
ZavyChromaXL: b1: zavychromaxl_b1.safetensors





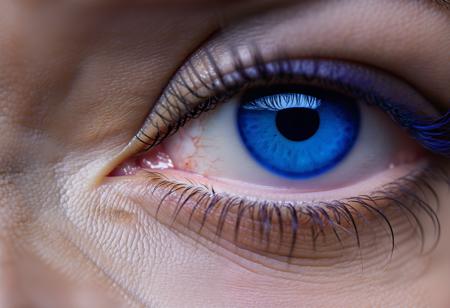














Beta version of this SDXL model
Fixed color/shadow blotching - a much smoother gradient now.
More prone to do interesting poses.
More aligned with my SD1.5 ZavyMix stylistically - better magical effects, while retaining realism.
Slight noticeable issue with eyelashes on portrait images.
For business inquiries, commercial licensing, custom models, and consultations, please get in touch at [email protected] or [email protected]. You can also contact me here through CivitAI DM or join my Discord.
Note: commercial licensing is a requirement for all generative services other than CivitAI. It's also a requirement for companies using it in a commercial setting; e.g. marketing materials, fashion shoots, apps for photo/video editing, etcetera. The only commercial usage that does not need a commercial license is for artists selling their imagery as prints and such.
Consider using DPM++ 3M SDE Exponential or DPM++ SDE Karras for this model, I personally like them best, 3M SDE Expo for most styles, DPM++ SDE Karras for photorealistic. Make sure to read the prompt advice further on in this section if you want to create photorealistic images as well as some of the sample images.
For anyone wondering - I will not be supporting the merging of LoRAs/uNET such as Lightning, which quickens rendering speed at a loss of significant quality and flexibility, into checkpoints. Read my further thoughts in this article. Read further in this section for settings if you use the Lightning LoRA in conjunction with this model.
This model will always remain publicly available for download. It is important to note in this scene that full exclusivity will never be considered. If you have any commercial proposals or are interested in engaging in commercial activities beyond simply selling images as an artist, I encourage you to contact me. I am open to further discussions and exploring potential collaborations in these areas.Introduction
A model line that should be a continuance of the ZavyMix SD1.5 model for SDXL. The primary focus is to get a similar feeling in style and uniqueness that model had, where it's good at merging magic with realism, really merging them together seamlessly. Of course with the evolution to SDXL this model should have better quality and coherance for a lot of things, including the eyes and teeth than the SD1.5 models. This model has no need to use the refiner for great results, in fact it usually is preferable to not use the refiner. Recommended to use ultimate SD upscaler to get the most amazing results.
Continue reading for more information and some tips and tricks.
I kindly request that you share your creations both here and on my Discord server, as I would greatly appreciate the opportunity to see them and motivate me to spend more time in further ventures here.

Pros and cons
Pros
Much better saturation than base model.
Much better teeth, eyes, hands and feet.
Increased realism.
Less blurry edges but still keeps a certain pleasing softness to the image.
Better looking people.
Great texture and tonality.
Cons
NSFW much better than base, but still somewhat lacking without LORAs.
Roadmap
Training the SDXL model continuously.
Pioneering uncharted LORA subjects (withholding specifics to prevent preemption).
Tips
To better understand the preferences of the model, individuals are encouraged to utilise the provided prompts as a foundation and then customise, modify, or expand upon them according to their desired objectives.
Ditch the refiner, an img2img ultimate SD upscaler gets better results when you select this model for it.
For photorealism, use nmkdSiaxCX_200k for initial upscale, consider using ultramix_balanced for final upscale/pass to lessen grainy pictures.
Consider using face restoration techniques when the result for the face is subpar, but the rest of the image is interesting.
If you find that the details in your work are lacking, consider using wowifier if you’re unable to fix it with prompt alone. wowifier or similar tools can enhance and enrich the level of detail, resulting in a more compelling output.
ComfyUI is the UI I use for my SDXL images.
Your 1.5 LORAs won't work in SDXL.
Consider finding new prompts, don't use the standard 1.5 ones. SDXL likes a combination of a natural sentence with some keywords added behind.
To maintain optimal results and avoid excessive duplication of subjects, limit the generated image size to a maximum of 1024x1024 pixels or 640x1536 (or vice versa). If you require higher resolutions, it is recommended to utilise the Hires fix, followed by the img2img upscale technique, with particular emphasis on the controlnet tile upscale method. This approach will help you achieve superior results when aiming for higher resolution outputs. However, as this workflow doesn't work with SDXL yet, you may want to use an SD1.5 model for the img2img step.
Prompts
Recommended positive prompts for specifically photorealism: 2000s vintage RAW photo, photorealistic, film grain, candid camera, color graded cinematic, eye catchlights, atmospheric lighting, macro shot, skin pores, imperfections, natural, shallow dof, or other photography related tokens.
Recommended negative prompts: As few negative prompts as you can, only use it when it does something you do not want, like watermarks. Consider using high contrast, oily skin, plastic skin if the skin is too contrasting or too oily/plastic. Also make sure to add anime to negative prompt if you want better photorealism, and more mature looking characters.
You are further encouraged to include additional specific details regarding the desired output. This should involve specifying the preferred style, camera angle, lighting techniques, poses, color schemes, and other relevant factors.
Recommended settings
sdxl_vae.safetensors (baked in).
DPM++ 3M SDE Exponential, DPM++ SDE Karras, DPM++ 2M SDE Karras, DPM++ 2M Karras, Euler A
Steps 20~40 (lower range for DPM, higher range for Euler).
Hires upscaler: nmkdSiaxCX_200k, UltraMix_Balanced.
Hires upscale: Whatever maximum your GPU is capable of, but preferably between 1.5x~2x.
CFG scale 4-10 (preferably somewhere around cfg 6-7)
Lightning LoRA specific settings:
Euler sampler with SGM Uniform as Scheduler.
Steps 4 (use the 4 steps LoRA)
CFG scale 1-2 (CFG 1 at the higher weights for the LoRA)
LoRA weight 0.6-1
Model recipe
Trained from SDXL 1.0.
Social media
You are welcome to join my recently created Discord server, where we can engage in discussions, share our experiences in AI, and showcase the things we’ve made with AI. You are encouraged to join and ask any questions or seek additional tips and tricks related to my models or AI in general. Your participation would be greatly appreciated.