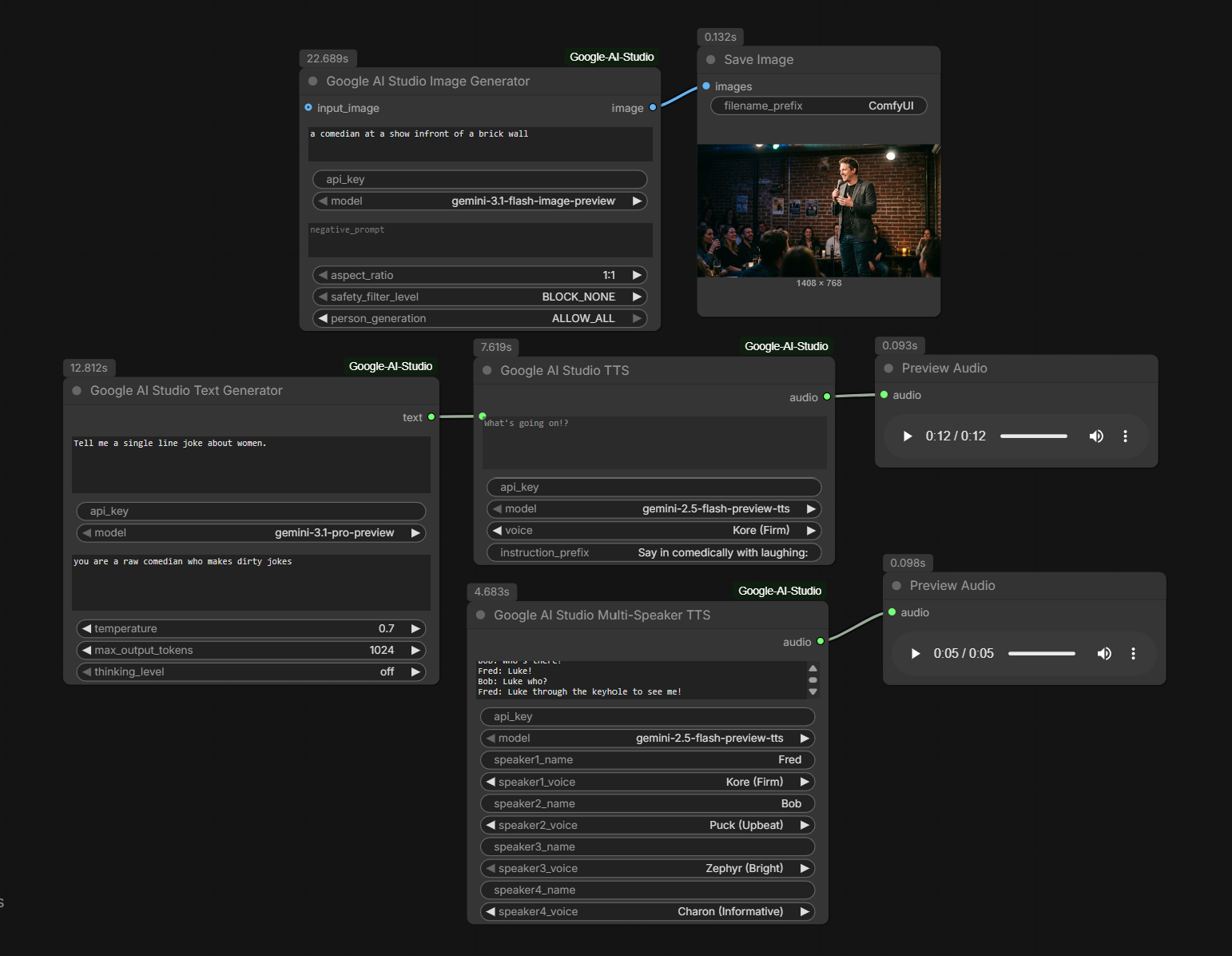
Features
- Text Generation: Generate creative text, stories, essays using Gemini models
- Image Generation: Create stunning images using Google's Gemini (free) and Imagen (paid) models
- Image Editing: Edit existing images using Gemini 2.5 Flash with multimodal input support
- Batch Processing: Process multiple images simultaneously in a single API call
- Google AI Studio TTS: Convert text to speech using Google's Gemini TTS models
- Multi-Speaker TTS: Generate conversations with multiple distinct voices
- 30+ Voice Options: Choose from a wide variety of high-quality voices with style descriptions
Installation
-
Clone this repository into your ComfyUI
custom_nodesdirectory:cd ComfyUI/custom_nodes git clone https://github.com/BuffMcBigHuge/ComfyUI-Google-AI-Studio.git -
Install the required dependencies:
cd ComfyUI-Google-AI-Studio pip install -r requirements.txt -
Get your Google AI Studio API key:
- Visit https://aistudio.google.com/
- Sign up or log in
- Generate an API key
- Keep this key secure
-
Restart ComfyUI
Nodes
Google AI Studio Text Generator
Generates text using Google's Gemini models for creative writing, essays, code, and more.
Inputs:
prompt: The text prompt to generate from (multiline supported)api_key: Your Google AI Studio API keymodel: Choose from Gemini models (gemini-2.5-flash, gemini-2.5-pro, gemini-3.1-pro-preview, etc.)system_instruction(optional): Guide the model's behavior and tonetemperature(optional): Controls creativity (0.0-2.0, default 0.7)max_output_tokens(optional): Maximum tokens to generate (1-8192, default 1024)thinking_level(optional): Reasoning depth for Gemini 2.5/3 (off, low, medium, high)
Output:
text: Generated text content
Google AI Studio Image Generator
Creates images using Google's Gemini and Imagen models from text descriptions.
Available Models:
gemini-3.1-flash-image-preview- Free tier (default, Nano Banana 2)gemini-3-pro-image-preview- Free tier (Nano Banana Pro)gemini-2.5-flash-image- Free tier (Nano Banana, efficient)imagen-4.0-fast-generate-001- Paid tier (Imagen 4 Fast)imagen-4.0-generate-001- Paid tier (Imagen 4)imagen-4.0-ultra-generate-001- Paid tier (Imagen 4 Ultra)imagen-3.0-fast-generate-001- Paid tier (Imagen 3 Fast)
Inputs:
prompt: Description of the image to generate or editapi_key: Your Google AI Studio API keymodel: Choose from available models aboveinput_image(optional): Input image(s) for editing/modification - supports batch processing (⚠️ Gemini models only)negative_prompt(optional): What you don't want in the image (works with all models)aspect_ratio(optional): Image proportions (⚠️ Imagen only - ignored for Gemini)safety_filter_level(optional): Content filtering (⚠️ Imagen only - ignored for Gemini)person_generation(optional): People generation controls (⚠️ Imagen only - ignored for Gemini)
Google AI Studio TTS
Converts text to speech using Google's Gemini TTS models.
Inputs:
text: The text to convert to speech (multiline supported)api_key: Your Google AI Studio API keymodel: Choose betweengemini-2.5-flash-preview-ttsorgemini-2.5-pro-preview-ttsvoice: Select from 30+ available voices (Kore, Puck, Zephyr, etc.)instruction_prefix(optional): Add style instructions like "Say cheerfully:" or "Read slowly:"
Output:
audio: Audio data compatible with ComfyUI audio nodes
Google AI Studio Multi-Speaker TTS
Generates conversations with multiple distinct voices.
Inputs:
transcript: Multi-line text with speaker names (format: "Speaker Name: dialogue")api_key: Your Google AI Studio API keymodel: TTS model selectionspeaker1_name/speaker1_voice: First speaker configurationspeaker2_name/speaker2_voice: Second speaker configurationspeaker3_name/speaker3_voice(optional): Third speakerspeaker4_name/speaker4_voice(optional): Fourth speaker
Output:
audio: Multi-speaker audio data
Model Capabilities:
| Feature | Gemini Models (Free) | Imagen Models (Paid) | |---------|---------------------|---------------------| | Text-to-image | ✅ | ✅ | | Image-to-image editing | ✅ | ❌ | | Negative prompts | ✅ (in main prompt) | ✅ (separate parameter) | | Aspect ratio control | ❌ | ✅ | | Safety filter levels | ❌ (built-in safety) | ✅ | | Person generation control | ❌ | ✅ |
Output:
image: Generated image compatible with ComfyUI image nodes
Available Voices
The following 30 voices are available, each with distinct characteristics:
| Voice | Style | Voice | Style | Voice | Style | |-------|--------|-------|--------|-------|--------| | Zephyr | Bright | Puck | Upbeat | Charon | Informative | | Kore | Firm | Fenrir | Excitable | Leda | Youthful | | Orus | Firm | Aoede | Breezy | Callirrhoe | Easy-going | | Autonoe | Bright | Enceladus | Breathy | Iapetus | Clear | | Umbriel | Easy-going | Algieba | Smooth | Despina | Smooth | | Erinome | Clear | Algenib | Gravelly | Rasalgethi | Informative | | Laomedeia | Upbeat | Achernar | Soft | Alnilam | Firm | | Schedar | Even | Gacrux | Mature | Pulcherrima | Forward | | Achird | Friendly | Zubenelgenubi | Casual | Vindemiatrix | Gentle | | Sadachbia | Lively | Sadaltager | Knowledgeable | Sulafat | Warm |
Supported Languages
The TTS models automatically detect input language and support 24 languages including:
- English (US, India)
- Spanish (US)
- French (France)
- German (Germany)
- Italian (Italy)
- Portuguese (Brazil)
- Japanese (Japan)
- Korean (Korea)
- Chinese (Simplified, Traditional)
- Hindi (India)
- Arabic (Egyptian)
- Russian (Russia)
- And more...
Usage Examples
Text Generation Example
- Add a "Google AI Studio Text Generator" node
- Enter your prompt:
"Write a creative short story about a robot learning to paint" - Enter your API key
- Select model:
gemini-2.5-flash - Adjust temperature for creativity (0.7 for balanced, 1.5 for very creative)
- Connect output to text display or save node
Image Generation Example
- Add a "Google AI Studio Image Generator" node
- Enter your prompt:
"A serene Japanese garden with cherry blossoms and a small pond" - Enter your API key
- Select model:
gemini-3.1-flash-image-preview(free tier, default) - For advanced controls (paid tier), switch to
imagen-4.0-generate-001and adjust aspect ratio, safety settings - Connect output to image preview or save node
Image Editing Example
- Add a "Google AI Studio Image Generator" node
- Connect an input image to the
input_imageparameter - Enter your editing prompt:
"Add a rainbow in the sky and make it look more vibrant" - Enter your API key
- Select a Gemini model (2.5 Flash or 3.1 Flash Image - image editing only works with Gemini models)
- Connect output to image preview or save node
Batch Image Processing Example
- Add a "Google AI Studio Image Generator" node
- Connect a batch of images to the
input_imageparameter (e.g., from an image batch loader) - Enter your editing prompt:
"Apply vintage film effect to these images" - Enter your API key
- Select a Gemini model - all images in the batch will be sent in a single API call
- Connect output to image preview or save node
Basic TTS Example
- Add a "Google AI Studio TTS" node
- Enter your text:
"Welcome to my podcast! Today we're discussing AI." - Enter your API key
- Select voice:
Kore - Connect output to audio preview or save node
Multi-Speaker Conversation Example
- Add a "Google AI Studio Multi-Speaker TTS" node
- Enter transcript:
Host: Welcome to Tech Talk! Guest: Thanks for having me on the show. Host: Let's dive into today's topic. - Configure speakers:
- Speaker 1:
Hostwith voiceKore - Speaker 2:
Guestwith voicePuck
- Speaker 1:
- Connect output to audio nodes
Style Control Example
Use the instruction_prefix to control speech style:
"Say cheerfully:"- Upbeat delivery"Read slowly and clearly:"- Careful pronunciation"Speak in a whisper:"- Quiet, intimate tone"Say with excitement:"- Energetic delivery
Technical Details
- Audio Format: 24kHz, 16-bit PCM, mono/stereo
- Context Window: 32k tokens maximum
- Output Format: ComfyUI-compatible audio tensors
- API Rate Limits: Subject to Google AI Studio quotas
Troubleshooting
Common Issues
-
"Google AI SDK not installed"
- Run:
pip install google-genai
- Run:
-
"API key is required"
- Get your key from https://aistudio.google.com/
- Ensure the key is entered correctly
-
"TTS generation failed"
- Check your internet connection
- Verify API key is valid and has quota remaining
- Ensure text is within the 32k token limit
-
Audio playback issues
- Ensure ComfyUI audio nodes are properly connected
- Check that audio preview nodes support the format
API Limits
- Free tier: Limited requests per minute
- Check your usage at Google AI Studio
Support
For issues specific to these nodes:
- Check the Issues page
- Review the troubleshooting section above
For Google AI Studio API issues:
- Visit Google AI Studio documentation
- Check the Google AI Forum
License
This project is licensed under the MIT License - see the LICENSE file for details.
Changelog
v1.2.0 - Model Updates & Thinking Control
🆕 New Features
- Thinking Level: Optional
thinking_levelparameter for Text Generator (off, low, medium, high) - controls reasoning depth for Gemini 2.5/3 models
🔄 Model Updates (per Gemini API changelog & deprecations)
- Text Generator: Added gemini-3.1-pro-preview, gemini-3.1-flash-lite-preview, gemini-3-flash-preview, gemini-2.5-pro, gemini-2.5-flash, gemini-2.5-flash-lite. Removed deprecated gemini-3-pro-preview, gemini-2.0-flash-001. Default: gemini-2.5-flash
- Image Generator: Added gemini-3.1-flash-image-preview (Nano Banana 2), imagen-4.0-fast-generate-001, imagen-4.0-ultra-generate-001. Default: gemini-3.1-flash-image-preview
v1.1.0 - Image Editing & Batch Processing
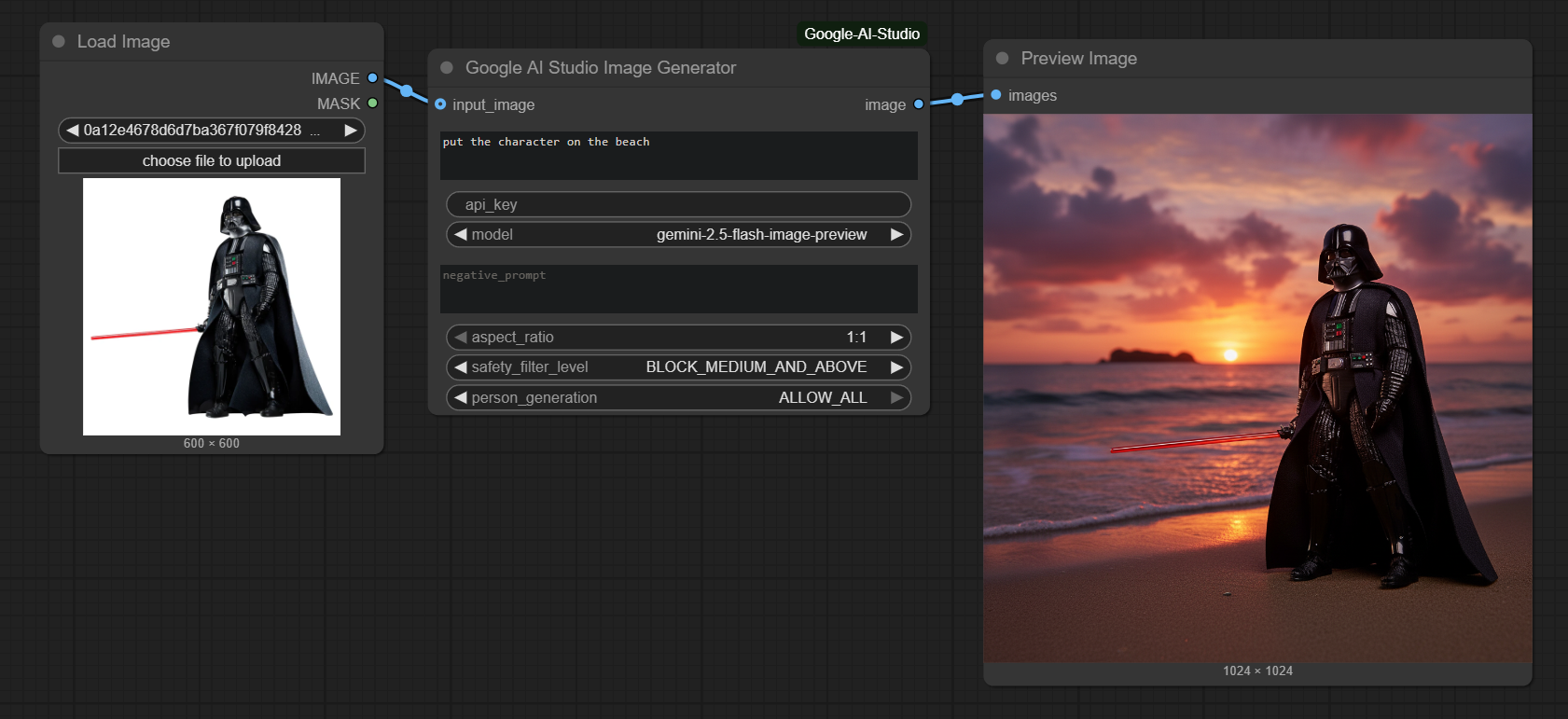 New Feature: Image editing with Gemini 2.5 Flash - example shows transforming Darth Vader with the prompt "put the character on the beach"
New Feature: Image editing with Gemini 2.5 Flash - example shows transforming Darth Vader with the prompt "put the character on the beach"
🆕 New Features
-
Image Editing Support: Added Gemini 2.5 Flash image editing capabilities
- Edit existing images with text prompts using multimodal input
- Supports single images or batch processing
- Works with all ComfyUI image nodes and workflows
-
Gemini 3 Models: Added support for
gemini-3-pro-previewandgemini-3-pro-image-preview. -
Gemini 2.5 Flash Image Model: Updated to
gemini-2.5-flash-image. -
Imagen 4: Added
imagen-4.0-generate-001.- Latest Google image generation model
- Free tier access with advanced capabilities
- Enhanced image quality and prompt understanding
🔄 Improvements
- Enhanced Image Generator node with optional
input_imageparameter - Updated API integration with proper multimodal Content/Part structure
- Improved batch processing efficiency for multiple images
- Better error handling for image conversion and processing
Note: This is an unofficial community-created integration. Google AI Studio is a product of Google LLC.
Run ComfyUI workflows without the setup
No installs, no CUDA version roulette, no GPU sitting idle on your bill. Bring a workflow and run it in the browser.